探秘算法世界,求索数据结构之道;汇集经典问题,畅享编程技法之趣;点拨求职热点,敲开业界名企之门。
特别提醒:本书读者群已经解散,需要源代码的读者请直接到企鹅群(155911675)中找店小二。源码仅供已经购买了《算法之美》一书的读者参考学习,尚未购书者勿扰!
内容简介:本书围绕算法与数据结构这个话题,循序渐进、深入浅出地介绍了现代计算机技术中常用的四十余个经典算法,以及回溯法、分治法、贪婪法和动态规划等算法设计思想。在此过程中,本书也系统地讲解了链表(包括单向链表、单向循环链表和双向循环链表)、栈、队列(包括普通队列和优先级队列)、树(包括二叉树、哈夫曼树、堆、红黑树、AVL树和字典树)、图、集合(包括不相交集)与字典等常用数据结构。同时,通过对二十二个经典问题(包括约瑟夫环问题、汉诺塔问题、八皇后问题和骑士周游问题等)的讲解,逐步揭开隐匿在数据结构背后的算法原理,力图帮助读者夯实知识储备,激活思维技巧,并最终冲破阻碍编程能力提升的重重藩篱。


近日,该书繁体中文版已成功登陆台湾地区,由博硕文化股份有限公司出版发行,并承蒙廖信彦先生审校。售价为650元新台币(约 RMB 150元左右)。该书亦是本人第二部在宝岛台湾出版发行的著作。如果你有购买该书,竭诚欢迎你加入读者交流群,不仅可以方便代码下载、答疑解惑,更可与其他读者一道学习,跳出闭门造车的困境,加速提升学习效果!
本书涉及的45个算法:
BF算法、MP算法、KMP算法、BM算法、BMH算法、Needleman-Wunsch算法、Smith-Waterman算法、N-gram算法、Soundex算法、Phonix算法、二分查找算法、欧几里得算法、二叉树遍历算法、哈夫曼算法、广度优先遍历算法、深度优先遍历算法、Dijkstra算法、Floyd算法、最短路径的动态规划算法、Kruskal算法、Prim算法、AVL树旋转算法、红黑色的操作算法、直接定址法、除留余数法、平方取中法、乘余取整法、折叠法、BKDR散列算法、RS散列算法、FNV散列算法、线性探查法、二次探查法、双重散列法、并查集的路径压缩算法、直接插入排序算法、二分插入排序算法、希尔排序算法、鸡尾酒排序算法、冒泡排序算法、快速排序算法、归并排序算法、堆排序算法、计数排序算法、排序算法。
