细粒度图像分类问题是计算机视觉领域一项极具挑战的研究课题, 其目标是对子类进行识别,如区分不同种类的鸟。由于子类别间细微的类间差异和较大的类内差异, 传统的分类算法不得不依赖于大量的人工标注信息。近年来, 随着深度学习的发展, 深度卷积神经网络为细粒度图像分类带来了新的机遇。大量基于深度卷积特征算法的提出, 促进了该领域的快速发展。
一 概述
定义
细粒度图像分类(Fine-Grained Categorization),又被称作子类别图像分类(Sub-Category Recognition),是近年来计算机视觉、模式识别等领域一个非常热门的研究课题.。其目的是对粗粒度的大类别进行更加细致的子类划分。细粒度图像的类别精度更加细致,类间差异更加细微,往往只能借助于微小的局部差异才能区分出不同的类别。而与人脸识别等对象级分类任务相比,细粒度图像的类内差异更加巨大,存在着姿态、光照、遮挡、背景干扰等诸多不确定因素。因此,细粒度图像分类是一项极具挑战的研究任务。
研究意义
细粒度图像分类无论在工业界还是学术界都有着广泛的研究需求与应用场景。与之相关的研究课题主要包括识别不同种类的鸟、狗、花、车、飞机等。在实际生活中,识别不同的子类别又存在着巨大的应用需求。例如, 在生态保护中, 有效识别不同种类的生物,是进行生态研究的重要前提。如果能够借助于计算机视觉的技术, 实现低成本的细粒度图像识别, 那么无论对于学术界, 还是工业界而言, 都有着非常重要的意义。
总结
绝大多数细粒度图像分类算法的流程框架:首先找到前景对象(鸟)及其局部区域(头、脚、翅膀等), 之后分别对这些区域提取特征. 对所得到的特征进行适当的处理之后, 用来完成分类器的训练和预测。
1. 细粒度图像的信噪比很小, 包含足够区分度的信息往往只存在于很细小的局部区域中,如何找到并有效利用这些有用的局部区域信息,成为了决定细粒度图像分类算法成功与否的关键所在。
(1)依赖人工标注信息(Annotations)
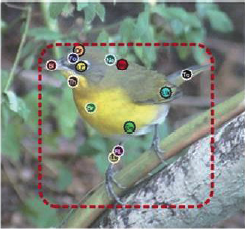
其中主要包括标注框(Bounding Box)和局部区域位置(Part Locations)等.借助于标注框能够完成对前景对象的检测, 从而排除掉背景噪声的干扰; 而局部区域位置则可以用来对一些有用的局部区域进行定位, 或者进行姿态对齐等, 以实现局部特征的提取。
(2)仅仅依靠类别标签(Label)
2. 特征的提取也是决定图像分类准确性的关键因素。
(1)传统的基于人工特征
一般是先从图像中提取SIFT或者HOG这些局部特征, 之后利用VLAD或者Fisher Vector[20][21]等编码模型进行特征编码, 得到最终所需要的特征表示。
(2)基于深度卷积特征
从深度卷积神经网络中所提取的特征, 比人工特征拥有更强大的描述能力, 将深度卷积特征运用到细粒度图像分类任务中, 能够取得更好的结果[25]. 深度卷积特征的加入, 为细粒度图像分类的发展带来了新的机遇,使得其研究进入了一个新的阶段。
二 基于人工特征的早期算法简述
在发布CUB200-2011数据库的技术报告中,Wah等人给出的基准测试的结果仅为10.3%. 他们的方法是: 给定一张原始的、未经过裁剪的测试图像, 利用训练得到的模型完成局部区域的定位; 之后,提取RGB颜色直方图和向量化的SIFT特征, 经过词包(bag of words, BoW)模型进行特征编码后, 输入到线性SVM分类器完成分类。
从分类准确度上来看, 这个结果并不让人满意.一方面, 是由于定位不够准确, 局部区域无法归一化对齐; 另一方面, 则是因为特征的描述能力太弱, 不具备足够的区分度。
尝试与探索
1. Berg等人[26]提出了一种基于局部区域的特征编码方式, 他们称之为POOF特征. 该算法能够自动发现最具区分度的信息, 取得了不错的分类效果。但该算法对关键点的定位精度要求比较高, 如果用精确的标注信息实现定位的话, 能够达到73.3%的准确率, 但如果利用定位算法去确定关键点的话, 则只有56.8%的准确度。
2. 除了特征之外, 也有针对局部区域的算法研究. 如Yao[32]等人, Yang[33]等人均尝试使用模板匹配的方法来减少滑动窗口的计算代价。
3. 也有研究工作[34, 35]尝试将人加入到分类任务中来. 用户通过交互式的询问对答, 完成指定的操作, 如给出关键点, 回答一些简单问题等. 其目的在于使用最少的询问次数, 达到最好的分类精度。
总结
从这一阶段的研究成果上可以看出, 更强大的特征描述和特征编码方式对分类准确度有着显著的影响。其次, 细粒度图像分类有别于其他分类任务的一点就是局部区域的信息是至关重要的。我们也该意识到, 为了实现更精细的局部定位, 很多算法都严重依赖于人工标注信息, 这样的方式在实际应用中存在很大的局限性, 这也是前期研究的一个共性。
三 深度卷积网络概述
再谈
四 强监督的细粒度图像分类研究
所谓强监督的细粒度图像分类算法,是指在模型训练的时候,除了图像的类别标签外,还使用了标注框、局部区域位置等额外的人工标注信息。也有些算法考虑仅在模型训练的时候使用标注信息, 而在进行图像分类时不使用这些信息. 这在一定程度上提高了算法的实用性, 但与只依赖类别标签的弱监督分类算法相比仍有一定的差距。
DeCAF
Donahue[25]等人通过对在ImageNet数据集上所训练得到的卷积网络模型进行分析, 发现从卷积网络中所提取的特征具有更强的语义特性, 比人工特征具有更好的区分度. 他们将卷积特征迁移到其他具体领域的任务中, 如场景识别、细粒度分类等, 均获得了更好的分类性能, 从实验上证明了卷积特征强大的泛化性. 他们称之为DeCAF特征(Deep Convolutional Activation Feature).
