节选整理自:A Survey on Deep Learning-based Fine-grained Object Classification and Semantic Segmentation
细粒度分类综述
细粒度分类:同一类中不同子类物体间的分类。
难点:受视角、背景、遮挡等因素影响较大,类内差异较大、类间差异较小。
基于深度学习的物体分类可以大致分为4类:
- 使用通用DCNN(Deep Convolutional Neural Network,深度卷积神经网络)进行细粒度分类;
- 先使用DCNN进行部件定位,之后进行部位对齐;
- 使用多个DCNN对细粒度识别中的相似特征进行判别;
- 使用注意力模型定位区分性强的区域。
1. 通用的DCNN模型
常见的深度学习网络模型见:基于深度学习的图像语义分割技术概述之背景与深度网络架构
2. 基于部位检测与对齐的方法
部位定位可以建立实体间的对应关系,消除物体姿态、拍摄视角、观测位置等因素的影响。
通常的方法流程:部位定位、部件对齐、物体分类。
2.1 基于部件的R-CNN(Part-based R-CNN)
Part-based R-CNNs for fine-grained category detection
R-CNN通过使用自底向上的区域生成方法及深度卷积特征进行物体检测;
训练过程,训练物体及部件的检测器;
测试过程,生成图像中的候选框,之后使用检测器对候选框进行评分,并且结合非参数化几何约束(non-parametric
geometric constraints)对候选区域进行筛选,选择最好的物体及部件检测结果,之后提取物体及部件的特征并进行姿态归一化,最后,训练一对所有SVM的细粒度分类器。
特点:
- 需要对图像中物体位置及部件位置进行标注。

2.2 基于多候选区集成的部件定位(Part localization using multi-proposal consensus)
Part Localization using Multi-Proposal Consensus for Fine-Grained Categorization
使用基于AlexNet的单个DCNN定位关键点和区域。
将AlexNet最后的fc8层替换为两个产生关键点及视觉特征的输出层。使用边缘框分块(edge box crops)方法将图像分块,之后产生其特征点位置及视觉特征,去除自信度低的预测结果。之后取剩余预测结果的中心点,作为最终关键点预测结果。并使用将部件检测网络中关键点位置的特征,将其拼接,使用200路一对所有SVM分类器进行分类。
2.3 姿态归一网络(Pose normalized nets)
Bird species categorization using pose normalized deep convolutional nets
计算物体姿态的估计,提取图像局部特征,并且将其用于图像细粒度分类。
姿态归一化网络将经过姿态归一化提取的conv5、fc6等底层特征与未对齐的fc8高级特征进行融合。
训练阶段,姿态归一化网络使用DPM预测2D位置及13个语义部位关键点,或者直接使用已提供的物体框及部位标注信息学习姿态原型。将不同的部位图像进行弯曲,并且使用不同的DCNN(AlexNet)提取其特征。最后拼接各个部位及整张图像的特征训练分类器。

