目录
方式一(fork): 只能在Unix/Linux/Mac系统下执行,windows不可以
方式二(multiprocessing.Process): 全平台通用
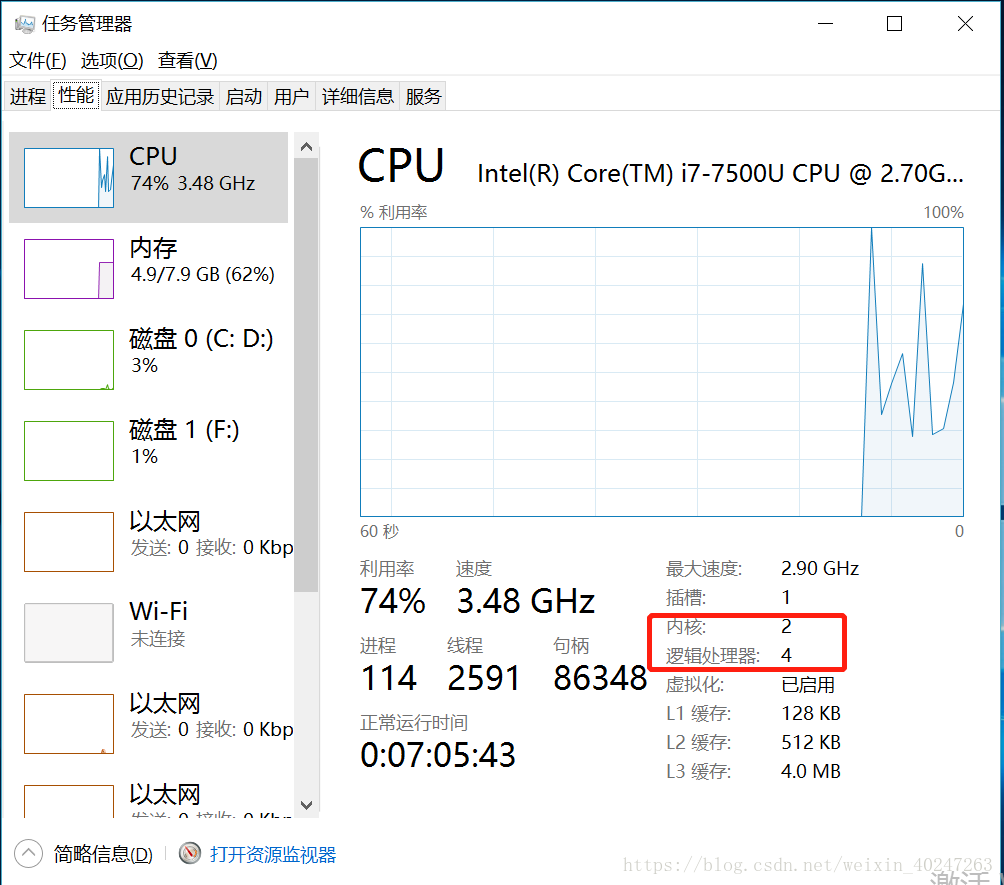
python多线程对CPU的使用率最多为 百分之(100/cpu的逻辑处理器个数 )
名词解释
进程:
一个能够独立运行的程序,如qq、lol 这些都就是一个进程。
线程:
将一个进程,可以分为多个线程,让我们能够同时干很多事,qq音乐你可以听歌的同时操作其页面。
多线程多进程的意义
多线程的优点就是提高cpu的利用率,举个例子,一个工作你交给一个人干,这就是单进程单线程,一个工作你交给多个人干,这就是单进程多线程。 工作代表进程,把工作分成多份每一份就是线程,人就是cpu,具体有多少个人,就是cpu的逻辑处理器个数。比如我的电脑是一个双内核,四个逻辑处理器的cpu,意思就是说我有两个cpu,但是这个cpu用了超线程技术,可以当做4个cpu用,但是它的工作能力肯定不如真正的4核cpu。 这个在任务管理器性能一栏可以查看。
多进程意思差不多,一个人正干着一些工作,这时候又来个工作,他忙不开了,找了个人帮他干,就相当于多进程。
多进程的使用
方式一(fork): 只能在Unix/Linux/Mac系统下执行,windows不可以
import os
print('Process (%s) start...' % os.getpid())
pid = os.fork() # 创建一个子进程,代码从这里开始,将会有两个进程访问,一个是本身的主进程,一个是子进程。
# 也就是说调用一次fork()函数,会返回两次值,子进程永远返回0,而父进程返回子进程的ID。
# 这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
if pid == 0:
print('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:
print('I (%s) just created a child process (%s).' % (os.getpid(), pid))方式二(multiprocessing.Process): 全平台通用
代码如下
# encoding=utf8
from multiprocessing import Process
import os
def test_process(name):
print('传入的参数为 : %s' % name)
print('子进程为 : %s,子进程的父线程为 : %s' % (os.getpid(), os.getppid()))
if __name__ == '__main__':
print('主进程为 : %s' % os.getpid())
# 创建一个子进程对象
p = Process(target=test_process, args=('sub_processing',)) # target子线程要执行的函数,args给执行的函数穿参数,参数为一个tuple
# 启动一个子进程
print('子进程开始运行')
