在用python写爬虫时,不可避免的会遇到一些需要登陆账号后才可以看到需要内容的网站。本次我们就以模拟登陆豆瓣为例。
为了让我们的登陆看起来更像是从一个浏览器发起的访问,我们需要为我们的请求额外添加headers和cookies。
首先打开火狐浏览器输入www.douban.com,填写好自己的豆瓣账号密码。

点击登陆后再摁F12打开开发者工具切换到网络窗口往上翻到第一条请求。
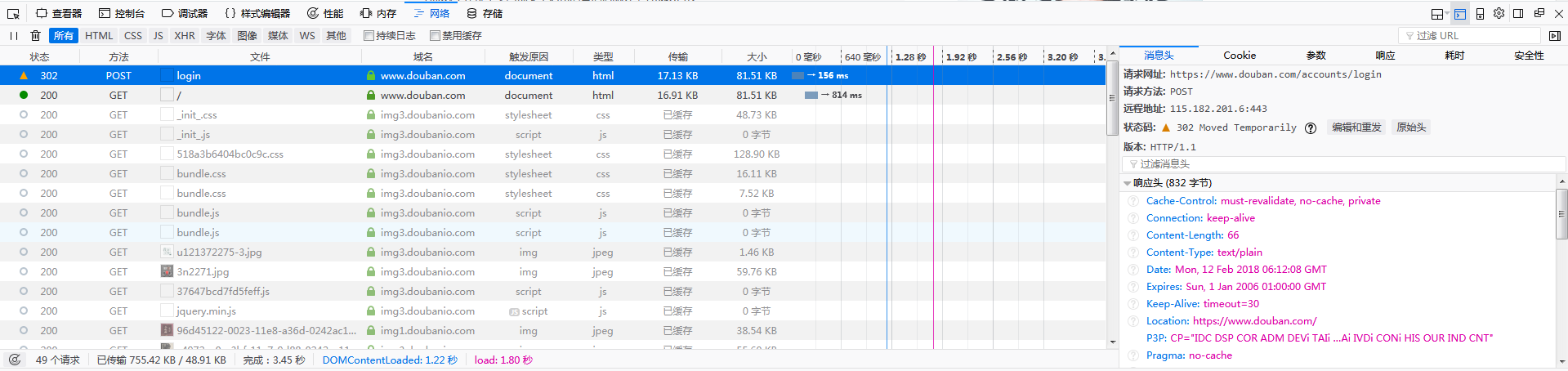
右边小窗口,我们需要查看的信息有消息头、Cookie、参数,参数就是我们提交的账号密码。
将需要的数据Copy下来放到我们的Python代码中。
url = 'https://www.douban.com/accounts/login'
data = {'form_email': '[email protected]', 'form_password': '*********'}
cookie = 'bid=JOQgynsdNDg; ll="118305"; _pk_id.100001.8cb4=a8335c46910bfcad.1518403729.1.1518403729.1518403729.; _pk_ses.100001.8cb4=*; __utma=30149280.1866736468.1518403730.1518403730.1518403730.1; __utmb=30149280.1.10.1518403730; __utmc=30149280; __utmz=30149280.1518403730.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmt=1'
cookies = {}
cookie = cookie.split(';')
for line in cookie:
key, value = line.split('=', 1)
cookies[key] = value
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0',
'Host': 'www.douban.com'}
response = requests.post(url, headers=headers, data=data, cookies=cookies)
print("网页请求状态码:%s"%response.status_code)
print(response.text)
好了,让我们运行一下代码,很好,请求成功
网页请求状态码:200
纳尼!登录失败!验证码?刚才登陆没有要验证码啊
哦哦,原来是Cookie过期了,因为代码是很久前写的...我没有换新的Cookie。
算了,既然遇到验证码的问题就一并解决它吧。
经过深思熟虑,我决定用最原始的办法,手动输入验证码
如果你觉得没有自动识别验证码而失望的话,先别急,因为在这之前我也看过一些开源识别验证码的框架,对于一些图案背景简单的验证码识别率是很高的,但是你要知道,你能用代码自动识别验证码,也有人会想进办法防止程序能自动识别,所以现在的验证码种类繁多,有在图案背景、验证码内容上做文章的,也有使用新技术的,比如拖动滑块至指定位置的、选择图案的(12306)......等等。网上也有一些验证码识别平台,但是是要收费的。。。
说了这么多,其实就是豆瓣的验证码复杂度比较高,程序自动识别率较低。
好了,我们再次打开豆瓣网站

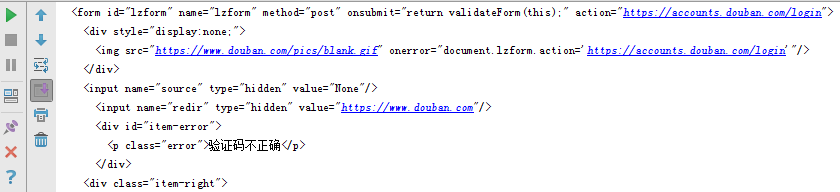
果不其然,有了验证码。
输入验证码,点击登陆,再次打开开发者工具查看登陆的网络请求。
消息头和Cookie没什么变化,主要是参数。可以看到它多了一个captcha-id和captcha-solution。
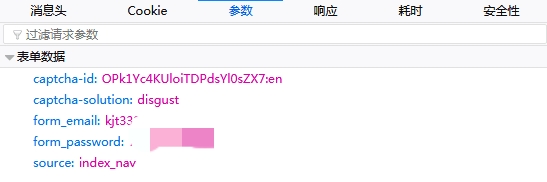
到此我们模拟登陆豆瓣的流程变成:请求豆瓣主页——>爬到验证码图片链接和验证码ID——>打开验证码链接——>从控制台输入验证码——>完成模拟登陆
在上面代码的后面再添加如下代码:
#检索验证码
sel = html.fromstring(response.text)
var_code_url = sel.xpath('//div[@class="item item-captcha"]/div/img[@id="captcha_image"]/@src')[0]
captchaID = sel.xpath('//div[@class="item item-captcha"]/div/div/input[@name="captcha-id"]/@value')
print(var_code_url)
print(captchaID)
captcha = input('please input the captcha:')
data['captcha-solution'] = captcha
data['captcha-id'] = captchaID
response = requests.post(url, headers=headers, data=data, cookies=cookies)
print(response.status_code)
print(response.text)
短短几行代码,我们再运行一下试试
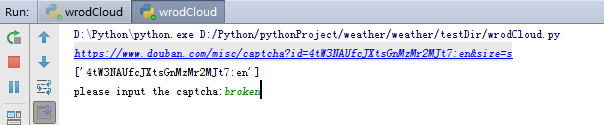
很好,成功抓到链接和ID,输入验证码内容,点击回车见证成功吧~
200
ojbk,请求成功,再往下看

默默给自己一个竖一个大拇指

再往下翻,随便点一个文章链接,成功打开。到此,模拟登陆豆瓣完成!接下来就随心所欲的爬取你想要的内容好了!
总结一下:本篇文章内容技术难度不高,但是我觉得为大家展示一个问题的完整解决过程,对大家以后遇到问题时思路上可能会有些帮助,也希望可以帮助到喜欢python又刚刚入门的朋友。谢谢大家。