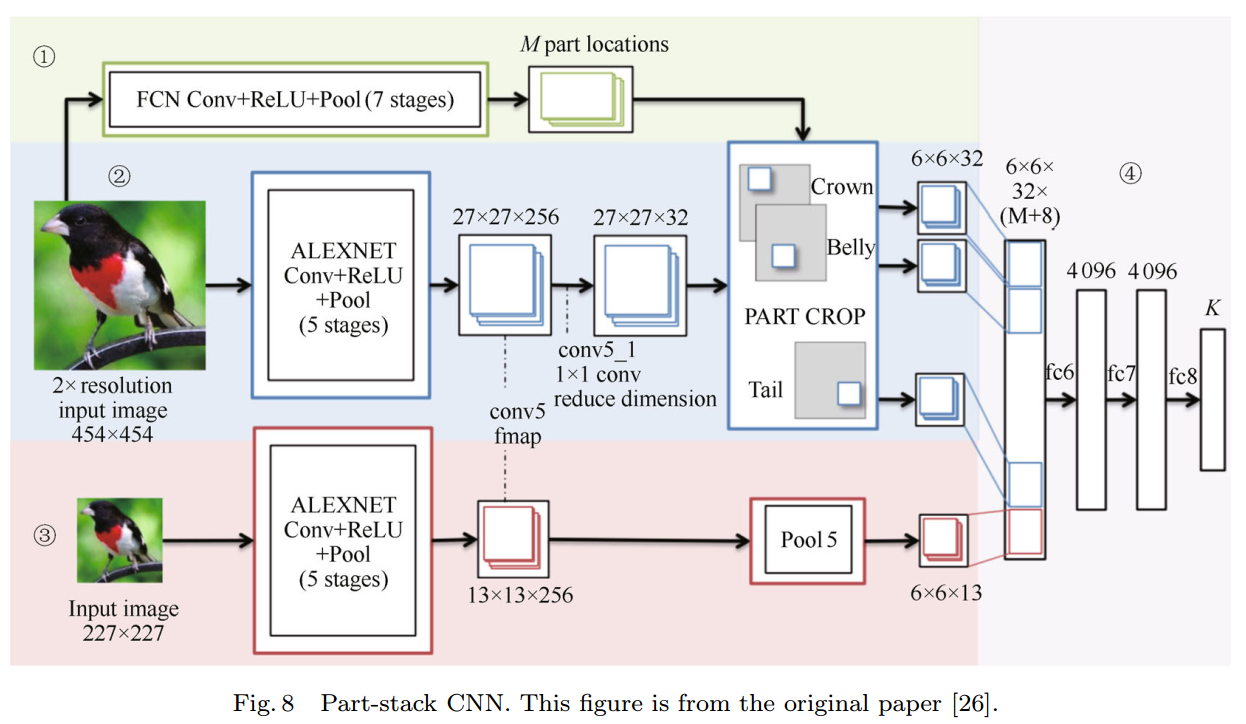
2.4 部件堆积CNN(Part-stack CNN,PS-CNN)
Part-stacked CNN for fine-grained visual categorization
基于人工标记的强部件标注信息,PS-CNN使用全卷积网络进行部件定位和一个双流的分类网络对物体及部件的特征进行编码。
全卷积网络将CNN中的全连接层使用1××1的卷积代替,其输出特征图的维度小于输入图像维度。输出特征图的每个像素点对应输入图像的一个区域,该区域称为其感受野。FCN具有以下优点:1)其特征图可以直接作为部件的定位结果应用于分类网络;2)FCN能够同时得到多部件的定位结果;3)FCN的学习及推理较为高效。
使用FCN得到conv5中M个关键点的位置之后,将定位结果输入到分类网络,使用两级架构分析图像物体级及部件级的特征。
部件级网络首先通过共享层提取特征,之后分别计算关键点周围的部件特征。物体级别网络使用标注框提取对象级CNN特征,及pool5特征。之后将部件级网络及物体级网络特征图合并,进行分类。

2.5 Deep LAC(Location Alignment Classification)
Deep LAC: Deep localization, alignment and classification for fine-grained recognition
Deep LAC在同一个网络中进行部件定位、对齐及分类,提出了VLF(valve linkage function,阀门连接函数)函数,进行Deep LAC中的反向传播,其能够自适应地减小分类及对齐的误差,并且更新定位结果。
部件定位子网络包含5个卷积层及3个全连接层。输出为框的左上角及右下角点的坐标。
对齐子网络接收部件定位结果,执行模板对齐,产生姿态对齐的部件图像。对齐子网络进行平移、缩放、旋转等操作用于姿态对齐区域的生成。同时,该子网络还负责反向传播过程中分类及定位结果的桥接作用。
对齐子网络中的VLF是一个非常关键的模块,优化定位及分类子网络间的连接,协调分类结果与定位结果。使网络达到稳定状态。


3 基于网络集成的方法(Ensemble of networks based approaches)
将细粒度数据集划分为几个相似的子集或直接使用多个神经网络都可以提高细粒度分类的性能。
3.1 子集特征学习网络(Subset feature learning networks)
Subset feature learning for fine-grained category classification
包括通用CNN及特定CNN两个部分。
使用大规模数据集上预训练的通用CNN并在细粒度数据集上迁移学习。同时,在其fc6特征上使用LDA降维。
将细粒度数据集中外观相似的类聚类为K个子类,并训练K个特定的CNN。
在测试时,使用子集CNN选择器(subset selector CNN ,SCNN)选择输入图像相应的子集CNN。SCNN使用K个聚类结果作为类标签,将fc8的softmax输出数量改为K。之后,使用最大投票法确定其子类。


3.2 混合DCNN(Mixture of deep CNN)
Fine-grained classification via mixture of deep convolutional neural networks
MixDCNN不对数据集进行划分,学习K个特定的CNN。输入图像经过K个CNN,K个子CNN的分类结果通过分类占位概率(occupation probability)进行融合,其定义如下,通过占位概率,MixDCNN可以实现端到端训练。
αk=eCk∑Kc=1eCcαk=eCk∑c=1KeCc
其中,CkCk为第K个CNN的最佳分类结果。

3.3 CNN树(CNN tree)
Learning finegrained features via a CNN tree for large-scale classification
在多分类问题中,某个类通常与其他几个类相混淆,这些容易相互混淆的类被称为混淆集。在混淆集中,应该使用判决性更强的特征对其进行区分。
首先在类集合上训练模型,之后评估训练好模型每个类的混淆集,将各类的混淆集合并为几个混淆超集。之后将混淆超集做为子节点,在其上进一步学习,重复该过程,直到CNN树达到最大深度。

