转:
参考内容:https://blog.csdn.net/qq_37334135/article/details/78162285
namenode对数据的管理采用了三种存储形式:
内存元数据(NameSystem)
磁盘元数据镜像文件
数据操作日志文件(可通过日志运算出元数据)
元素据存储机制
1、内存中有一份完整的元数据(内存meta data)
2、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
3、用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)。
注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存meta.data中
namenode管理元数据的流程图
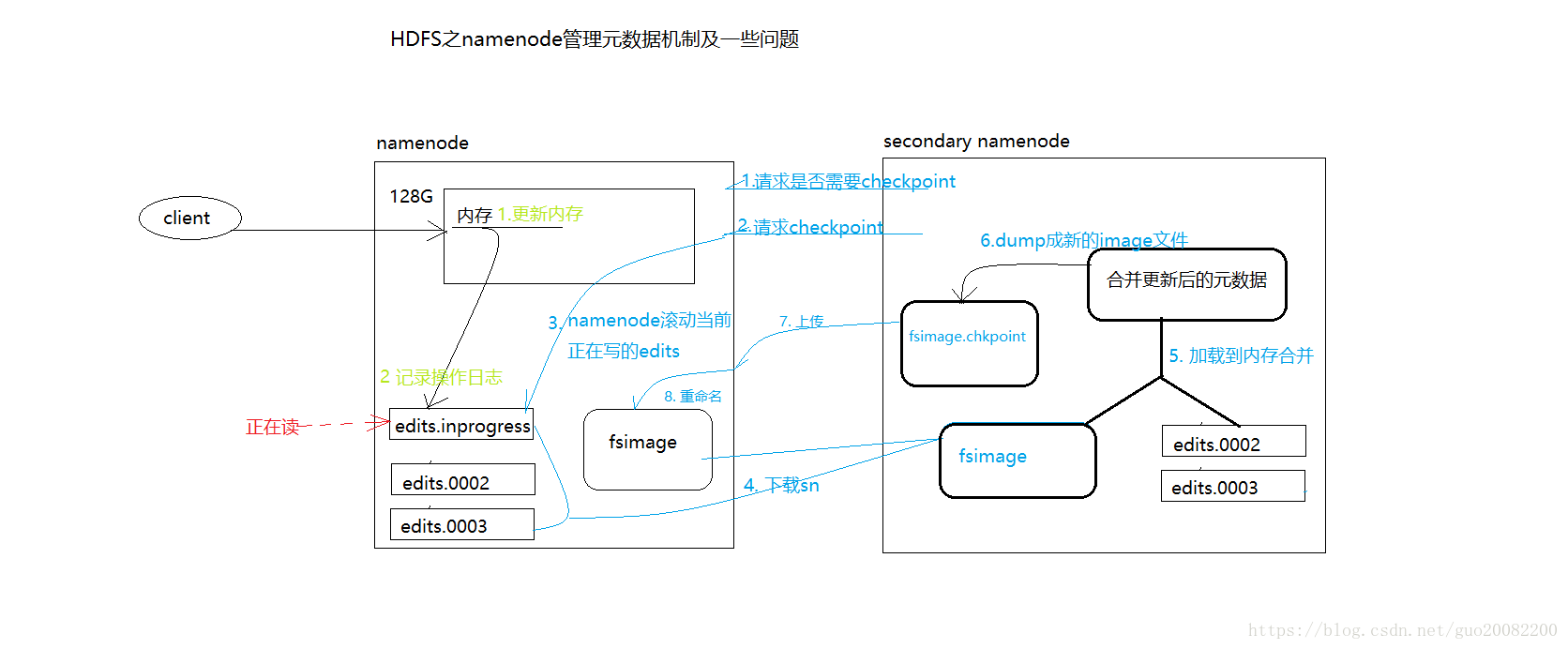
分析:
1、当客户端向namenode发出更新元数据的请求时,namenode会根据更新的数据内容存放位置等从而来更新好元数据。而每次做的更新操作都会被记录到操作日志文件中(edits)。
2、为了防止namenode挂掉数据丢失从而准备了一个secondaryNamenode,从而可以将namenode上的数据备份。它会每隔一段时间(默认是30分钟)去询问一次namenode,看看是否需要合并(checkpoint),当namenode上的操作日志文件大到一定的时候会告诉secondaryNamenode需要合并。
3、此时namenode会滚动当前在操作的日志文件edits.inprogress(目的是多下载一些到secondaryNamenode)。
4、secondaryNamenode会将edits文件和镜像文件fsimage下载下来,接着会根据操作日志文件根据一些算法计算出元数据从而来和镜像文件(保存了namenode的元素据)进行合并存到内存中。
5、secondaryNamenode会将内存中合并后的的元数据存到硬盘,序列化上传到namenode,最后namenode会将secondaryNamenode上传的元数据存到镜像文件中,这样镜像文件就达到了备份的效果,同时secondaryNamenode上也有对应的元数据,即使namenode挂掉我们也可以复制secondaryNamenode上的数据到namenode。
一些问题
注1:namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据。
注2:checkpoint时,把正在写的滚动一下,然后把fsimage和日志文件下载到secondaryNamenode机器上,但是只有第一次才会下载fsimage文件,因为这个时候fsimage不是很大,下载效率不会慢,以后就只会下载日志文件了,因为每隔一定时间和条件就会下载所以下载量也不会太大。
注3:当namenode宕机的时候,hdfs是否还能正常工作?答案是不能,因为secondaryNamenode虽然有元数据但是并不能代替namenode,比如namenode能对客户端做响应而secondaryNamenode就不行,也不能更新数据,只起到了备份元数据的作用。
注4:如果namenode的硬盘损坏(或者说是工作目录没了)那么元数据还能恢复吗?答案是能恢复大部分数据,上面第五步已经给出了解释,我们可以将secondaryNamenode的目录复制粘贴给它,因为两者的结构数据是一样的。但是如果操作过快,比如我刚创建了一个文件夹。然后删掉了目录,这个时候secondaryNamenode都没来得及下载备份,所以这条数据不能回复。
注5:配置namenode工作目录参数的时候,最后将namenode的工作目录配在多块磁盘上,同时往2块磁盘上写数日志,内容是一样的。如下
<property>
<name>dfs.name.name.dir</name>
<value>/root/hadoop/hdf1,/root/hadoop/hdf2</value>
</property>