-
NameNode职责:
负责客户端请求的响应
元数据的管理(查询,修改) -
元数据管理
namenode对元数据的管理采用了三种存储形式:
a.内存元数据(NameSystem)
b.磁盘元数据镜像文件
c.数据操作日志文件(可以通过日志运算出元数据)2.1 元数据存储机制:
A.内存中有一份完整的元数据(内存 meta data)
B.磁盘有一个"准完整"的元数据镜像(fsimage),文件(在namenode的工作目录中)
c.用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edit文件)
注:当客户端对hdfs中的文件进行新增或者修改操作时,操作记录首先被记入edits日志文件中,当客户端操作成功之后,相应的元数据会更新到内存meta.data中
hdfs文件系统删除之后的备份:
删除之前hdfs文件系统上的所有的文件:
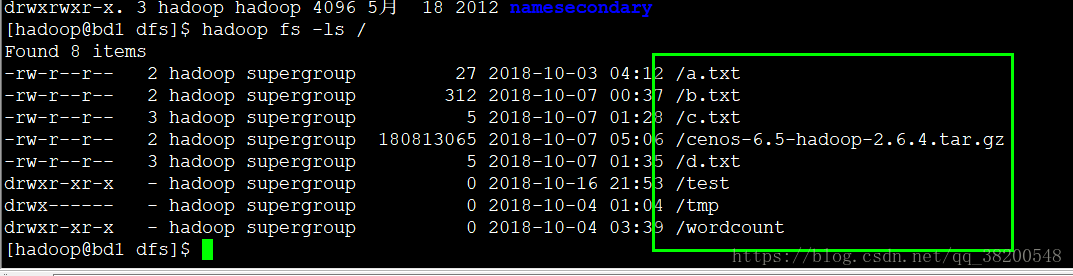
接下来删除 hdpdata下的name文件:
使用jps查看进程,发现hadoop进程还是启动着,原因是在内存中运行,可以杀死NameNode进程:
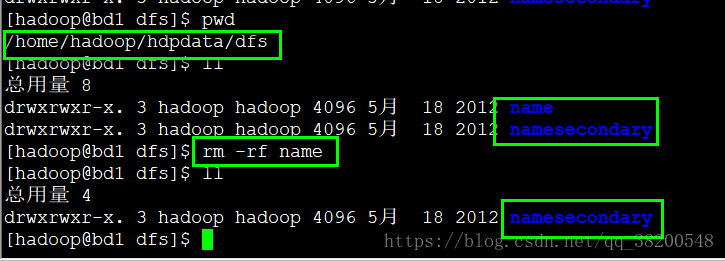
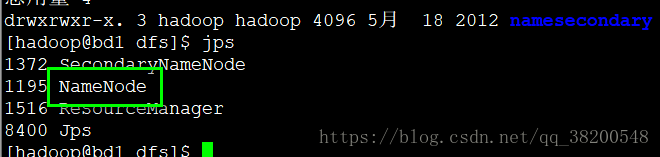
然后手动启动namenode:
hadoop-daemon.sh start namenode

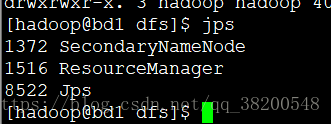
但是此时hadoop集群已经拒绝连接了,其他的机器也都是这样:

并且在bd1上的namenode并没有启动成功:
将namesecondary这个文件夹的内容全部复制到当前目录,取名叫作name
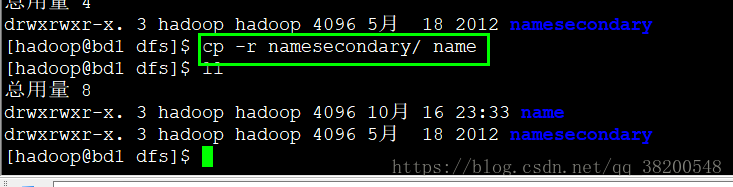
复制好了这个namesecondary之后,再次启动namenode:
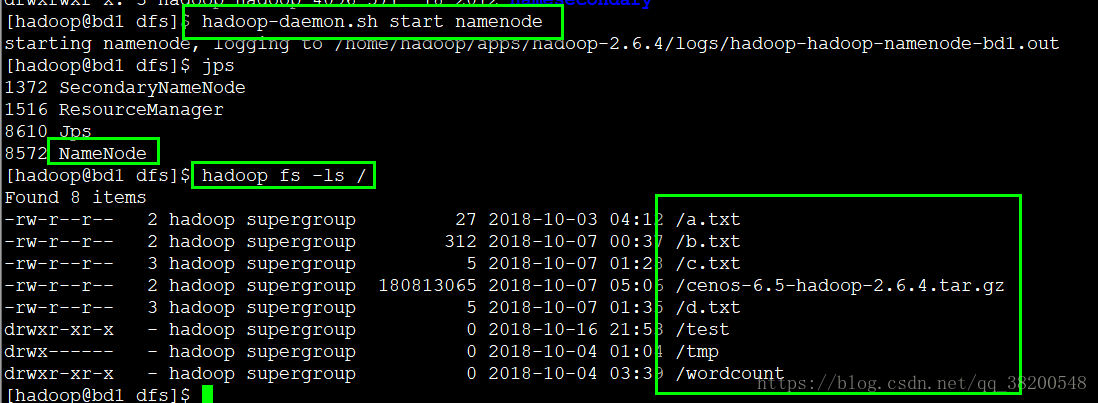
这次能够正常启动,并且能够正常查询到hadoop集群上的hdfs文件系统上的文件,恢复了之前的样子.