以及22个经典问题:
Z字形编排问题、大整数乘法问题、九宫格问题、约瑟夫环问题、魔术师发牌问题、拉丁方阵问题、维吉尼亚加密问题、括号匹配问题、停车场模拟问题、舞伴问题、杨辉三角问题、迷宫问题、八皇后问题、骑士周游问题、传染病问题、汉诺塔问题、文字游戏问题、游程编码问题、旅游交通路线问题、道路修建问题、拼写检查问题、犯罪团伙问题。
主页君将不时在该博客发布相关学习资料(例如Leetcode上类似题目的解析等),读者也可同时加入算法之美学习交流群(该群仅限已购书之读者交流所用,我会不定期在其中分析一下资料,同样包含算法和数据结构方面的资料,本书中的代码也可以在该群中获取)。
本书附录中笔试面试题目的参考答案链接
算法之美一书附录中笔试面试题目参考答案
http://blog.csdn.net/baimafujinji/article/details/50484683
勘误表(不断更新中)
1、第25页第3段第4行“每个int型变量占4 bit",应该改为”4 byte“ (新版书中已经更正)
2、第62页,图3-1中字符串的结尾应该是“\0”,书中误写成了“\n”,文字中描述是正确的。(新版书中已经更正)
3、第65页 String析构函数前面应该加“~” (新版书中已经更正)
4、第232页第5行第3个逗号后面,(G1)={<1,2>,<2,1>,E<2,3>,<2,4>.....}印刷错误,应该改为:E(G1)={<1,2>,<2,1>,<2,3>,<2,4>.....} (新版书中已经更正)
5、第49页,原文“如果二维数组中的元素matrix[i][j]中纵坐标i是奇数”,应该改为“如果二维数组中的元素matrix[i][j]中横坐标i是奇数”
6、第69页,原文“p0p1p2p3≠p1p2p3p4”,应该改为“p0p1p2p3≠p2p3p4p5”。
7、第300页,代码中“AvlNode():left(NULL),right(NULL),balance(0){};”应该改为“AvlNode():leftChild(NULL),rightChild(NULL),balance(0){};”
8、第191页,存在印刷错误,原文如下

改正之后的内容应该是