p.start()
# 让主进程等待子进程执行完毕再继续执行
p.join()
print('子进程运行完毕')结果如下
C:\Users\Administrator\Desktop>python demo02.py
主进程为 : 10688
子进程开始运行
传入的参数为 : sub_processing
子进程为 : 9616,子进程的父线程为 : 10688
子进程运行完毕代码解释,首先主进程 进入 if 代码块内部,创建了一个子进程,同时给子进程安排了工作,就是执行test_process函数。当p.start()的时候子进程开始工作,同时主进程继续向下执行代码,到达了p.join() ,它发现系统让它先等子进程执行完毕以后再向下执行。最终执行完毕。
注意:我上面的代码在pycharm中执行的时候子进程无法执行函数,不知道为什么。但是我在linux中,以及在cmd中是可以执行的。这里知道原因的朋友麻烦告知一下。
方式三(Pool): 同时创建多个子进程
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time() # 获取当前时间
time.sleep(random.random() * 3) # 让子线程停止 0~3s
end = time.time() # 获取当前时间
print('Task %s runs %0.2f seconds.' % (name, (end - start))) # 两个时间相减,获得运行时间,并保留两位小数
if __name__ == '__main__':
print('Parent process %s.' % os.getpid())
p = Pool(4) # 创建一个进程池,这个进程池最多放4个线程
for i in range(5):
p.apply_async(long_time_task, args=(i,)) # 创建5个进程,第一个为子进程执行的函数,第二个为传递给函数的参数
print('Waiting for all subprocesses done...')
p.close() # close() 以后就会将线程放入进程,并让子进程执行任务
p.join() # 主线程等待子线程执行完毕,再继续执行
print('All subprocesses done.')
运行结果:
C:\Users\Administrator\Desktop>python demo01.py
Parent process 12372.
Waiting for all subprocesses done...
Run task 0 (12124)...
Run task 1 (4252)...
Run task 2 (2400)...
Run task 3 (304)...
Task 3 runs 0.28 seconds.
Run task 4 (304)...
Task 0 runs 0.50 seconds.
Task 1 runs 0.99 seconds.
Task 2 runs 2.43 seconds.
Task 4 runs 2.53 seconds.
