1.LightGBM是微软2017年新提出的,比Xgboost更强大、速度更快的模型,性能上有很大的提升,与传统算法相比具有的优点: *更快的训练效率
*低内存使用
*更高的准确率
*支持并行化学习
*可处理大规模数据
*原生支持类别特征,不需要对类别特征再进行0-1编码这类的
2.相比XGboost,其更强大的原因是:
(1)histogram算法替换了传统的Pre-Sorted,某种意义上是牺牲了精度换取速度,直方图作差构建叶子直方图更有创造力(直方图算法的基本思想:先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。遍历数据时,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点[利于计算分割打分]。)。
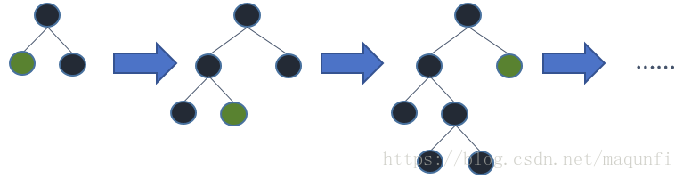
(2)带有深度限制的按叶子生长 (leaf-wise) 算法代替了传统的(level-wise) 决策树生长策略,提升精度,同时避免过拟合危险(不太深了)。
(3)内存做了优化,内存中仅仅需要保存直方图数值,而不是之前的所有数据,另外如果直方图比较小的时候,我们还可以使用保存uint8的形式保存来训练数据。
(4)额外的优化还有Cache命中率优化、多线程优化。 lightGBM优越性:速度快,代码清晰,占用内存小。lightGBM可以在更小的代价下控制分裂树。有更好的缓存利用,是带有深度限制的按叶子生长的策略,使用了leaf-wise策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后进行分裂,不断的进行循环下去,而lead-wise(智能)算法的缺点是可能生长出比较深的决策树,导致过拟合问题,为了解决过拟合问题,我们会在LightGBM中会对leaf-wise之上增加一个最大深度的限制,在保持高效率的同时防止过拟合。
3.使用时的代码示范