9、第206页,原文“节点D仅有左子节点,而没有右兄弟节点,所以访问它的左子节点F。
节点F同样仅有左子节点,没有右兄弟节点,同样访问它的左子节点H”
应该改为:“节点D仅有左子节点,而没有右兄弟节点,所以访问它的左子节点G。
节点G同样仅有左子节点,没有右兄弟节点,同样访问它的左子节点H”
10、第119页,代码注释部分:
“//前缀运算符,先返回cur 所指向节点中的数据,再使cur向后移动”
应该改为:“//前缀运算符,先使cur 向后移动一个节点,再返回cur所指向节点中的数据”
相应地,还有:“后缀运算符,先使cur 向后移动一个节点,再返回cur所指向节点中的数据”
应该改为:“后缀运算符,先返回cur 所指向节点中的数据,再使cur向后移动”
11、第213页,
“对树的二叉树表示进行先根次序遍历的结果与对应二叉树的前序遍历结果相同。
对树的二叉树表示进行后根次序遍历的结果与对应二叉树的中序遍历结果相同。”
应该改为:
“对树进行先根次序遍历的结果与对应二叉树的前序遍历结果相同。
对树进行后根次序遍历的结果与对应二叉树的中序遍历结果相同。”
12、第56页,2.4.2中第一段,第三行,
"它的危险首先原自" 应该改为 “它的危险首先源自”。
13、第383页,图11-3和图11-4排反了,应该将两幅图对调。
14、图3-9所示的一步有误,此时P串应该移动4位。关于MP算法的解释可以参考:http://pan.baidu.com/s/1c2NDoVQ
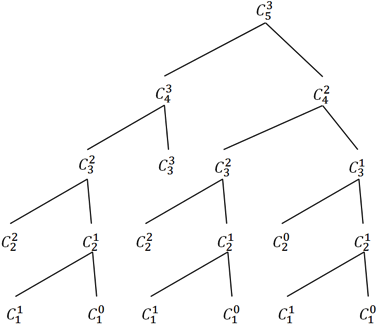
15、第1章,第15页,图1-3 中第递归树画的有问题:第3层最左边节点C33不应该有子树,而应该是其相邻节点C32有子树。下图是修改后的正确结果:
---------------------------------------------------------------------------------------------------------------------------------------------------
关于读者留言的一个答复:
