降维分析
1.降维方法
- 缺失值比率 :该方法的是基于包含太多缺失值的数据列包含有用信息的可能性较少。因此,可以将数据列缺失值大于某个阈值的列去掉。
- 低方差滤波 :该方法假设数据列变化非常小的列包含的信息量少,因此,所有的数据列方差小的列被移除。
- 高相关滤波 :对于数值列之间的相似性通过计算相关系数来表示,对于名词类列的相关系数可以通过计算皮尔逊卡方值来表示。相关系数大于某个阈值的两列只保留一列。同样要注意的是:相关系数对范围敏感,所以在计算之前也需要对数据进行归一化处理。
- 随机森林:我们能够对一个非常巨大的数据集生成多个浅层次的树,每颗树只训练一小部分特征。如果一个特征经常成为最佳分裂属性,那么它很有可能是需要保留的信息特征。
- 前向特征构造 :我们从一个特征开始,每次训练添加一个让分类器性能提升最大的特征。前向特征构造和反向特征消除都十分耗时。它们通常用于输入维数已经相对较低的数据集。
- 反向特征构造 :先用 n 个特征进行训练,每次降维操作,采用 n-1 个特征对分类器训练 n 次,得到新的 n 个分类器。将新分类器中错分率变化最小的分类器所用的 n-1 维特征作为降维后的特征集。
- PCA和SDA是重点讲解的,参见下文。
- 因子分析:假设在观察数据的生成中有一些观察不到的隐变量,而这个观察数据是这些隐变量和噪声的线性组合,那也就是说隐变量的数量小于观测变量,所以只需要找到隐变量就可以进行降维。
2.PCA主成分分析
1.原理
在PCA中,数据从原来的坐标系转换到了新的坐标系,新的坐标系的选择是由数据本身决定的,第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新的坐标轴的选择和第一个坐标轴正交且具有最大方差的方向,该过程一直重复,直到大部分数据方差都包含在了前几个坐标轴内。那如何求方差最大的特征呢?通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值及特征向量,选择特征值最大(也即包含方差最大)的N个特征所对应的特征向量组成的矩阵,我们就可以将数据矩阵转换到新的空间当中,实现数据特征的降维(N维)。
协方差:协方差表示的是两个变量的总体的误差,这与只表示一个变量误差的方差不同。 如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
协方差矩阵:
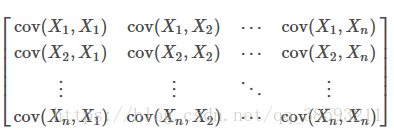
2.优缺点
优点:降低数据复杂性和算法的计算开销,识别重要特征去除噪声。
缺点:不一定需要而且会损失信息。
3.流程:
数据减去平均值
计算协方差矩阵
计算协方差矩阵的特征值和特征向量
将特征值排序
保留前N个最大的特征值对应的特征向量
将数据转换到上面得到的N个特征向量构建的新空间中(实现了特征压缩)4.实现
import numpy as np
# n维的原始数据,本例中n=2。
data = np.array([[2.5,2.4], [0.5, 0.7], [2.2, 2.9], [1.9, 2.2], [3.1, 3.0], [2.3, 2.7],\
[2, 1.6], [1, 1.1], [1.5, 1.6], [1.1, 0.9]])
print(data)
[[2.5 2.4]
[0.5 0.7]
[2.2 2.9]
[1.9 2.2]
[3.1 3. ]
[2.3 2.7]
[2. 1.6]
[1. 1.1]
[1.5 1.6]
[1.1 0.9]]
# 减去均值
def zeroMean(dataMat):
# 求各列特征的平均值
meanVal = np.mean(dataMat, axis=0)
newData = dataMat - meanVal
return newData, meanVal
newData, meanVal = zeroMean(data)
print(newData)
print(newData)
[[ 0.69 0.49]
[-1.31 -1.21]
[ 0.39 0.99]
[ 0.09 0.29]
[ 1.29 1.09]
[ 0.49 0.79]
[ 0.19 -0.31]
[-0.81 -0.81]
[-0.31 -0.31]
[-0.71 -1.01]]
#求协方差矩阵,rowvar=036表示每列对应一维特征
covMat = np.cov(newData, rowvar=0)
print(covMat)
In [5]:
#求协方差矩阵,rowvar=036表示每列对应一维特征
covMat = np.cov(newData, rowvar=0)
print(covMat)
[[0.61655556 0.61544444]
[0.61544444 0.71655556]]
#求协方差矩阵的特征值和特征向量
eigVals, eigVects = np.linalg.eig(np.mat(covMat))
print('特征值为:\n', eigVals)
print('特征向量为\n', eigVects)
print('特征向量为\n', eigVects)
特征值为:
[0.0490834 1.28402771]
特征向量为
[[-0.73517866 -0.6778734 ]
[ 0.6778734 -0.73517866]]
k = 1 #降到一维
eigValIndice = np.argsort(eigVals) # 从小到大排序特征值
n_eigValIndice = eigValIndice[-1:-(k+1):-1] # 取值最大的k个下标
n_eigVect = eigVects[:, n_eigValIndice] # 取对应的k个特征向量
print (n_eigVect)
eigValIndice = np.argsort(eigVals) # 从小到大排序特征值
n_eigValIndice = eigValIndice[-1:-(k+1):-1] # 取值最大的k个下标
n_eigVect = eigVects[:, n_eigValIndice] # 取对应的k个特征向量
print (n_eigVect)
[[-0.6778734 ]
[-0.73517866]]