具体而言, 首先使用标注框对图像进行裁剪,得到前景对象, 再利用预训练的卷积网络对图像提取DeCAF特征. 在文献[25]中, 他们提取的是第6层网络特征, 即第一个全连接层的输出, 之后训练一个多类别的逻辑回归(Logistic Regression)模型来进行图像分类。
总的来说, DeCAF是比较前期的工作, 并不是专门针对细粒度图像分类所优化设计的算法, 其目的在于解释卷积特征的强大泛化性与领域自适应性。DeCAF的出现, 在卷积特征与细粒度图像分类之间搭起了一座桥梁, 具有十分重要的意义。
Part R-CNN
对于细粒度图像分类而言, 图像的局部信息是决定算法性能的关键所在. 对图像进行检测, 并提取出重要的局部信息是大多数细度图像分类算法所采用的基本流程.基于这种观点, Zhang等人提出了Part R-CNN[43]算法,该算法采用了R-CNN[44]对图像进行检测。
Part R-CNN就是利用R-CNN算法进行对象(鸟)与局部区域(头、身体等)的检测, 下图给出了其总体的流程图。
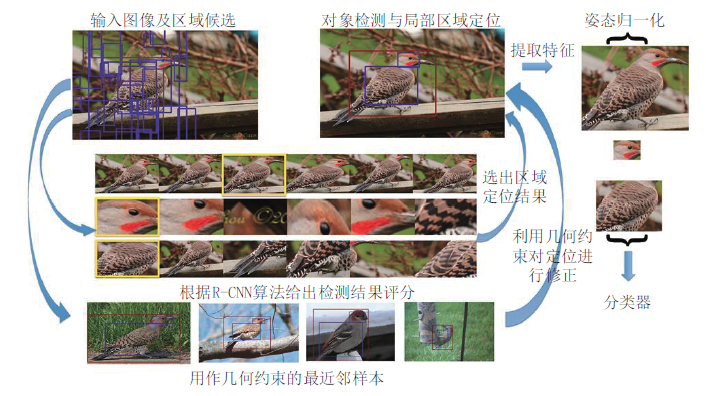
同R-CNN一样, Part R-CNN也使用自底向上的区域算法(如Selective Search[47])来产生区域候选, 如上图左上角所示. 之后, 利用R-CNN算法来对这些区域候选进行检测, 给出评分分值. 在这里, Part R-CNN只检测前景对象(鸟)和两个局部区域(头、身体). 之后, 根据评分分值(图4中间)挑选出区域检测结果(见上图上方中间). 但Zhang等人认为, R-CNN给出的评分分值并不能准确地反映出每个区域的好坏.例如, 对于头部检测给出的标注框可能会在对象检测的标注框外面, 身体检测的结果与头部检测的结果可能会有重叠等. 这些现象都会影响最终的分类性能. 因此, 需要对检测区域进行修正。
利用约束条件对R-CNN检测的位置信息进行修正之后, 再分别对每一块区域提取卷积特征, 将不同区域的特征相互连接起来, 构成最后的特征表示, 用来训练SVM分类器。
总结
Part R-CNN的进步是明显的. 从局部区域的检测定位, 到特征的提取, 该算法均基于卷积神经网络, 并针对细粒度图像的特点进行改进优化, 以改进通用物体定位检测算法在该任务上的不足, 达到了一个相对比较高的准确度. 同时,该算法进一步放松了对标记信息的依赖程度, 在测试时无需提供任何标记信息, 大大增强了算法的实用性. 其不足之处在于, 利用自底向上的区域产生方法, 会产生大量无关区域, 这会在很大程度上影响算法的速度. 另一方面, 该算法本身的创新性十分有限, 既然局部区域对于细粒度图像而言是关键所在, 那么对其进行定位检测则是必要的途径. 只是引入现有的通用定位算法, 似乎并不能很好地解决该问题。
姿态归一化CNN(Pose Normalized CNN)
