原题链接:https://leetcode-cn.com/problems/binary-tree-preorder-traversal/description/
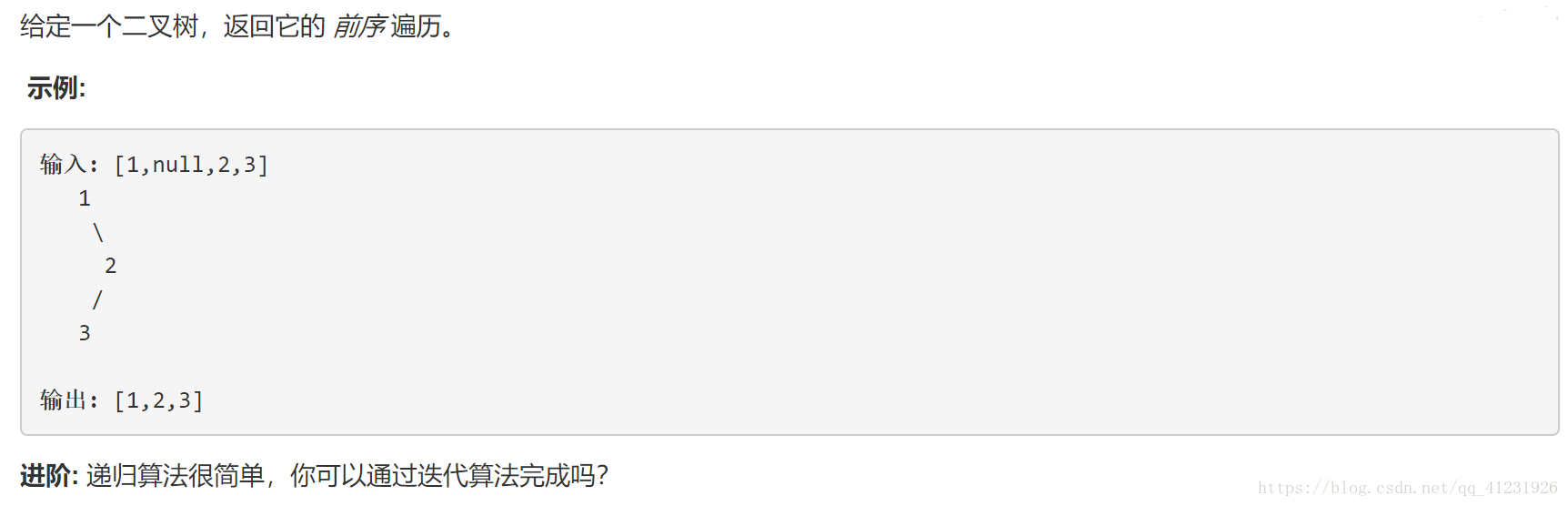
题目描述:
知识点:二叉树、前序遍历、递归
思路一:递归实现
学过数据结构的人都知道,二叉树天然的具有递归性质,因为二叉树的定义就是用递归的形式定义的。因此,在前序遍历二叉树的时候我们完全可以采用递归算法。
所谓前序遍历,就是在第一次访问该节点的时候就记录该节点的值,再依次去访问该节点的左孩子和右孩子。
由于要遍历每一个节点,这样实现的时间复杂度是O(n)级别的,其中n为二叉树中的节点个数。而对于空间复杂度,由于递归存在对系统栈的调用,而这里递归层数就是树的高度,因此空间复杂度是O(h)级别的,其中h为树的高度。
JAVA代码:
public class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
preorderTraversal(root, list);
return list;
}
private void preorderTraversal(TreeNode root, List<Integer> list) {
if(root == null) {
return;
}
list.add(root.val);
preorderTraversal(root.left, list);
preorderTraversal(root.right, list);
}
}
LeetCode解题报告:
思路二:模拟系统栈的递归过程
在我们思路一的实现中,我们利用递归的性质实现了二叉树的前序遍历,其实本质上是利用了系统栈后进先出的性质。
那么如果我们自己创建一个栈来模拟系统栈的全过程呢?那么我们也就不需要用到递归这个方法,我们完全可以用非递归的形式来实现我们的思路。注意这里入栈的顺序应该是先访问当前节点的右孩子,再访问其左孩子,最后记录当前节点的值。
其实这个思路和思路一本质上是一模一样的,只不过思路一中使用的是系统栈,而思路二中使用的是我们自定义的栈。因此时间复杂度为O(n),其中n为二叉树中的节点个数。空间复杂度为O(h),其中h为树的高度。
JAVA代码:
public class Solution {
private class Command {
String s;
TreeNode treeNode;
public Command(String s, TreeNode treeNode) {
this.s = s;
this.treeNode = treeNode;
}
}
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
Stack<Command> stack = new Stack<>();
stack.push(new Command("go", root));
while(!stack.isEmpty()) {
Command command = stack.pop();
if("visit".equals(command.s)) {
list.add(command.treeNode.val);
}
if("go".equals(command.s) && command.treeNode != null) {
stack.push(new Command("go", command.treeNode.right));
stack.push(new Command("go", command.treeNode.left));
stack.push(new Command("visit", command.treeNode));
}
}
return list;
}
}LeetCode解题报告:

思路三:教科书上的经典非递归前序遍历实现——利用栈替代系统栈的功能