lowDataMat = newData*n_eigVect #原数据乘以特征向量,低维特征空间的数据
reconMat = (lowDataMat * n_eigVect.T) + meanVal # 重构数据,得到降维之后的数据
print ('降维之后的样本:\n', reconMat)
降维之后的样本:
[[2.37125896 2.51870601]
[0.60502558 0.60316089]
[2.48258429 2.63944242]
[1.99587995 2.11159364]
[2.9459812 3.14201343]
[2.42886391 2.58118069]
[1.74281635 1.83713686]
[1.03412498 1.06853498]
[1.51306018 1.58795783]
[0.9804046 1.01027325]]3.SVD奇异值分解
1.原理
对矩阵做奇异值分解:
上述分解会构建一个矩阵,该矩阵的对角元素被称为奇异值,其他元素为0,U和V是正交矩阵,
,我们只需要根据奇异矩阵按照前k个奇异值的平方和占总奇异值的平方和的百分比percentage来确定k的值。
2.优势
SVD比PCA的优势在哪?特征值的分解是针对可对角化方阵而言,奇异值分解可以对任何方阵。
3.应用:
SVD最广泛的应用就是应用在协同过滤的推荐系统中,简单的推荐系统能够计算项或人之间的相似度,更先进的办法就是利用SVD从数据中构建一个主题空间,然后对每个空间进行计算相似度,以一个菜品推荐系统为例,由于矩阵大部分都是零,所以用SVD压缩菜品(列)。
工作过程:给定一个用户,系统会为此用户返回N个最好的推荐菜。
流程:1.寻找用户没有评级的菜肴,即用户-物品矩阵中为0的项。
2.在用户没有评级的所有物品中,对每个物品预计一个可能的评级分数(相似度得出)。
3.对每个用户的所有物品进行评分,返回最高的N个物品。
实现:
#coding=utf-8
from numpy import *
from numpy import linalg as la
#测试数据集
def loadExData():
return mat([[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]])
#以余弦相似度计算相似度
def cosSim(inA,inB):
num=float(inA.T*inB)
denom=la.norm(inA)*la.norm(inB)
return 0.5+0.5*(num/denom) #将相似度归一到0与1之间
#确定k值即降维之后的特征数量
def sigmaPct(sigma,percentage):
sigma2=sigma**2 #对sigma求平方
sumsgm2=sum(sigma2) #求所有奇异值sigma的平方和
sumsgm3=0 #sumsgm3是前k个奇异值的平方和
k=0
for i in sigma:
sumsgm3+=i**2
k+=1
if sumsgm3>=sumsgm2*percentage:
return k
#svd降维并根绝item与其他的物品的相似度求出它的得分
def svdEst(dataMat,user,simMeas,item,percentage):
n=shape(dataMat)[1]#物品数量
simTotal=0.0;ratSimTotal=0.0
u,sigma,vt=la.svd(dataMat)#分解成三个矩阵
k=sigmaPct(sigma,percentage) #确定了k的值
sigmaK=mat(eye(k)*sigma[:k]) #根据k值构建对角矩阵
xformedItems=dataMat.T*u[:,:k]*sigmaK.I #将原始矩阵进行降维
for j in range(n):
userRating=dataMat[user,j]
if userRating==0 or j==item:continue
similarity=cosSim(xformedItems[item,:].T,xformedItems[j,:].T) #计算物品item与物品j之间的相似度
simTotal+=similarity #对所有相似度求和
ratSimTotal+=similarity*userRating #用"物品item和物品j的相似度"乘以"用户对物品j的评分",并求和
if simTotal==0:return 0
else:return ratSimTotal/simTotal #得到对物品item的预测评分
def recommend(dataMat,user,N=5,simMeas=cosSim,estMethod=svdEst,percentage=0.9):
unratedItems=nonzero(dataMat[user,:].A==0)[1] #建立一个用户未评分item的列表
if len(unratedItems)==0:return 'you rated everything' #如果都已经评过分,则退出
itemScores=[]
for item in unratedItems: #对于每个未评分的item,都计算其预测评分
estimatedScore=estMethod(dataMat,user,simMeas,item,percentage)
itemScores.append((item,estimatedScore))
itemScores=sorted(itemScores,key=lambda x:x[1],reverse=True)#按照item的得分进行从大到小排序
return itemScores[:N] #返回前N大评分值的item名,及其预测评分值
recommend(loadExData(),1,N=5,percentage=0.9)#对编号为1的用户推荐评分较高的5件商品
Out[9]:
[(6, 3.3329499901459845),
(9, 3.331544717872839),
(4, 3.3314474877128624),
(8, 3.326884809845324),
(0, 3.3268283418518467)]