巨大的类内方差会对最终的分类性能造成很大的影响.而在这些不同的干扰信息中, 姿态问题则是一个普遍存在的影响因素. 有鉴于此, Branson等人提出了姿态归一化CNN(Pose Normalized CNN)算法[48]. 所采取的方案是: 对于每一张输入图像, 利用算法完成对局部区域的定位检测, 根据检测的标注框对图像进行裁剪, 提取出不同层次的局部信息(鸟, 头部),并进行姿态对齐操作. 之后, 针对不同部位的局部信息, 提取出不同层的卷积特征. 最后, 将这些卷积特征连接成一个特征向量, 进行SVM的模型训练, 达到了75.7%的分类精度. 其具体流程如下图所示。
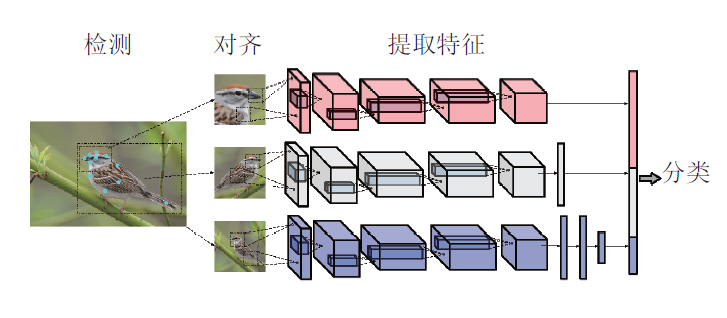
整个算法流程中, 首先要解决的就是如何检测局部区域的问题. 对于输入图像, Branson等人利用预先训练好的DPM算法[49]完成关键点的检测. DPM算法能够给出预先定义好的关键位置点的坐标, 以及该点是否可见等信息. 之后, 利用这些关键点进行姿态对齐操作。
总结
姿态归一化CNN的创新之处在于使用原型对图像进行了姿态对齐操作, 并针对不同的局部区域提取不同网络层的特征, 以试图构造一个更具区分度的特征表示. 它在原有的局部区域模型的基础上, 进一步考虑了鸟类的不同姿态的干扰, 减轻了类内方差造成的影响, 从而取得了较好的性能表现. 但是, 该算法对于关键点的检测精度较为敏感, 利用DP算法对关键点进行检测, 其精度为75.7%。
五 弱监督的细粒度图像分类研究
两级注意力(Two Level Attention)算法
Xiao等人提出的两级注意力(Two Level Attention)算法[56]是第一个尝试不依赖额外的标注信息, 而仅仅使用类别标签来完成细粒度图像分类的工作。该模型主要关注两个不同层次的特征, 分别是对象级(Object-Level)和局部级(Part-Level), 即在以往强监督工作中所使用的标注框和局部区域位置这两层信息。
总结
总体上来看, 两级注意力模型较好地解决了在只有类别标签的情况下, 如何对局部区域进行检测的问题. 但是, 利用聚类算法所得到的局部区域, 准确度十分有限. 在同样使用Alex Net的情况下, 其分类精度要低于强监督的Part R-CNN算法。
双线性CNN(Bilinear CNN)
Lin[13]等人设计了一种新颖的网络模型双线性CNN(Bilinear CNN),在CUB200-2011数据集上实现了84.1%的分类精度.其网络结构如下图所示。
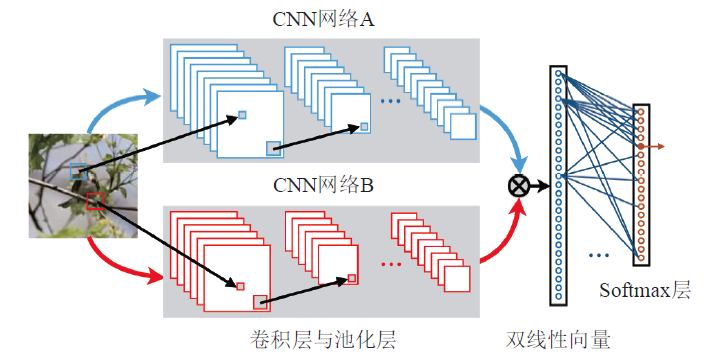
一种对双线性CNN模型的解释是, 网络A的作用是对物体进行定位, 即完成传统算法的对象与局部区域检测工作, 而网络B则是用来对网络A检测到的物体位置进行特征提取. 两个网络相互协调作用, 完成细粒度图像分类过程中两个最重要的任务: 区域检测与特征提取。