正则:
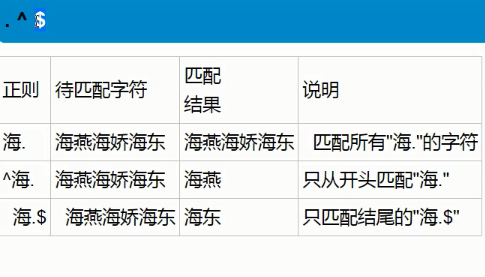
这里要注意:^必须在所有字符的最前面,$必须在所有字符的最末尾;
正则匹配都是贪婪匹配,是尽可能的多匹配,直到不满足,进行下一轮匹配,但结果已经不在一行输出啦;

需注意:?在字符的后面是作为一个量词进行匹配,表示0-1次,但如果 ? 在量词后面,则表示非贪婪匹配(惰性匹配),就是尽可能少的匹配字符;

分析:首先匹配一个李,然后.表示匹配除了换行符以外的其他任意字符,后面的量词*(只约束离它最近的那个字符 也就是.)表示匹配0个或者任意多个,但是这个量词后面跟了一个?就是尽可能少的匹配,也就是.匹配0次啦~
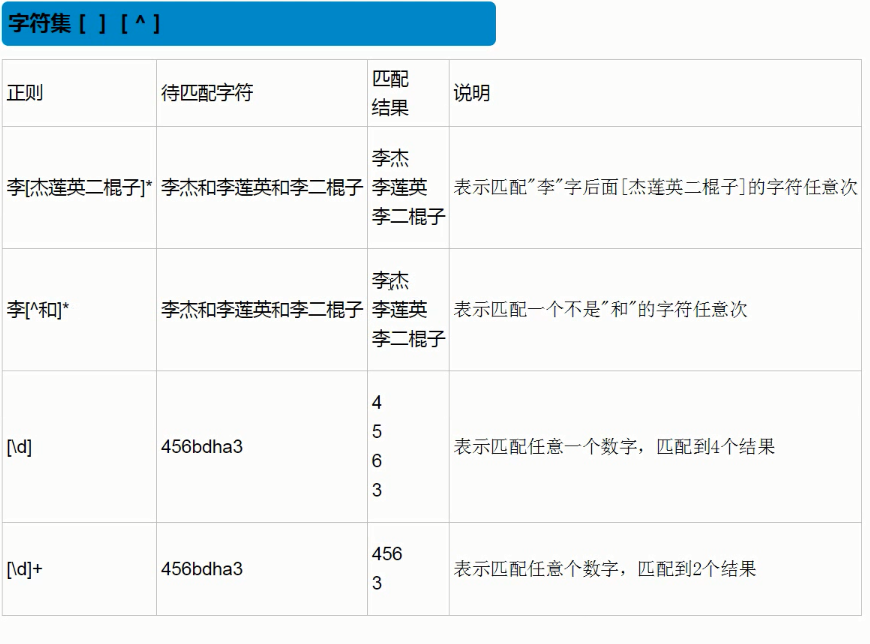
一个正则 只写一个字符,表示就只在一个位置上匹配它,也就是只匹配一次(比如上面的[\d]就是每次只匹配一个数字,所以会一直换行输出),字符后面跟上量词就是会尽可能的贪婪匹配多次([\d]+ 就是匹配一个数字,尽可能多的重复,所以说456在一行输出,但是下一次遇到b 匹配不了,换行重新匹配),直到不满足该正则的规则,重新开始下一条匹配;
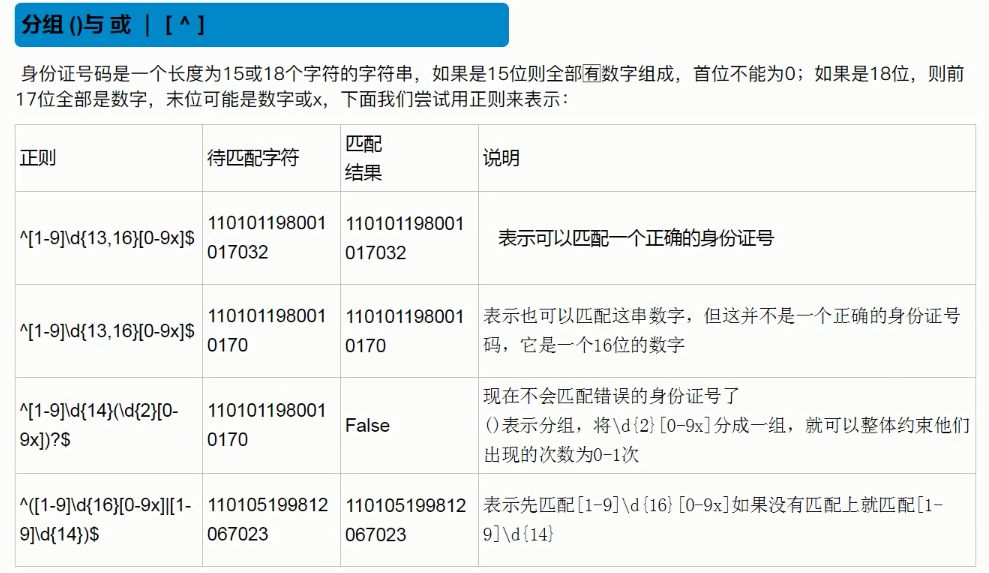
在一个正则表达式中,如果这个量词是想对全部的式子做一个整体约束的话,就用()
需注意: 最后那条使用|"或"连接的两条正则语句,必须是长的放在前面,短的放在后面,表示匹配长的那个匹配不上 再选择匹配短的,如果上面的颠倒过来,来一个18位的身份证号,那匹配15个数字之后 后面三个就不再匹配了,因为或 前面匹配成功后面的那个正则语句就不再执行了~