这两个工作目录 name 和 namesecondary 的结构是一样的.所以就可以用namesecondary来恢复.
日过此时在hdfs上新建一个文件,然后把name目录删除,重复上面的恢复的步骤,那么这个新建的文件是不会恢复的,这个刚刚新建的文件还只是在日志文件里面,还没来得及做合并.namesecondary里面还没有这个元数据.所以恢复出来之后就会少一个文件.
综上,namesecondary就可以做一个数据源的备份.
checkpoint 的附滞作用:
namenode 和 secondary namenode 的工作目录存储结构完全相同,所以,当namenode故障退出
需要重新恢复时,可以从secondary namenode 的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据.
namenode 如果被毁了,就通过上面的方法进行恢复,我们还可以通过配置降低风险.
我们可以将namenode的工作目录放在多快磁盘上,那么edits文件就会写在多块磁盘上.如果一块磁盘坏了,那么另一块磁盘还保存着数据.
那么就需要修改配置文件:
进入配置文件的目录
/home/hadoop/apps/hadoop-2.6.4/etc/hadoop
修改 hdfs-site.xml 这个配置文件.
namenode的工作目录有一个默认的参数.

<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/name1,/home/hadoop/name2</value>
</property>
然后重新启动hdfs,先把所有的服务关闭,然后重新format才能生效
hadoop namenode -format

自动生成了 name1 和 name2 这两个目录
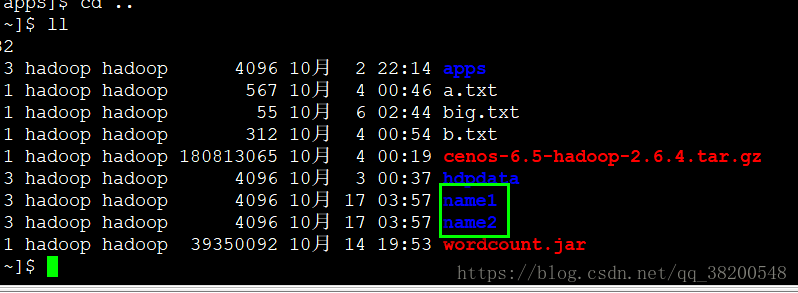
再启动hdfs的时候,元数据就会同时往name1和name2这两个目录里面写.
启动的命令:
start-dfs.sh
这样的话,就爽一块磁盘坏了,另一块磁盘里面还有数据.
两块磁盘的IO是不冲突的,可以并发进行.