All subprocesses done.可以看出,进程 0 ~ 3 ,几乎同时被创建并开始执行任务,进程4是在进程3 执行完毕以后才开始执行,因为我们刚开始定义了进程池最大容量为4,也就是说它对最大同时执行的进程数量进行了控制。当进程3执行完毕以后,空出了一个位置,进程4才能执行,如果pool函数没有给参数的话会按照 cpu的逻辑处理器的个数来作为默认值。
方式四(subprocess模块):
前三种方式都是创建子线程来执行python代码。
方式四是创建一个子进程去cmd命令行下执行命令,如果是linux系统就是去linux的终端执行命令。
例一:
比如,我想在python中创建一个子线程,让它去cmd下执行命令ipconfig去查看一下ip地址。那么就可以如下方式操作:
import subprocess
r = subprocess.call(['ipconfig', ])
print('Exit code:', r)执行结果
C:\Users\Administrator\Desktop>python demo03.py
Windows IP 配置
以太网适配器 VirtualBox Host-Only Network:
连接特定的 DNS 后缀 . . . . . . . :
IPv4 地址 . . . . . . . . . . . . : 192.168.56.1
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . :
无线局域网适配器 WLAN:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
无线局域网适配器 本地连接* 2:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
以太网适配器 以太网:
连接特定的 DNS 后缀 . . . . . . . :
IPv4 地址 . . . . . . . . . . . . : 192.168.1.106
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . : 192.168.1.1
以太网适配器 VMware Network Adapter VMnet1:
连接特定的 DNS 后缀 . . . . . . . :
IPv4 地址 . . . . . . . . . . . . : 192.168.15.1
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . :
以太网适配器 VMware Network Adapter VMnet8:
连接特定的 DNS 后缀 . . . . . . . :
IPv4 地址 . . . . . . . . . . . . : 192.168.46.1
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . :
以太网适配器 以太网 3:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
以太网适配器 蓝牙网络连接:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
Exit code: 0例二:
import subprocess
r = subprocess.call(['nslookup', 'www.python.org'])
print('Exit code:', r)执行结果
C:\Users\Administrator\Desktop>python demo03.py
DNS request timed out.
timeout was 2 seconds.
服务器: UnKnown
Address: 192.168.1.1
非权威应答:
名称: dualstack.python.map.fastly.net
Addresses: 2a04:4e42:a::223
151.101.24.223
Aliases: www.python.org
Exit code: 0例三:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import subprocess
# 下面的代码会创建一个子进程,然后这个子进程会进入 cmd 执行 nslookup www.python.org 命令
print('$ nslookup www.python.org')
r = subprocess.call(['nslookup', 'www.python.org'])
print('Exit code:', r)
# 下面的代码会创建一个子进程,然后这个子进程会进入 cmd 执行 nslookup 命令 按下回车 进入交互模式
# 再输入 set q=mx 回车
# 再输入 python.org 回车
# 再输入 exit 回车
# 然后获取到返回值将返回值转换为gbk,注意,因为我的python安装目录中包含中文,如果转换成utf会报错。
print('$ nslookup')
# Popen其实跟Call 一样,只不过Popen可以后续追加命令,下行代码先创建一个子进程在cmd下执行nslookup命令
# 然后设置了 stdin、stdout、stderr 输入输出流。subprocess.PIPE代表标准流
p = subprocess.Popen(['nslookup'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# 通过commuicate函数将要执行的命令传递给子进程,传递信息给子进程的通道就是stdin。
# 子进程将执行结果通过stdout和stderr 将结果返回,commuicate返回是一个tuple
output, err = p.communicate(b'set q=mx\npython.org\nexit\n')
print(output.decode('gbk'))
print('Exit code:', p.returncode)D:\工作软件\python\pythonw.exe D:/工作资料/pythonTestWorkSpace/thread/mysubprocess.py
$ nslookup www.python.org
Exit code: 0
$ nslookup
DNS request timed out.
timeout was 2 seconds.
