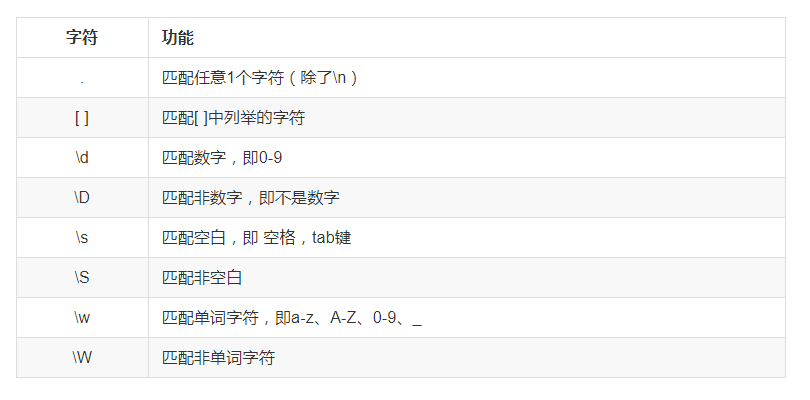
表示字符
示例1: .
#coding=utf-8 import re ret = re.match(".","a") ret.group() ret = re.match(".","b") ret.group() ret = re.match(".","M") ret.group()

示例2:[ ]
#coding=utf-8 import re # 如果hello的首字符小写,那么正则表达式需要小写的h ret = re.match("h","hello Python") ret.group() # 如果hello的首字符大写,那么正则表达式需要大写的H ret = re.match("H","Hello Python") ret.group() # 大小写h都可以的情况 ret = re.match("[hH]","hello Python") ret.group() ret = re.match("[hH]","Hello Python") ret.group() # 匹配0到9第一种写法 ret = re.match("[0123456789]","7Hello Python") ret.group() # 匹配0到9第二种写法 ret = re.match("[0-9]","7Hello Python") ret.group()

示例3:\d
#coding=utf-8 import re # 普通的匹配方式 ret = re.match("嫦娥1号","嫦娥1号发射成功") print ret.group() ret = re.match("嫦娥2号","嫦娥2号发射成功") print ret.group() ret = re.match("嫦娥3号","嫦娥3号发射成功") print ret.group() # 使用\d进行匹配 ret = re.match("嫦娥\d号","嫦娥1号发射成功") print ret.group() ret = re.match("嫦娥\d号","嫦娥2号发射成功") print ret.group() ret = re.match("嫦娥\d号","嫦娥3号发射成功") print ret.group()

原始字符串
>>> mm = "c:\\a\\b\\c" >>> mm 'c:\\a\\b\\c' >>> print(mm) c:\a\b\c >>> print(mm) c:\a\b\c >>> re.match("c:\\\\",mm).group() 'c:\\' >>> ret = re.match("c:\\\\",mm).group() >>> print(ret) c:\ >>> ret = re.match("c:\\\\a",mm).group() >>> print(ret) c:\a >>> ret = re.match(r"c:\\a",mm).group() >>> print(ret) c:\a >>> ret = re.match(r"c:\a",mm).group() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'NoneType' object has no attribute 'group' >>>
说明
Python中字符串前面加上 r 表示原生字符串,
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,有了原始字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
>>> ret = re.match(r"c:\\a",mm).group() >>> print(ret) c:\a
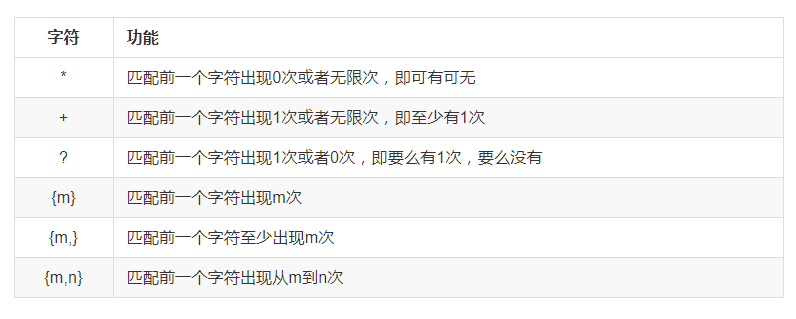
表示数量
匹配多个字符的相关格式
示例1:*
需求:匹配出,一个字符串第一个字母为大小字符,后面都是小写字母并且这些小写字母可有可无
#coding=utf-8 import re ret = re.match("[A-Z][a-z]*","Mm") ret.group() ret = re.match("[A-Z][a-z]*","Aabcdef") ret.group()

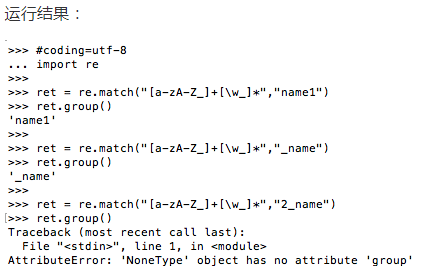
示例2:+
需求:匹配出,变量名是否有效
#coding=utf-8 import re ret = re.match("[a-zA-Z_]+[\w_]*","name1") ret.group() ret = re.match("[a-zA-Z_]+[\w_]*","_name") ret.group() ret = re.match("[a-zA-Z_]+[\w_]*","2_name") ret.group()
示例3:?
需求:匹配出,0到99之间的数字
#coding=utf-8 import re ret = re.match("[1-9]?[0-9]","7") ret.group() ret = re.match("[1-9]?[0-9]","33") ret.group() ret = re.match("[1-9]?[0-9]","09") ret.group()

示例4:{m}
需求:匹配出,8到20位的密码,可以是大小写英文字母、数字、下划线
#coding=utf-8 import re ret = re.match("[a-zA-Z0-9_]{6}","12a3g45678") ret.group() ret = re.match("[a-zA-Z0-9_]{8,20}","1ad12f23s34455ff66") ret.group()