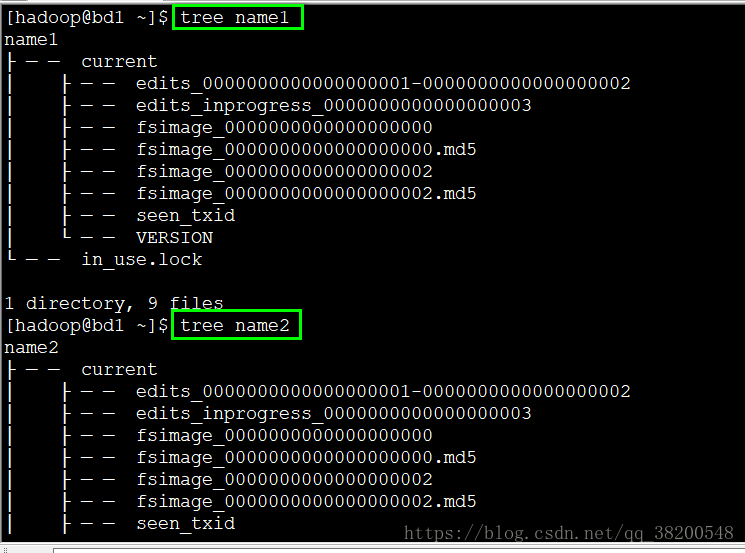
namenode 和 datanode 的工作目录也可以配置多个,使用逗号隔开.
/home/hadoop/apps/hadoop-2.6.4/etc/hadoop/core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hdpdata</value>
</property>
现在我格式化了namenode ,然后上传一个a.txt的小文档.看一下这四台机器的工作目录的区别 hdpdata
bd1 : namenode:
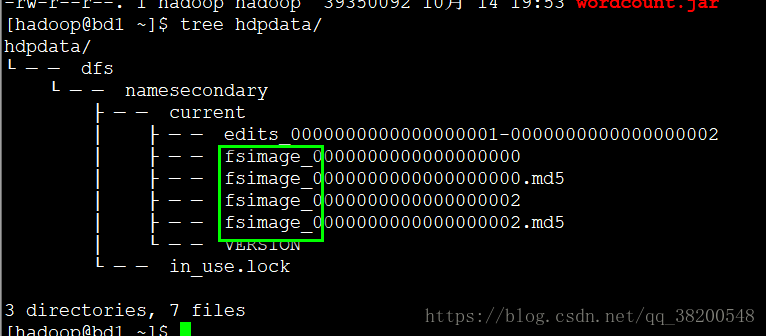
bd2 : datanode:
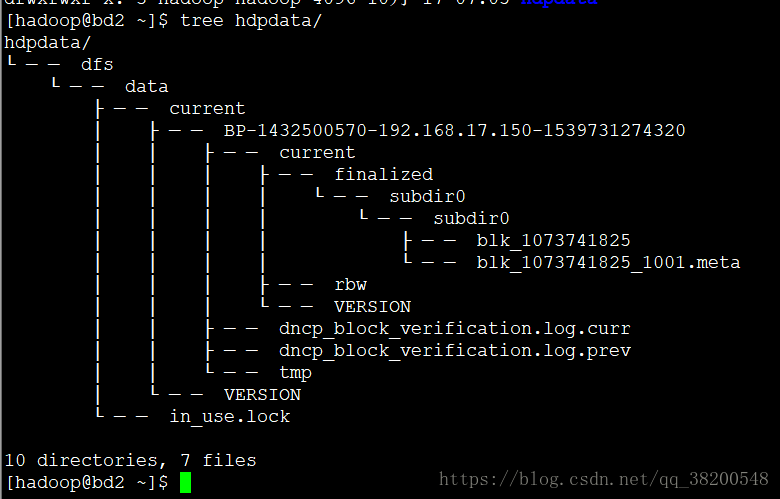
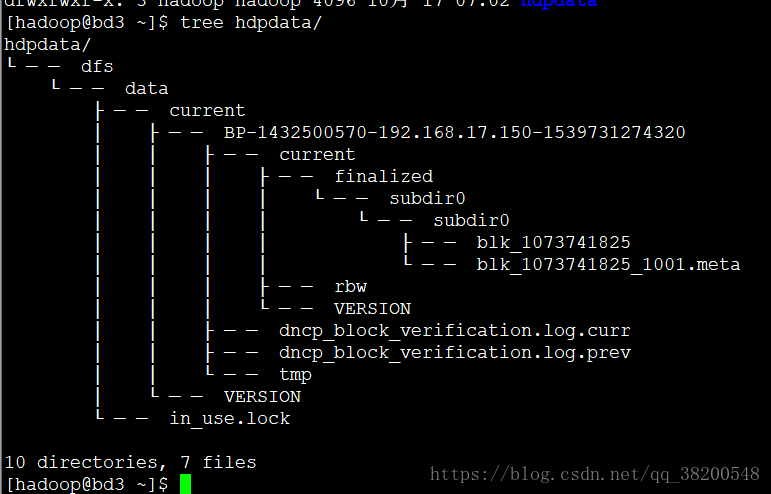
bd3 : datanode :
bd4 : datanode :
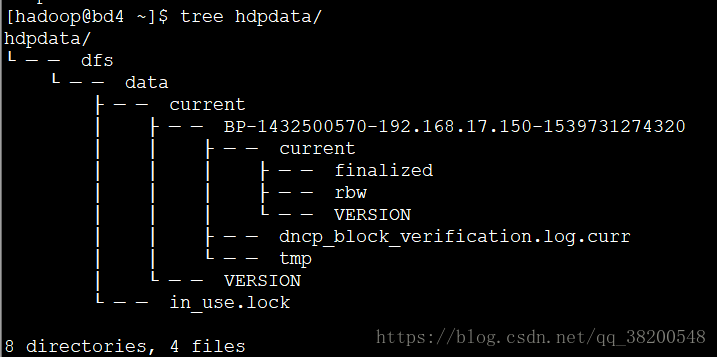
VERSION 文件:
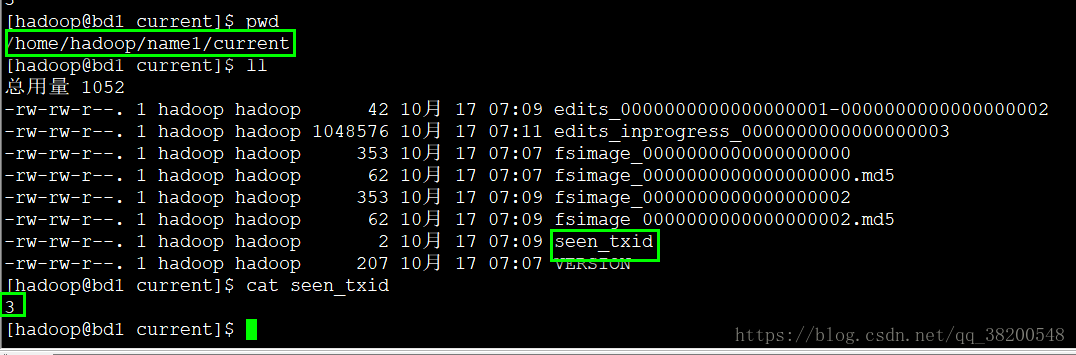