这个实现思路其实很简单,就是单纯地利用栈的后进先出性质,达到先访问当前节点的值,再访问右孩子,最后访问左孩子。注意,在Java中,一个Stack中入栈一个null元素,这个Stack就不为空了。因此,我们在根节点入栈前要判断一下根节点是否为空。
同样需要遍历每一个节点,时间复杂度为O(n),其中n为二叉树中的节点个数。空间复杂度为O(h),其中h为树的高度。
JAVA代码:
public class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) {
return list;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while(!stack.isEmpty()) {
TreeNode treeNode = stack.pop();
list.add(treeNode.val);
if(treeNode.right != null) {
stack.push(treeNode.right);
}
if(treeNode.left != null) {
stack.push(treeNode.left);
}
}
return list;
}
}LeetCode解题报告:
思路四:模拟手工计算前序遍历的过程,用栈来记录之前遍历过的节点
我们手动计算前序遍历结果的时候的思路是设立一个指向根结点的指针,该指针一直往其左孩子方向走,一直走到头,然后再返回其父节点,再访问该父节点的右孩子。我们手动计算的时候很容易能看出一个节点的父节点是什么,但对于我们程序而言,只能通过父节点找到子节点,却不能通过子节点来找到其父节点。因此,我们需要用一个栈来记录我们之前访问过的节点在哪里。
同样需要遍历每一个节点,时间复杂度为O(n),其中n为二叉树中的节点个数。空间复杂度为O(h),其中h为树的高度。
JAVA代码:
public class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) {
return list;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
while(cur != null || !stack.isEmpty()) {
while(cur != null) {
list.add(cur.val);
stack.push(cur);
cur = cur.left;
}
cur = stack.pop();
cur = cur.right;
}
return list;
}
}LeetCode解题报告:

思路五:Morris遍历
前面介绍的思路一到四,其时间复杂度都是O(n),n为树的节点数。空间复杂度都是O(h),其中h为树的高度。由于我们每一次遍历肯定要访问到每一个节点,对于时间复杂度而言,我们已经没有了优化的空间。那么,对于空间复杂度,我们能否做进一步的优化呢?这就是Morris遍历所要做的事。
本博文对于Morris前序遍历的介绍极大程度上参考了该博主的博文:http://www.cnblogs.com/AnnieKim/archive/2013/06/15/morristraversal.html。
在思路四中,我们利用栈来保存某一节点的父节点在哪里。如果要使用O(1)空间进行遍历,那么我们肯定不能用栈作为辅助空间。所以这个问题最大的难点在于,遍历到子节点的时候怎样重新返回到父节点。在Morris遍历中利用叶子节点中的左右空指针指向前序遍历下的前驱节点或后继节点。
步骤如下:
(1)如果当前节点的左孩子为空,则访问当前节点的值并将其右孩子作为当前节点。
(2)如果当前节点的左孩子不为空,在当前节点的左子树中找到当前节点在前序遍历下的前驱节点。
a.如果前驱节点的右孩子为空,将它的右孩子设置为当前节点,访问当前节点的值,并且将当前节点更新为当前节点的左孩子。
b.如果前驱节点的右孩子为当前节点,将它的右孩子重新设为空,并且将当前节点更新为当前节点的右孩子。
(3) 重复以上(1)、(2)直到当前节点为空。
Morris遍历真的这么完美吗?