3.4 多粒度CNN( Multiple granularity CNN)
Multiple granularity descriptors for fine-grained categorization
子类标签包含某实体在该类中的层次信息。使用这些层次信息可以训练一系列不同粒度的CNN模型。这些模型的内部特征表示有不同的兴趣域,能够提取覆盖所有粒度的判别性特征。
多粒度CNN包含多个CNN,每个CNN都在给定的粒度进行分类。即多粒度CNN是由多个单粒度识别CNN组成。ROI通过自底向上的区域生成方法生成,与粒度相关。同时,ROI的选择是跨粒度相关的,细粒度的ROI通常是由粗粒度的ROI采样而来。之后,将ROI输入到各个粒度的特征提取网络提取其多粒度特征,最后将多粒度特征合并,产生最终的分类结果。

3.5 双线性深度网络(Bilinear deep network models)
Bilinear CNN models for fine-grained visual recognition
4 基于注意力的方法
人类视觉系统存在注意力机制。与将整张图像压缩为一个静态的特征表示不同,注意力机制允许显著特征根据需要动态地到达前端。这在图像中包含多个部分时显得尤为重要。
4.1 两级注意力(Two-level attention)
两级注意力结合了三种类型的注意力:生成候选图像块的自底向上注意力、选择相关块形成特定物体的对象级自顶向下注意力、定位判别性部件的部件级自底向上注意力。通过整合这些类型的注意力机制训练特定的DCNN,以提取前景物体及特征较强的部件。该模型容易泛化,不需要边界框及部件标注。
之后基于FilterNet选择出来的框训练DomainNet。特别地,使用相似矩阵将中间层分为K个簇,簇的作用域部件检测器相同。之后各个簇筛选出的图像块被缩放到DomainNet输入大小,生成其激活值,之后将不同部件的激活值汇总并训练一对多SVM分类器。最终,将物体级与部件级注意力预测结果合并,以利用两级注意力的优势。

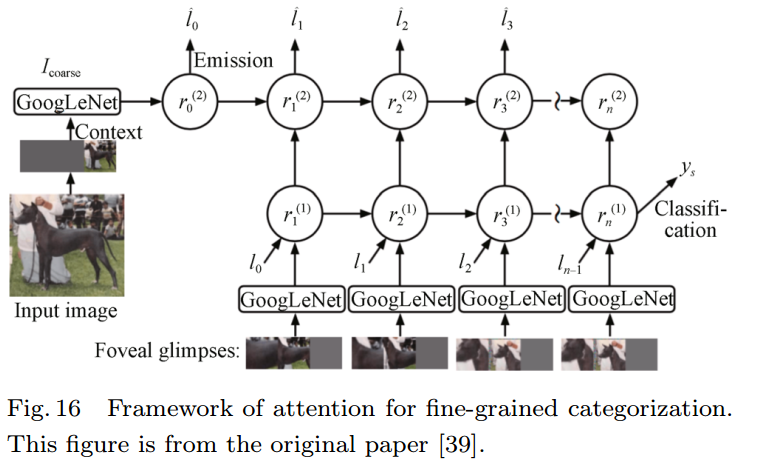
4.2 细粒度分类的注意力(Attention for fine-grained categorization)
Attention for fine-grained categorization
人类在识别时通常不断移动物体以观察相关的特征,并不断将特征添加到图像表征序列中。
AFGC(细粒度分类注意力模型)是一个基于GoogLeNet的RNN( deep recurrent neural network,深度递归神经网络),在每个时间步处理一个多分辨率的图像块。网络使用该图像块更新图像的表征,并与之前的激活值相结合,输出下一注意点的位置或输出物体最终分类结果。