今天有读者在留言中指出书中某处代码似乎有问题,于是乎我重新执行了代码。(当然,我并没有直接检视我的源码是否有逻辑错误,不管怎样我还是有必要把程序执行一下看看~)但是确实没有发生读者所指出的情况,如果这位读者有兴趣欢迎继续钻研,最好能刨根问底挖出为什么在我这可以执行的很好(其他看到此贴的读者也可以参与讨论)。但是,在这个问题被彻底搞清楚之前,我并不能“承认”这个错误,毕竟它在我这里仍然执行得很正常。为了证明我这里执行的结果确实可以如我所说的那样(并排除我们所使用complier本身有bug或者差异这种看似概率很小的事件所带来的影响),下面的截图我使用的是遵循最新C++标准的一个online complier,所以任何人都可以在线使用这个编译器来验证我下面截图所给出的结果。online complier 网址—— http://cpp.sh
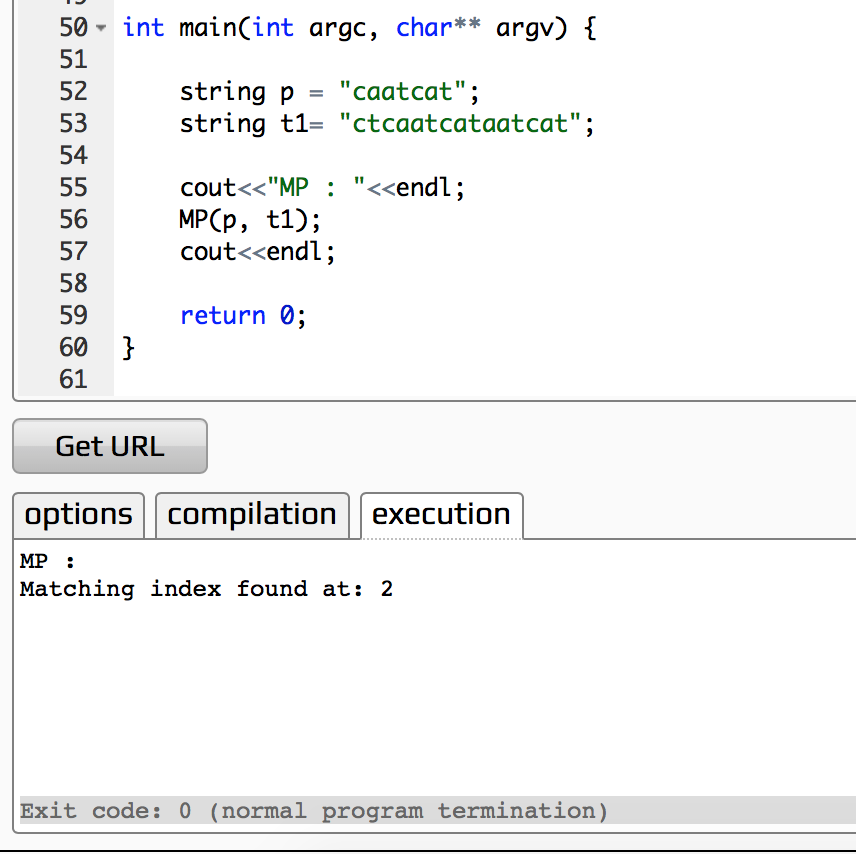
首先我们还是来比较读者给出的那个字符串
string p = "caatcat";
string t1= "ctcaatcataatcat";
下图是我书中所使用的函数
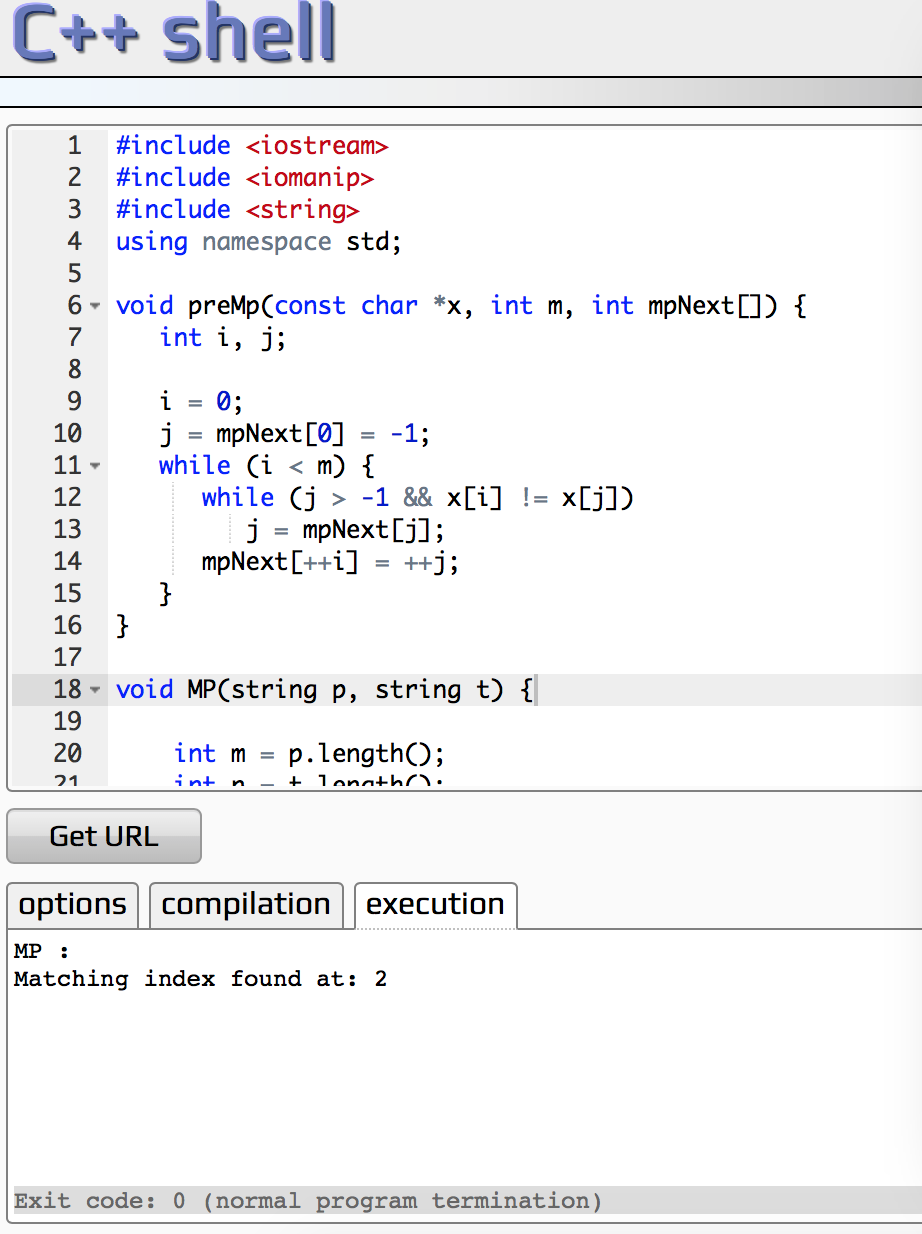
下面是main函数和执行结果(其实上面已经给出)
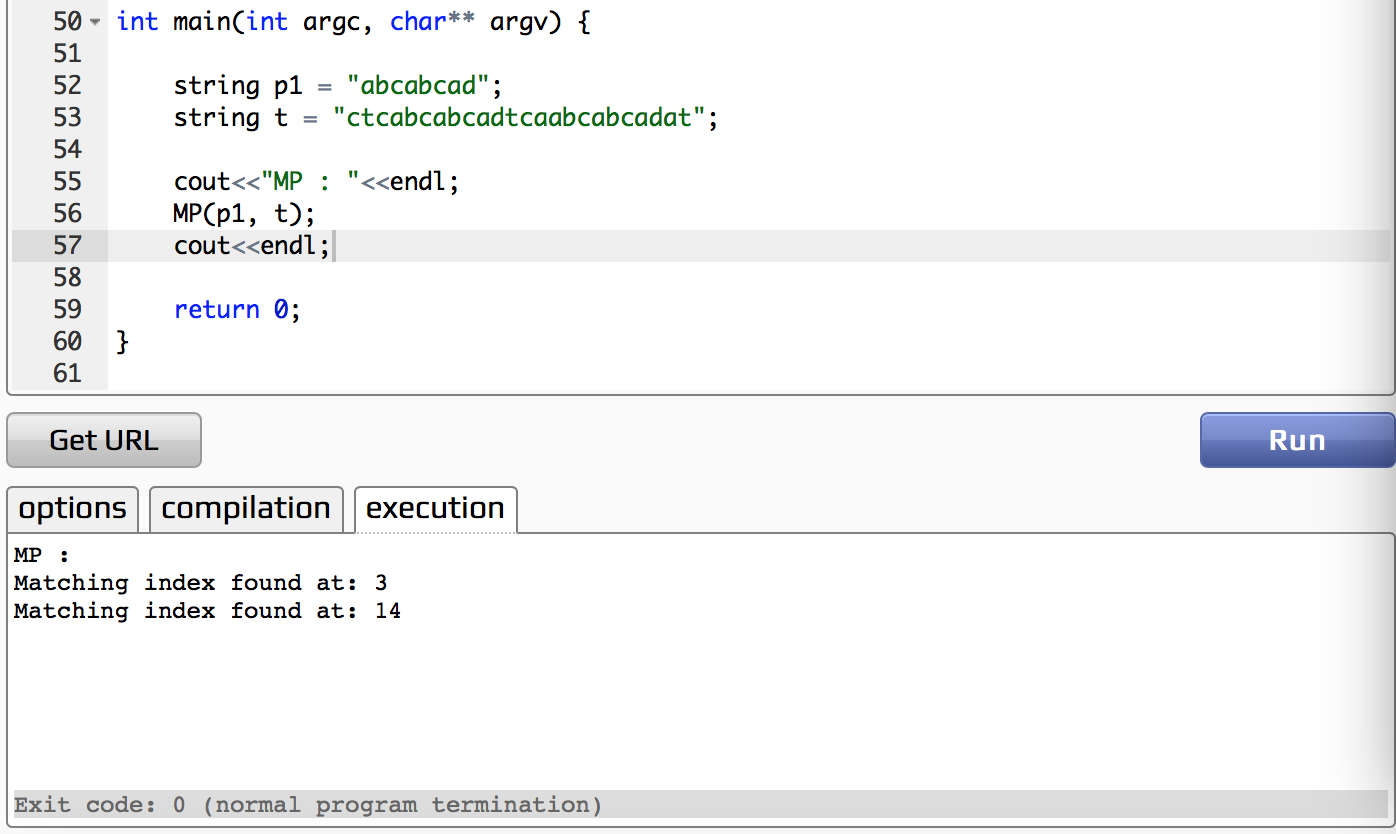
One Extra Sample 来自我发布(在博客上)的测试程序
以及编译器的一些基本配置:

----------------------------------------------------------------------
补充我的三点看法:
1)金无足赤,人无完人。连大神Knuth的书也有错误(据说他会给每找出他一个错误的人256美分作为奖励)。我确信《算法之美》并不完美,但是我一直都以一种相当认真的态度来对待它。特别地,我希望可以通过有奖捉虫的活动来不断完善它。事实上,我已经发现了几处错误,但我并没有把它们加入到勘误表中,就是希望给参与活动的读者留一些机会:)
2)挑错误的技巧和与人分享的精神。如果你觉得书中哪里是错误的,那么指出错误的正确方式应该是告诉大家什么才是正确的,以及为什么那个是错的,而这个是对的。即使对于一个错别字而言,如果你只是说“声名狼籍”中有错字,我想这是不够的。你还应该告诉大家正确的写法是“声名狼藉”。这样做,第一是为了让其他读者能够从你找出的错误中学到东西(你只说一个东西错了却不告诉别人怎样改正以及为什么错了,别人其实什么都没学到)。第二,你分析和改正错误的过程恰恰是你学习和提高的最重要环节(这一点我的一本译作《代码阅读》中有更为精辟的论述)。
3)最后仍然算是一个学习和阅读的建议。全书的代码我都已经公开发布在我的博客上。代码当然很重要,“Talk is cheap. Show me the code.”(语出Linus Torvalds)。但之于我这本书而言,它的精华绝对不在源代码上,而应该是我对于算法原理本身的讲解。我甚至不希望这些冗长的代码挤占了我图书宝贵的篇幅,而将它们转帖到我的博客上,读者应该明白我的一番用心。
这些代码仅仅是在你深入理解算法实现过程中起到一点点有限的辅助作用。如果你过于关注代码,那无疑就是“舍本逐末,买椟还珠”。如果你只是对某个算法的实现代码感兴趣,你确实不用浪费钱去淘一本《算法之美》。我博客上所有的代码都有清晰的标识告诉你它在执行一个什么任务,你只要到我的博客上复制或者阅读它们就行。
如果你只是把我的代码黏过去,在你的IDE上执行一下,观察一下输出结果,同样也是没有意义的。这样甚至有点自欺欺人,或者说你都不应该关心我程序的输出结果到底是什么,它的实现过程远比输出结果更有意义。“学而不思则罔”,思考对于学习的过程而言非常重要,你在阅读实现代码时,应该考虑的是我用文字描述的算法流程是如何对应到一行一行的源码的,你每时每刻都要试着问自己,是不是真的读懂了这些代码的每一行都在做什么事。所以代码错误中最高级的错误应该是逻辑错误(也就是说算法在实现上就出现了问题),至于一个变量有没有初始化,用完的内存有没有释放(当然我相信我的代码都有释放内存)尽管它们也会引起程序出错,但是它们至少不应该是本书读者关注的焦点。如果你还在考虑这些语法上的错误,那么你更应该读的书应该是《C++编程思想》《Effective C++》《C++ Primer》这些解释编程语言的书。数据结构和算法学习确实与编程能力的提升相辅相成,但是你显然不能以看算法书为手段来学习计算机语言语法(特别是那些tricky的细节),就像你不应该去餐馆里买铁锅和盘子,也不应该去水果店买塑料袋一样。
(本文完)