在算法领域,有得必有失。时间性能的优化往往伴随着额外的空间开支,而空间性能的优化往往伴随着时间性能的损耗增大。那么具体对于Morris遍历而言呢?下面我们通过一个具体的例子来说明。
我们对下图所示的二叉树进行前序遍历。
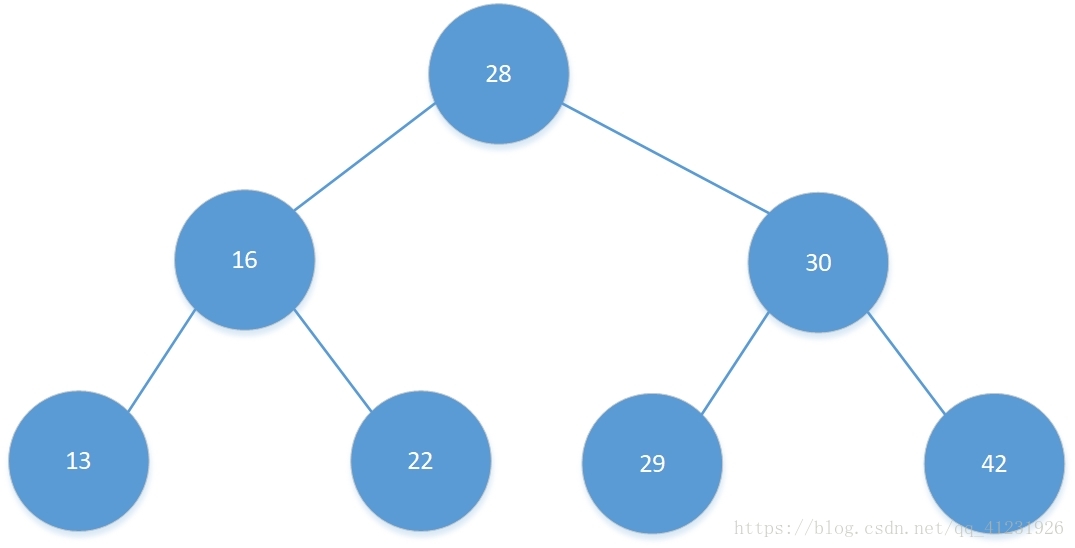
思路一~思路四实现的前序遍历过程:

由于我们用的是一个栈来记录所有节点的前驱节点的位置,所以对于每一次寻找下一个遍历的点,其实只有一步。这个图中总共有7个点,就是6步路。
Morris前序遍历过程:
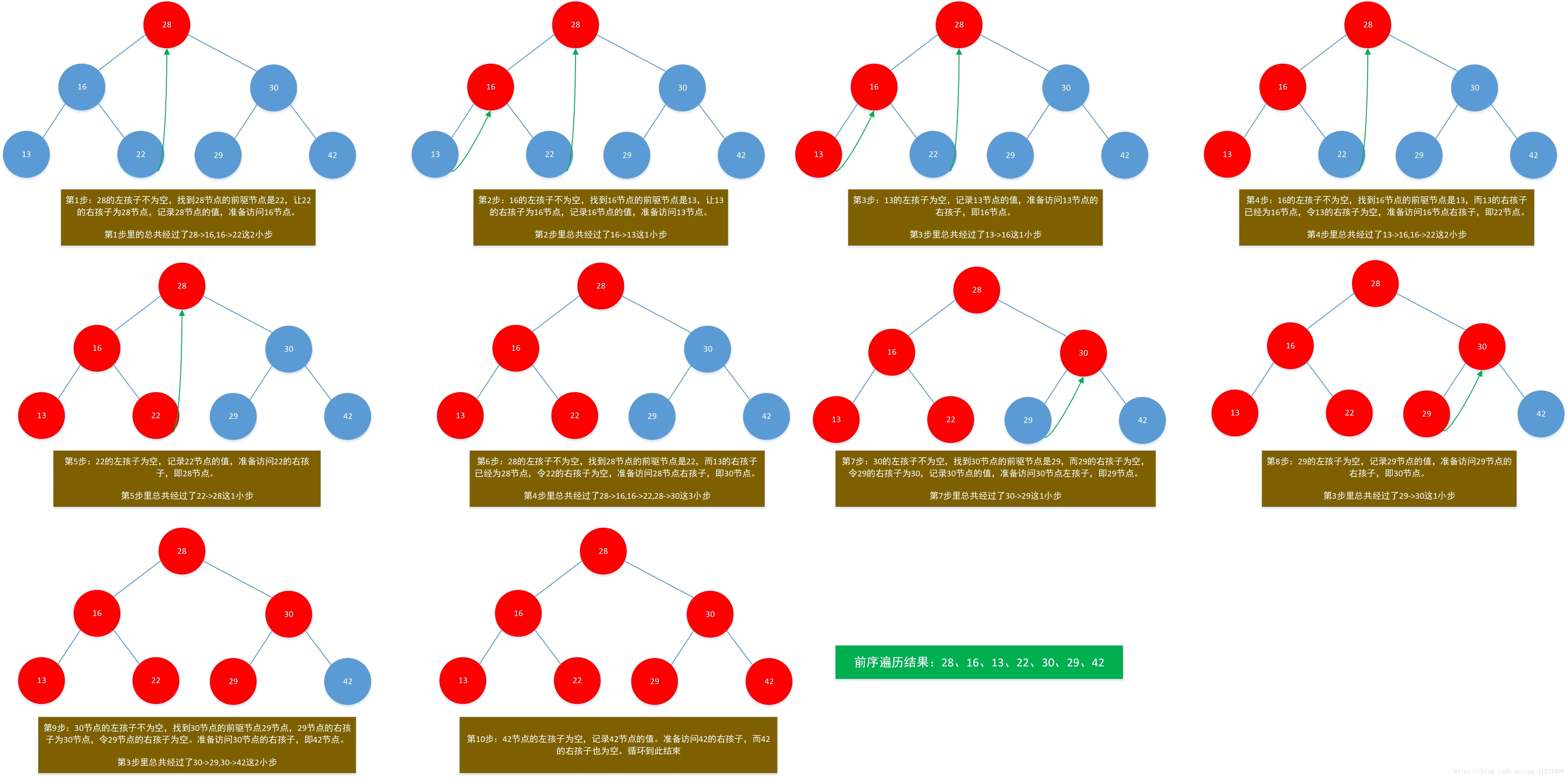
从Morris遍历的过程中我们就可以看出来,对于一些点是遍历了两次的,比如第2步中有16->13这个过程,而第3步就中出现了13->16这个过程。原因在于Morris遍历为了找到子节点的父节点,必然要有从子节点逆向寻找父节点这个过程。
因此,虽然Morris遍历也是O(n)级别的时间复杂度,但其实是比思路一~思路四的实现要慢的。
Morris遍历正是牺牲了时间性能来换取空间性能的提高!
JAVA代码:
public class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) {
return list;
}
TreeNode cur = root;
while(cur != null) {
if(cur.left == null) {
list.add(cur.val);
cur = cur.right;
}else {
TreeNode prev = cur.left;
while(prev.right != null && prev.right != cur) {
prev = prev.right;
}
if(prev.right == null) {
prev.right = cur;
list.add(cur.val);
cur = cur.left;
}else {
prev.right = null;
cur = cur.right;
}
}
}
return list;
}
}LeetCode解题报告: