转自Jack Cui http://cuijiahua.com/blog/2017/11/ml_2_decision_tree_1.html
求香农熵:
p(xi)是选择该分类的概率

from math import log
def calcShannonEnt(dataset):
numEntries=len(dataset)#求数据集列表的行数
labelCounts={}
for featVec in dataset:
currentLabel=featVec[-1]
#如果该键不在字典中,则向字典中添加该键并赋值为0
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
shannonEnt=0.0
for key in labelCounts:
prob=float(labelCounts[key])/numEntries
shannonEnt-=prob*log(prob,2)
return shannonEnt
def createDataSet():
dataSet=[[0, 0, 0, 0, 'no'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels=["不放贷","放贷"]
return dataSet,labels
dataSet,features=createDataSet()
shannon=calcShannonEnt(dataSet)
print("熵:",shannon)
根据特征划分数据集:
学习划分技巧
def splitDataSet(dataSet,axis,value):
retDataSet=[]
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec=featVec[:axis]
#注意extend和append的区别
reducedFeatVec.extend(featVec[axis+1:])#[]
retDataSet.append(reducedFeatVec)#[[]]
return retDataSet
newDataSet=splitDataSet(dataSet,0,0)
print("重新划分的数据集为:",newDataSet)
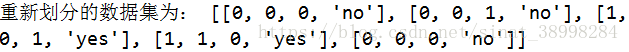
计算信息增益

def chooseBestFeatureToSplit(dataSet):
numFeatures=len(dataSet[0])-1
bestInfoGain=0.0
bestFeature=-1
for i in range(numFeatures):
#当i=0时,[0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2]
featList=[example[i] for example in dataSet]
uniqueVals=set(featList)#元素不可重复
newEntropy=0.0
for value in uniqueVals:
subDataSet=splitDataSet(dataSet,i,value)
prob=len(subDataSet)/float(len(dataSet))
newEntropy+=prob*calcShannonEnt(subDataSet)
infoGain=shannon-newEntropy
print("第%d个特征的增益为%.3f"%(i,infoGain))
if(infoGain>bestInfoGain):
bestInfoGain=infoGain
bestFeature=i
return bestFeature
print("最优特征索引值:"+str(chooseBestFeatureToSplit(dataSet)))