1、基本思想:
将样本包含的n个观测数据看成p维(p个输入变量)特征空间中的点,为预测一个新观测X0输出变量y0的取值,首先在已有数据中找到与X0相似的K个观测,如(X1, X2, …, Xk),这些观测称为X0的近邻。对于分类问题,预测值应为最大概率值对应的分类;对于回归预测问题,是近邻输出变量的平均值。
核心问题:依据怎么的标准选择近邻?选择几个近邻(k如何确定)?
2、近邻标准–距离
对于p维空间的任意两点x 和 y
2.1 闵可夫斯基距离
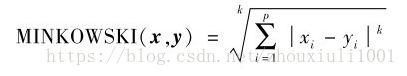
2.2 欧氏距离:闵可夫斯基距离k=2时的特例。
2.3 绝对距离:闵可夫斯基距离k=1时的特例。
2.4 切比雪夫距离:CHEBYCHEV(x,y)=max(| xi-yi|),i=1,2,…,p。
2.5 夹角余弦距离: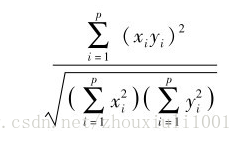
夹角余弦越大,两观测变量整体结构相似度越高。
注:为使各输入变量对距离有“同等的贡献”,计算距离前应对数据进行预处理以消除数量级差异。如极差法:
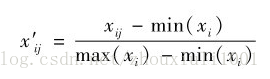
3、近邻个数k的确定
依据对预测误差的接受程度设置参数K:k太小时,预测波动较大,稳健性低;增加K会导致分类边界趋于平滑,预测误差增大
4、预测误差的估计:
旁置法(适合大样本量):train:test = 7:3
留一法(适合小样本量):包含n个观测的样本中,抽出一个观测作为测试样本集,剩余的n-1个观测作为训练样本集。计算成本较高
5、R的k-近法的模拟分析
旁置法: knn(train=训练样本集,test=测试样本集,cl=输出变量,k=近邻个数K,prob=TRUE/FALSE,use.all=TRUE/FALSE)。
注:分类预测:prob = TRUE。使用的是欧式距离
1-近邻法:knn1(train=训练样本集,test=测试样本集,cl=输出变量)
留一法:knn.cv(train=训练样本集,cl=输出变量,k=近邻个数K)
下面以1992年美国总统选举的数据分析不同背景人群的倾向:
变量包含:总统候选人、年龄、年龄分类、受教育年限、最高学历、性别
1)导入数据
rm(list = ls())
gc()
setwd('F:\\XXXX\\XXXX')
getwd()
library(readxl)
df <- read_excel('voter.xlsx',sheet = 1)
#探索数据
head(df)
dim(df)
str(df)

对数据进行预处理,分类数据转化为因子型,数值数据做归一化
#分类变量转换为因子
df$agecat = as.factor(df$agecat)