print('\n')---->其实打印的是换行,但是如果我想去打印\n 这个字符串,而不是打印换行,那我在print()语句中就得写print('\\n')第一个\ 是转义字符,但是这样的话,正则里面需要匹配的就是\\n(print()语句中的字符串 就是正则里需要匹配的结果,然后你根据这个要匹配的结果 来制定相应的正则规则,相当于反向思考的那种感觉),所以我既然要匹配\\n 那我的正则规则必须是\\\\n,,,,这样真的好麻烦!
比如你要匹配的是'\\d'代表你在python中的pint()语句中可能需要利用这个字符串'\\d'只是为了打印\d的效果,这样在正则里是需要写成\\\\d的;
在python中我们可以使用\r来表示转义,在正则里面也是 ,比如我们在print(r'\d') 在正则里需要匹配的字符就是r'\d',那么我们需要写的正则规则就是r'\\d',如果不利用\r ,在python中同样的效果需要print('\\d') 也就是正则需要匹配的字符是‘\\d’ 那么需要写的正则就是‘\\\\d’!!!
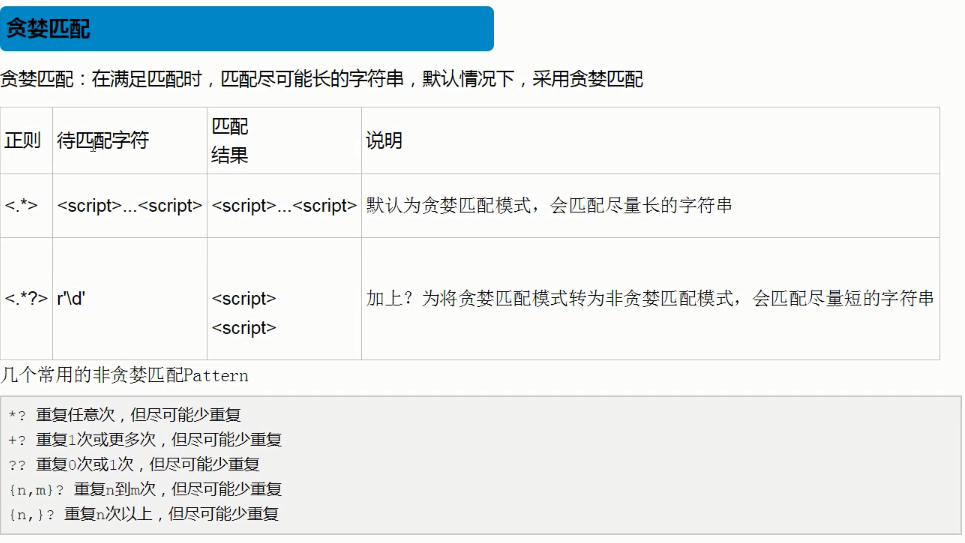
关于第一条语句:
.* 就是匹配任意字符尽可能多匹配,贪婪匹配就是一路往后找 如果后面还有内容 它原本还会继续往后找,代表的执行完.*了 然后正则后面还有一个> 然后发现刚才匹配的不符合,它又会回溯,往前找 直到找到>满足条件的 才会作为最终的结果;
关于第二条语句:
之前Eva-J 说过?放在量词后面 表示尽可能少的匹配,.*是匹配任意字符0到多次,但是加了?就是惰性匹配,变成匹配0次了,所以按照之前的说法就是.*?就是匹配0次,,,,然后现在给的解释是,如果这个量词后面有个? 确实表示贪婪匹配,尽可能少的匹配结果,但是如果?后面还有东西,就先按着后面匹配好一个结果之后,往后就不再匹配了~~~其实说白了就是先按照正则的规则匹配,比如这里先把<.*>匹配了 然后就不再往后找了,然后取尽可能少的(勉强这么理解吧~)
.*?的用法详解
.是匹配任意字符;
*是匹配0或任意多个字符;
?放在量词*后面表示非贪婪匹配;
.*? 合在一起表示,去尽量少的任意字符(那不就是0嘛)
但是!!!
.*?x 就是量词的后面有?表示非贪婪模式 但是?后面还有字符,那就表示取前面任意长度的字符,直到出现一个x就立马停止,此时的?非贪婪表现在出现一个x就停了,后面不再继续匹配了
这样,前面的例子就很好理解啦~