在/home/hadoop/name1/current 里面有一个 seen_txid文件:
每重启一次这个数值就会再 + 1
seen_txid文件记录的是edits滚动的序号,每次重启namenode时,namenode就知道要将哪些edits进行加载到内存.
VERSION 文件 :
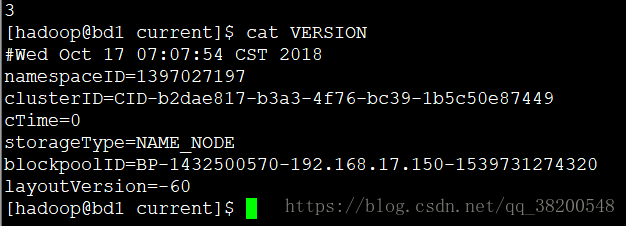
各个属性的含义:
(1) namespaceID 是文件系统的唯一标识,在文件系统首次格式化之后生成;
(2) storageType 说明这个文件存储的是什么进程的数据结构信息(如果是 DataNode, 那么 storageType=DATA_NODE)
(3) cTime 表示NameNode 存储时间的创建时间,由于我的NameNode没有更新过,所以这里的记录值为0,以后对NameNode升级之后,cTime将会记录更新时间戳.
(4) layoutVersion 表示 HDFS 永久性数据结构的版本信息,只要数据结构变更,版本号也要递减,此时的HDFS也需要升级,否则磁盘仍旧是使用旧版本的数据结构,这会导致新版本的NameNode 无法使用;
(5) clusterID是系统生成或手动指定的集群ID,在-clusterid选项中可以使用它;