df$educ = as.factor(df$educ)
df$degree = as.factor(df$degree)
df$sex = as.factor(df$sex)
#对年龄做归一化
for(m in 1:nrow(df)){
df[m,2] = df[m,2]/max(df[,2])
}结果如下图:

2)使用旁置法初步分析:
library(class)
set.seed(1234)
sampId <- sample(1:1847,size = 540,rep =F)
df_test <- df[sampId,]
df_train <- df[-sampId,]
length(df_train[,1])
errRatio3 <- vector()
for(j in 1:100){
knnFit1 <- knn(train = df_train[,c(-1,-3)],test = df_test[,c(-1,-3)],cl = df_train[,1,drop=T],k = j,prob = T)#注意cl:drop = T
DT <- table(knnFit1,df_test[,1,drop = T])#计算混淆矩阵
errRatio3 <- c(errRatio3 ,(1-sum(diag(DT))/sum(DT))*100)#计算错判率
}
pd <- data.frame(
nk = 1:100,
errRatio3 = errRatio3
)
library(ggplot2)
ggplot(data = pd,aes(x=nk,y = errRatio3))+
geom_line()+
labs(title = '近邻数k与错判率',
x = '近邻数',
y = '错判率'
)+
theme(plot.title = element_text(hjust = .5))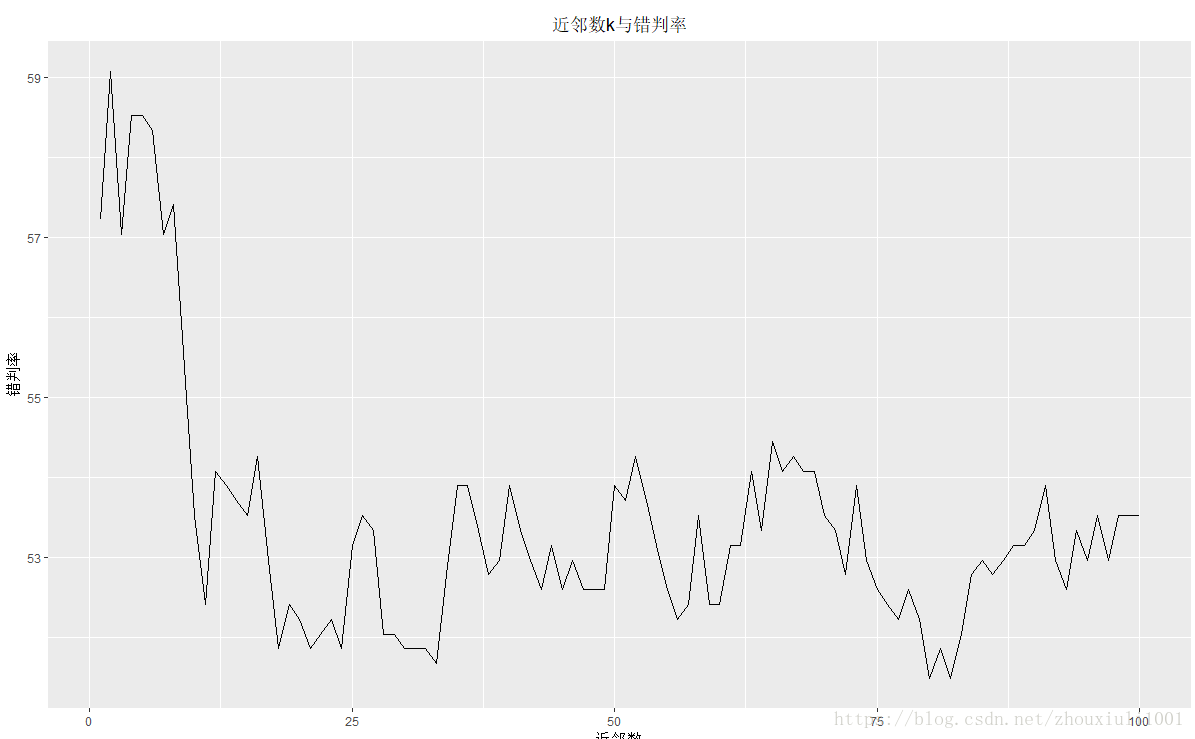
上图k=35左右时,错判率相对较低
3)使用留一法再次计算错判率:
for(j in 1:100){
knnFit4 <- knn.cv(train = df[,c(-1,-3)],cl = df[,1,drop=T],k = j,prob = T)
DT <- table(knnFit4,df[,1,drop = T])
errRatio3 <- c(errRatio3 ,(1-sum(diag(DT))/sum(DT))*100)
}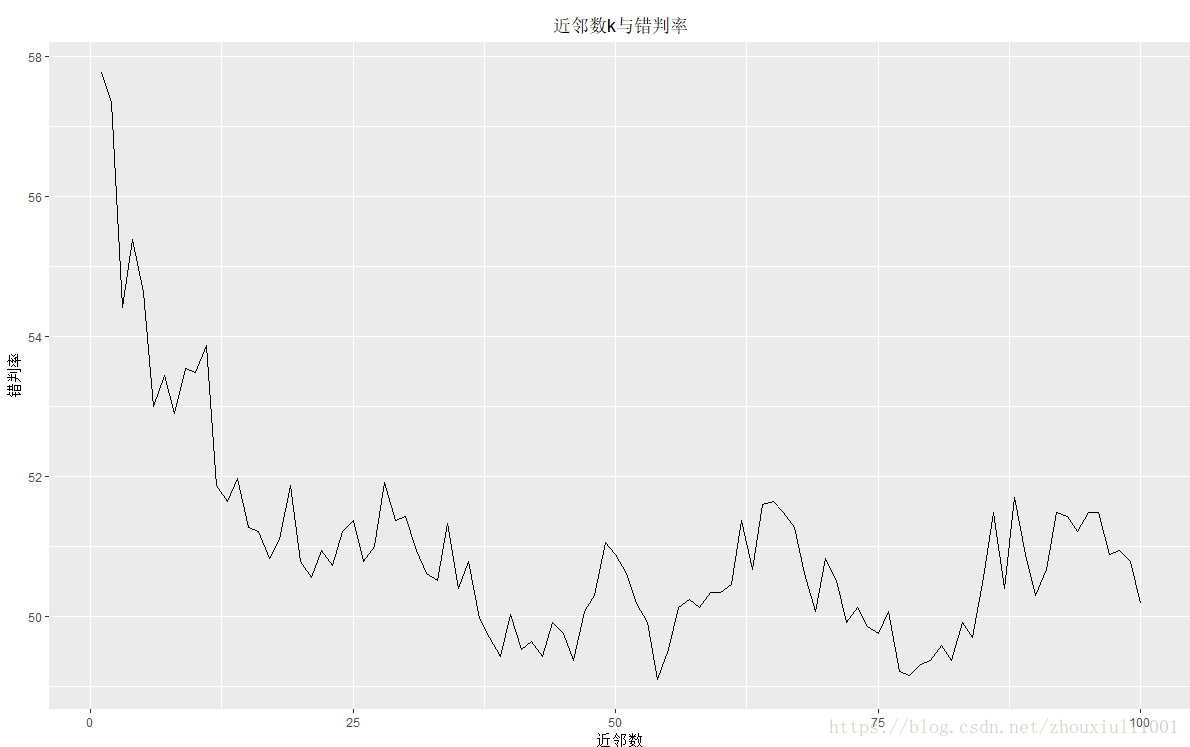
可见,留一法k=55时错判率是最小的,更接近给出模型真实预测误差的无偏估计。
但是整体错判率还是很高,还需进一步提高模型预测能力