默认服务器: UnKnown
Address: 192.168.1.1
> > 服务器: UnKnown
Address: 192.168.1.1
python.org MX preference = 50, mail exchanger = mail.python.org
org nameserver = c0.org.afilias-nst.info
org nameserver = b0.org.afilias-nst.org
org nameserver = b2.org.afilias-nst.org
org nameserver = a2.org.afilias-nst.info
org nameserver = a0.org.afilias-nst.info
org nameserver = d0.org.afilias-nst.org
mail.python.org internet address = 188.166.95.178
a0.org.afilias-nst.info internet address = 199.19.56.1
a2.org.afilias-nst.info internet address = 199.249.112.1
b0.org.afilias-nst.org internet address = 199.19.54.1
b2.org.afilias-nst.org internet address = 199.249.120.1
c0.org.afilias-nst.info internet address = 199.19.53.1
d0.org.afilias-nst.org internet address = 199.19.57.1
a0.org.afilias-nst.info AAAA IPv6 address = 2001:500:e::1
a2.org.afilias-nst.info AAAA IPv6 address = 2001:500:40::1
b0.org.afilias-nst.org AAAA IPv6 address = 2001:500:c::1
b2.org.afilias-nst.org AAAA IPv6 address = 2001:500:48::1
c0.org.afilias-nst.info AAAA IPv6 address = 2001:500:b::1
d0.org.afilias-nst.org AAAA IPv6 address = 2001:500:f::1
>
Exit code: 0
Process finished with exit code 0
再解释一下Popen的代码: 相当于创建了一个子进程做了如下操作

进程间的通信 --Queue
from multiprocessing import Process,Queue
import os, time, random
def write(q): # 一个进程调用这个函数向 Queue中写入数据
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
def read(q): # 另外一个进程调用这个函数 从Queue中获取数据
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True) # 如果Queue中没数据,会等待有数据时会取出,如果为false没数据直接抛出异常
print('Get %s from queue.' % value)
if __name__ == '__main__':
q = Queue() # 创建一个队列,特点是先放进去的数据,会先获取到
pw = Process(target=write, args=(q,)) # 创建一个进程调用写入数据的函数
pr = Process(target=read, args=(q,)) # 创建一个进程调用读取数据的函数
pw.start()
pr.start()
pw.join() # 让主进程等待 写数据的进程执行完毕后在执行
pr.terminate() # 读取数据的进程调用的函数内部是死循环,我们需要手动结束
执行结果
C:\Users\Administrator\Desktop>python commuicate.py
Process to write: 13040
Put A to queue...
Process to read: 13056
Get A from queue.
Put B to queue...
Get B from queue.
Put C to queue...
Get C from queue.为什么使用Queue,我们自己弄一个变量然后多进程之间共享不行么?
不行,因为每个进程中都有一份对变量的拷贝,多进程执行过程中不会相互干涉,代码如下:
from multiprocessing import Process
balance = 0
def change_it(n):
global balance
balance = balance + n
print(balance)
if __name__ == '__main__':
t1 = Process(target=change_it, args=(5,))
t2 = Process(target=change_it, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
执行结果如下
C:\Users\Administrator\Desktop>python thread01.py
5
8
0
可以发现,子进程t1在函数内部的结果为 5,t2的结果为3,当时主进程打印balance的值还是0,哪怕我们在函数内部使用了global关键字还是不会共享同一个 balance。
多线程
简单使用
import time, threading
def loop():
print('线程 %s 正在执行' % threading.current_thread().name)
# threading.current_thread()获取当前线程
# threading.current_thread().name 获取当前线程名
n = 0
while n < 5:
n = n + 1
print('线程 %s >>> %s' % (threading.current_thread().name, n))
time.sleep(1) # 执行到这里停止 1s
print('线程 %s 结束' % threading.current_thread().name)
print('线程 %s 正在运行...' % threading.current_thread().name)
# 创建一个子线程,同时指定子线程要执行的函数,以及子线程的名字。
# 如果不起名,默认为Thread-1,Thread-2等等
t = threading.Thread(target=loop, name='LoopThread')
t.start()
t.join()
print('线程 %s 结束' % threading.current_thread().name)线程 MainThread 正在运行...
线程 LoopThread 正在执行
线程 LoopThread >>> 1
线程 LoopThread >>> 2
线程 LoopThread >>> 3
线程 LoopThread >>> 4
线程 LoopThread >>> 5
线程 LoopThread 结束
线程 MainThread 结束
Process finished with exit code 0注意事项
在多线程中操作共享数据,如果执行的次数过多可能会导致数据结果出现问题,如下:
import threading
# 定义共享的变量
balance = 0
def change_it(n):
# 先加后减,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(1000000):
change_it(n)
# 创建两个线程
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)执行结果
D:\工作软件\python\pythonw.exe D:/工作资料/pythonTestWorkSpace/thread/thread01.py
-5
Process finished with exit code 0
导致原因: 我们编程语言的一行代码,在计算机底层会分为多步来执行,且线程之间对争夺cpu的使用权又非常激烈。所以会出现一下情况
balance = balance + n 这行代码在计算机底层会分为两步
1: 将 balance + n 的运算结果赋值给一个临时变量比如名为 x
2: 将 x 赋值给balance
如果执行顺序如下
线程1 x1 = balance + 5
线程2 x2 = balance + 8
线程2 balance = x2 现在 balance = 8
线程1 balance = x1 现在 balance = 5 实际上balance应该为 13
解决方式就是通过Lock进行加锁,某些代码,在同一时间只允许一个线程来执行。
Lock
为了实现多线程同时操作共享数据不会出现数据错误,我们让多线程先去抢锁,谁抢到了,谁就能去执行被上锁的代码,其它线程必须等待它执行完毕以后且释放锁以后,再去抢锁。 说白了,就是以前多个线程争夺cpu的使用权,现在是争夺锁。从而避免问题,代码如下:
import threading
# 定义共享的变量
balance = 0
# 创建一个锁对象
lock = threading.Lock()
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(1000000):
# 多个线程执行下面一行代码抢锁
lock.acquire()
try:
# 抢到锁的才能执行下面的函数
change_it(n)
finally:
# 执行完以后释放锁
lock.release()
# 创建两个线程
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)执行结果:
D:\工作软件\python\pythonw.exe D:/工作资料/pythonTestWorkSpace/thread/thread01.py
0
Process finished with exit code 0
上面使用了 try ... finally 代码块,是为了确保在代码抛出异常的情况下也必须将锁释放,否则其他线程将会一直等待。从而成为死线程。
python其实不存在多个线程同时执行