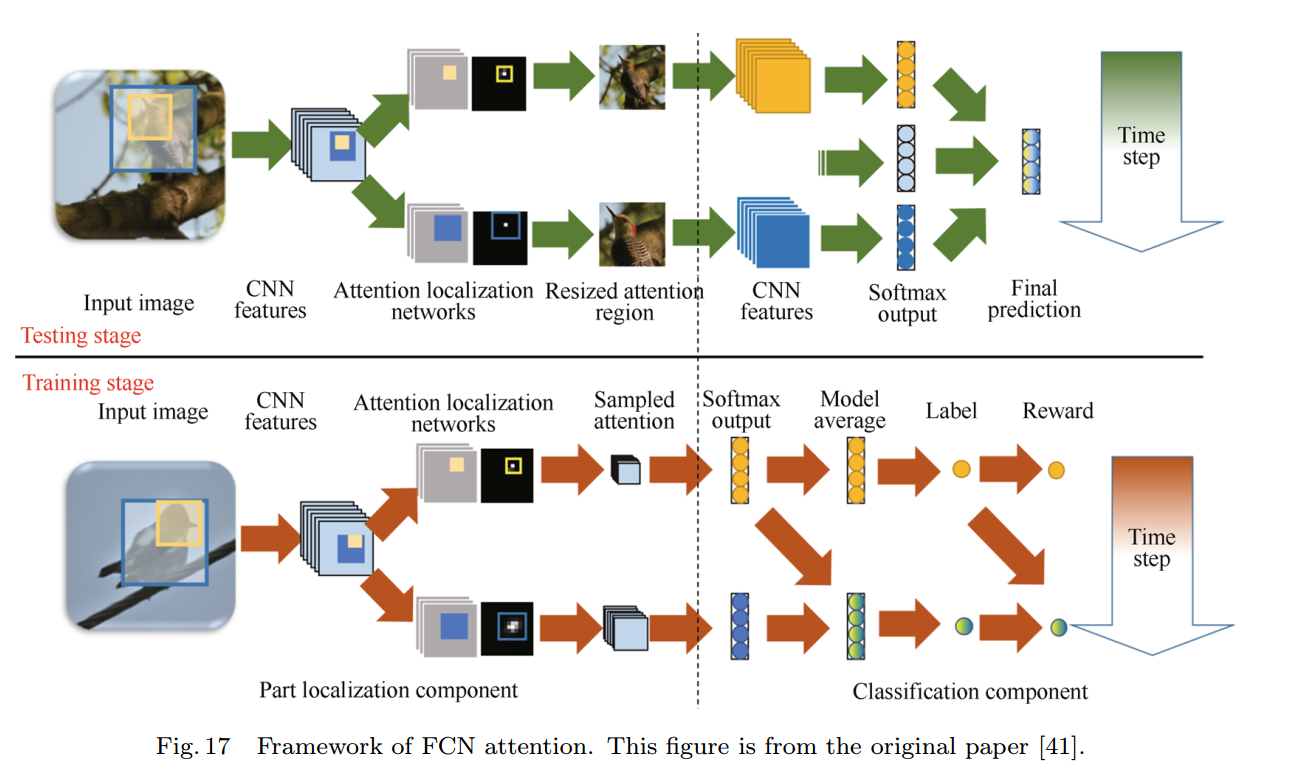
4.3 FCN注意力模型(FCN attention)
FCN attention是基于强化学习的全卷积注意力定位网络,其能够自适应地选择多任务驱动的注意力区域。由于其基于FCN架构,因而更加高效,并且能够对多个物体部件进行定位,同时提取多个注意力区域的特征。其中,不同部件可以有不同的预定义大小。网络共包括局部定位模块和分类模块。
局部定位模块使用全卷积网络进行部件定位,其基于VGG16模型,输出单通道的自信度映射图。自信度最高的区域被选择作为部件位置。每个时间步都生成一个特定的部件位置。
分类模块对所有部件及整张图像进行分类。对局部图像裁剪到模型输入大小,最后取所有部件及全局预测的均值。

4.4 多样化视觉注意力(Diversified visual attention)
Diversified visual attention networks for fine-grained object classification
DVAN(diversified visual attention network,多样注意力网络 )提高视觉注意力多样性以提取最大程度的判别性特征。包括四个部分:注意力区域生成、CNN特征提取、多样性视觉注意力、分类。
对输入图像的区域进行定位,将其作为下一步输入;
使用卷积神经网络学习其特征;
定位重要的块及部件,使用多样性注意力模型组件预测注意力分布。传统注意力模型只关注单个位置,DVAN使用特定的损失函数联合判别多个位置的特征。同时每个时间步都会预测物体类别,最后去预测结果的均值。

5 性能比较及结果分析
文章在CUB200-2011数据集上比较了上述方法的性能,CUB-200-2011数据集包含200种鸟类,共11778张图像,每张图像包括图像级类标签、物体边界框、属性标注及部件位置信息。其中,5994张图像用于训练、5794张图片用于测试。性能测试结果如下图所示。
基于部件定位的细粒度算法能够定位重要的区域,但其需要详细的部位标注信息,较难获取。在只有类别标签的情况下,基于强化学习识别判别性较强区域的方法不能准确识别多个判别性区域。
相比部件标注,属性标注更加节约人力,可以作为部件定位的弱监督学习信息,在一定程度上提高分类准确率。
递归视觉注意力模型能够有效地定位部件、获得判别性强的特征表示。当前注意力模型可以分为软注意力和硬注意力两种。软注意力模型以固定的方式预测注意力区域,能够使用反向传播训练。硬注意力模型随机预测图像中的注意力点,通常通过强化学习或最大化视觉变化下界得到。软注意力模型一般比硬注意力模型更加高效。
