版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_28788687/article/details/78088969
数组和链表
基于数组的实现方式,使得我们可以在常数时间内,通过下标完成相应的操作。但对于插入,删除操作,相对于链表的常数时间,数组却显得有点不能让我们满足它的效率.
二叉树的前序遍历
<1>按一定的次序,对所有节点进行有且只有一次的访问。
<2>相对于之前的线性结构,树形的非线性结构,却可以给我们带来更高的效率.值得强调的是只有加上一定的限制(如遍历),我们也不难得到一种线性结构。前序遍历算法的基本思路
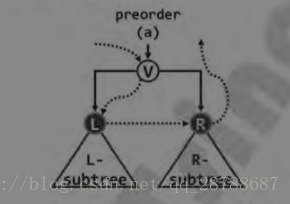
得益于树的递归定义,我们不难的到如下的一种遍历规则,我们将 一棵树分为根节点, 左子树, 右子树.访问根节点后,访问左节点,在访问右子树。
值得一提的是,当我们访问图中L节点后并不是真正像上图一样直接访问其兄弟节点R节点。
原因如下:- 图中L节点有着两种身份,一是充当节点V的左子树中的一个节点,二是充当左子树的根节点。当算法进行到图中L节点时,节点L可视为根节点,因此我们”不得不“对节点L进行我们上面所定义的访问规则。
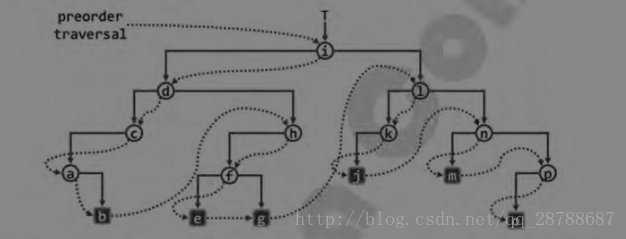
实际访问次序如下所视:
访问完d节点后,我们不是直接访问l节点,而是访问d的左右子树.
- 算法基本实现
void PreVisit( Root T )
{
if( T )
{
printf("%d ",T ->data);
PreVisit( T ->left );
PreVisit( T ->right );
}
return;
}
- 算法分析:我们要访问每一个节点,因此不难得到时间复杂度为O( n );
- 算法改进
- 算法在时间复杂度以达到最优,因此我们思考的重点应该是如何在常系数方面改进算法.一种可行方案是考虑到上述算法是一个递归算法,因此我们可以将其转换为非递归算法。
- 基于消除尾递归的非递归算法1
void PreVisit( Root T )
{
PtrTreeNode t = NULL;
if( T == NULL ) return ;
Push( T);
while( !Isempty() ){
t = Pop();
printf("%d ",t ->data );
if( t ->right ) Push( t ->right );//将右节点压栈
if( t ->left ) Push( t ->left );//将左节点压栈
}
}
值得注意的一点是:
这里与之前的递归算法存在一定的差异。差异体现在,我们先将根节点的右孩子(非空)压栈,再将根节点的左孩子(非空)压栈。但栈具有先进后出(FILO—First-In/Last-Out)的特点。这样看似右节点要左节点之前访问,却因为栈的这一特性使得这一算法可以按照先左后右的顺序进行遍历。
- 非递归算法2
- 观察本文前序遍历算法的基本思路中第二幅图,不难发现,前序算法存在一定的“局部性”。
- 对于任意节点,其之后的访问路径不免可以总结为下列两个过程
- 沿着左侧路径一直向下访问各个节点
- 至底向上遍历对应的右子树
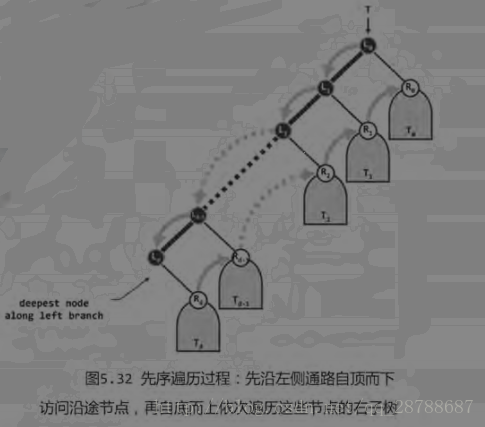
考虑到对于任意节点,我们均要沿其左路径向下,那么我们如何确保我们向上访问右子树时,我们还能找到右子树呢?观察到先访问节点的右子树,反而没有其左路径上节点的右子树访问的早。
综上,选择栈来存储相关节点的右子树相关信息,仿佛是最好的方式。
- 具体代码
void PreVisit( Root T )
{
PtrTreeNode t = T;
while( TRUE ){
//访问左路径
while( t != NULL )
{
printf("%d ",t ->data);
//暂时储存右子树信息
Push( t ->right );
t = t ->left;
}
if( Isempty() ) return;
//开始访问右子树
t = Pop();
}
}