python中有一个全局锁叫GIL,所有的线程会抢占这个锁,抢到了执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。但是为什么多个线程操作共享数据时还会出现数据错误呢,就是因为 python的线程执行100条字节码就会自动释放GIL锁,并且python中的一行代码,在计算机底层会执行多步操作。所以对共享数据操作的次数过多时,就会出现执行100条字节码,但在计算机底层还没有将一行代码执行完毕,就换另一个线程来执行了,所以会出现问题。
python多线程对CPU的使用率最多为 百分之(100/cpu的逻辑处理器个数 )
比如我的电脑是 2内核、4个逻辑处理器(可以当作4核cpu来理解),这时我创建4个线程,每一个线程执行的代码都是一个死循环,理想情况应该是4个逻辑处理器使用率都是100%。但实际通过观察python对cpu总体的使用率,仅仅25%,就是因为python的多线程中,不存在多个线程同时占用多个cpu。只会有一个线程占用一个cpu,执行100条字节码以后,它会释放GIL锁,这时4个线程会再次争夺GIL锁,谁抢到了谁用cpu,具体用哪个cpu,由系统来分配。测试代码如下:
import threading, multiprocessing
import os
def loop():
x = 0
while True:
x = x ^ 1
for i in range(multiprocessing.cpu_count()): # multiprocessing.cpu_count() 获取cpu逻辑处理器个数
if i == 0: # 打印一次主线程的 pid
print(os.getpid())
t = threading.Thread(target=loop)
t.start()执行代码

然后我们查看cpu的使用情况
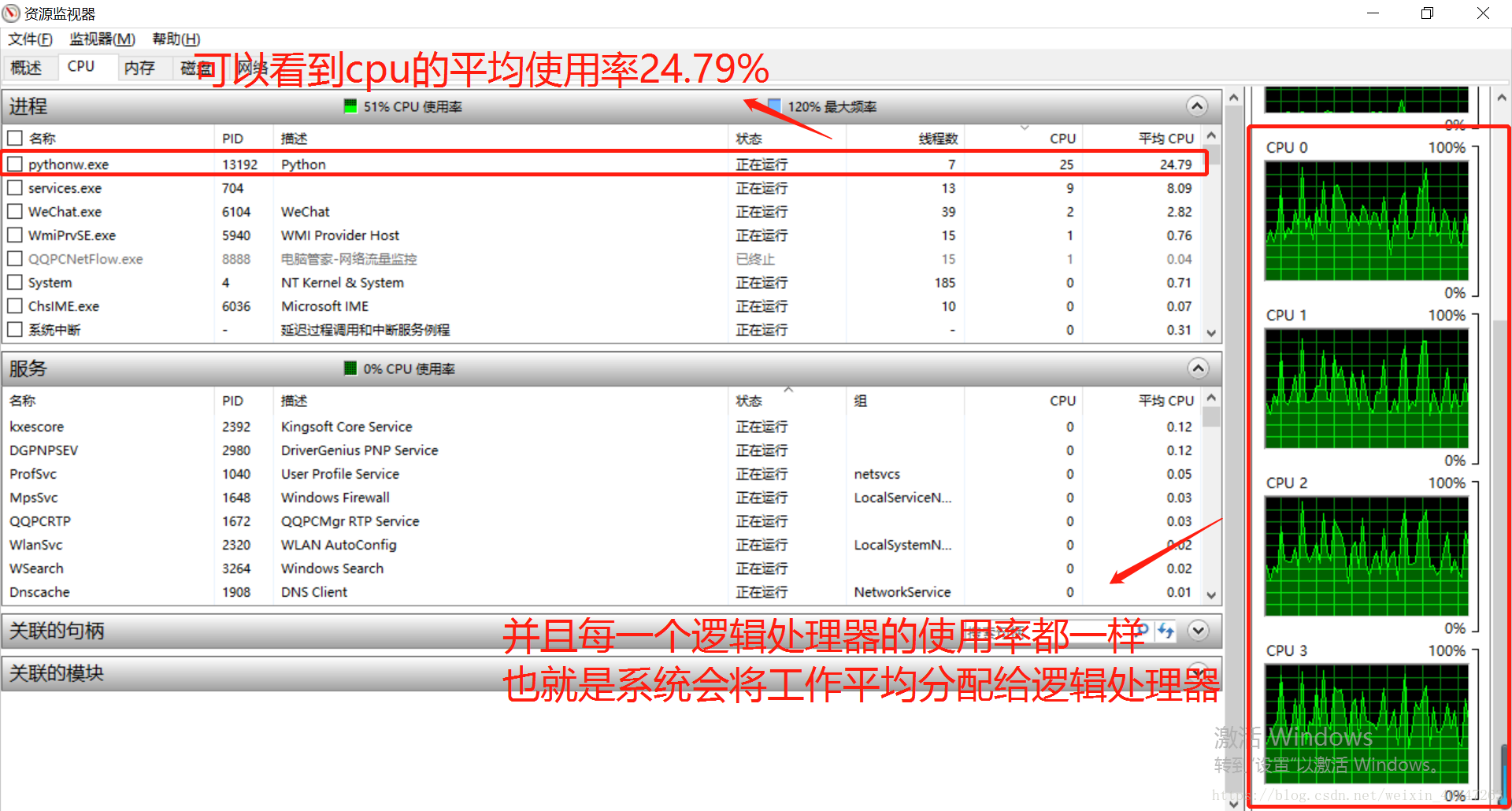
所以说如果在python中想真正有效利用cpu,我们通过多线程显然是无法实现的,不过可以通过多进程来实现,多个Python进程有各自独立的GIL锁,互不影响。
ThreadLocal
上面也说了,多线程如果共享变量的话我们需要加锁,加锁效率就会降低,而且有时处理起来比较麻烦,所以我们在使用多线程时应尽量避免使用全局变量。
我们在函数内部使用局部变量也会涉及一个问题就是如果每一个线程会经过多个函数,且最外层的函数需要用到最内层函数中操作过的属性,那么我们就不得不将这个属性从最内层函数一层一层的返回。
如下:
def inner(name):
std = Student(name)
# std是局部变量,但是每个函数都要用它,因此必须传进去:
center(std)
def center(std):
outter(std)
def outter(std):
print(std.name)这样很麻烦,还有一种方法就是定义一个全局变量dict,每一个线程在执行的函数内部,将线程自身作为key,student对象作为value,传入dict中,在别的函数中再通过key(当前线程) 或取value,这样就无需每一层都去传递了。
global_dict = {}
def inner(name):
std = Student(name)
# 把std放到全局变量global_dict中:
global_dict[threading.current_thread()] = std
center()
def center():
...
outter()
def outter():
# 任何函数都可以查找出当前线程的std变量:
std = global_dict[threading.current_thread()]通过上述案例可以看出,我们的center就是中间层的函数不需要student对象,这时inner既不用传递参数,center也不用传递参数了,而outter需要直接从global_dict中获取就可以了。
但是,现然每一次放入global_dcit 和 从global_dict 中获取数据都比较麻烦。
于是ThreadLocal出现了
import threading
# 对应上面的 global_dict
local_shool = threading.local()
def process_student():
std = local_shool.student # 从ThreadLocal中获取数据
print("Hello, %s (in %s)" % (std, threading.current_thread().name))
def process_thread(name):
local_shool.student = name # 向ThreadLocal放数据
process_student()
t1 = threading.Thread(target=process_thread, args=('Alice',), name='Thread-A')
t2 = threading.Thread(target=process_thread, args=('Bob',), name='Thread-B')
t1.start()
t2.start()
t1.join()
t1.join()可以看出,放数据和取数据我们都不用先获得当前线程了。ThreadLocal 会自动记录当前的线程,从而使每个线程的数据隔离。
同一个线程在其他函数中获取变量也不用担心取出来的数据是其他线程存入的。
以下内容来源于 : 点击进入
进程 vs 线程
1:多进程模式最大的优点就是稳定性高
2:多进程模式的缺点是创建进程的代价大,在Unix/Linux系统下,用fork调用还行,在Windows下创建进程开销巨大。另外,操作系统能同时运行的进程数也是有限的,在内存和CPU的限制下,如果有几千个进程同时运行,操作系统连调度都会成问题。
3:多线程模式通常比多进程快一点,但是也快不到哪去,而且,多线程模式致命的缺点就是任何一个线程挂掉都可能直接造成整个进程崩溃,因为所有线程共享进程的内存。
4:在Windows下,多线程的效率比多进程要高,所以微软的IIS服务器默认采用多线程模式。由于多线程存在稳定性的问题,IIS的稳定性就不如Apache。为了缓解这个问题,IIS和Apache现在又有多进程+多线程的混合模式,真是把问题越搞越复杂。
5:无论是多进程还是多线程,只要数量一多,效率肯定上不去,因为切换任务也需要时间。任务多了以后,系统花费大部分时间在任务切换上面。
计算密集型 vs. IO密集型
计算密集型
大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
IO密集型
涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
异步IO
单进程单线程模型来执行多任务称为异步IO,Nginx就是支持异步IO的Web服务器,它在单核CPU上采用单进程模型就可以高效地支持多任务。在多核CPU上,可以运行多个进程(数量与CPU核心数相同),充分利用多核CPU。由于系统总的进程数量十分有限,因此操作系统调度非常高效。用异步IO编程模型来实现多任务是一个主要的趋势。
python中对应的就是 协程 编程模型,后续再学习。