在过去几年中,神经网络已经看到壮观进展,并且他们现在是图像识别和自动翻译领域中最强者。TensorFlow是数值计算和神经网络发布的谷歌的新框架。在这个博客中,我们将演示如何使用TensorFlow和Spark一起训练和应用深度学习模型。
你可能会困惑:在最高性能的深度学习实现是单节点的当下, Spark 的用处在哪里?为了回答这个问题,我们将会演示两个例子并解释如何使用 Spark 和机器集群搭配 TensorFlow 来提高深度学习的管道数。
- 超参数调整: 使用 Spark 来找到最好的神经网络训练参数集,减少十倍训练时间并减低34%的失误率。
- 部署模型规模: 使用 Spark 在大量数据上应用训练完毕的神经网络模型。
超参数调整
深度机器学习(ML)技术的一个例子是人工神经网络。它们采取一个复杂的输入,如图像或音频记录,然后应用复杂的数学变换这些信号。此变换的输出是更易于由其他ML算法操纵的数字向量。人工神经网络通过模仿人类大脑的视觉皮层的神经元(以相当简化的形式)执行该转换。
就像人类学会解读他们所看到的,人工神经网络需要通过训练来识别那些“有趣”的具体模式。例如,这些可以是简单的模式,例如边缘,圆形,但也可以是更复杂模式。在这里,我们将用NIST提供的经典数据集来训练神经网络识别这些数字:

TensorFlow 库自动创建的各种形状和大小的神经网络训练算法。建立一个神经网络的实际过程,比在数据集上跑一些方法要复杂得多。通常有一些非常重要的超参数(通俗地说,参数配置)来设置,这将影响该模型是如何训练的。选择正确的参数会导致性能优越,而坏的参数将会导致长时间的训练和糟糕的表现。在实践中,机器学习从业者会多次使用不同的超参数运行相同的模型,以期找到最佳的集合。这是一个经典的技术,称为超参数调整。
建立一个神经网络时,有许多需要精心挑选的重要超参数。 例如:
- 在每个层的神经元数目:太少的神经元会降低网络的表达能力,但太多会大大增加运行时间,并返回噪音估计。
- 学习速度:如果过高,神经网络将只专注于看到过去的几样,并不顾一切之前积累的经验。如果太低,这将需要很长时间才能达到一个很好的状态。
这里有趣的是,即使 TensorFlow 本身不予分发,超参数调整过程是“embarrassingly parallel”,并且可以使用 Spark 分配。在这种情况下,我们可以使用 Spark 广播常见的元素,例如数据和模型描述,然后以容错方式安排跨越机器集群的个体进行重复计算。
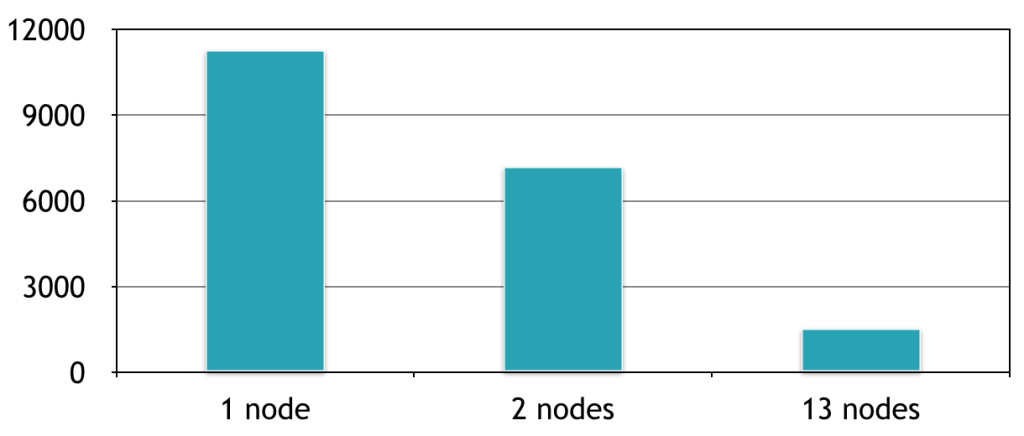
如何使用 Spark 提高精度?用默认的超参数设置精度为99.2%。我们在测试集上的最好结果是99.47%的精确度,减少34%的测试误差。分布式计算时间与添加到集群节点的数量成线性关系:使用13个节点的集群,我们能够同时培养13个模型,相比于在一台机器一个接着一个训练速度提升了7倍。这里是相对于该集群上机器的数量的计算时间(以秒计)的曲线图:
最重要的是,我们分析了大量训练过程中的超参数的灵敏度。例如,我们相对于不同数目的神经元所得学习率绘制了最终测试性能图:
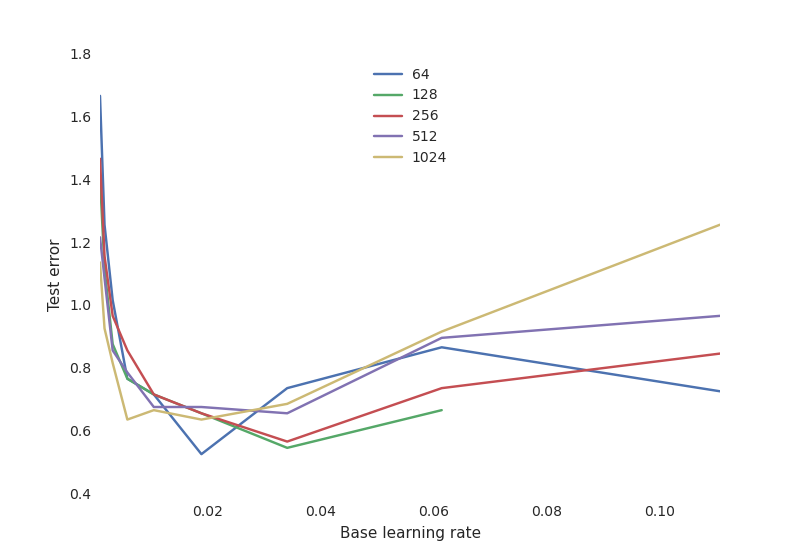
这显示了一个典型的神经网络权衡曲线:
- 学习速度是非常关键的:如果它太低,神经网络没有学到任何东西(高测试误差)。如果它太高,训练过程可能发生随机振荡甚至在某些配置下出现发散。
- 神经元的数目对于获得良好的性能来说没有那么重要,并且有更多神经元的网络的学习率更加敏感。这是奥卡姆剃刀原则:对大多数目标来说,简单的模型往往已经“足够好”。如果你有时间和资源来除去这缺少的1%测试误差,在训练中投入了大量的资源,并找到合适的超参数,这才会有所不同。
通过使用参数稀疏样本,我们可以在最优的参数集下取得零失误率。
我该如何使用它?
尽管 TensorFlow 可以使用每一个 worker 上的所有核心,我们只能在同一时间对每个工人运行一个任务,我们将它们打包以限制竞争。TensorFlow 库可以按照[instructions on the TensorFlow website](https://www.tensorflow.org/get_started/os_setup.html)上的指示安装在 Spark 集群上作为一个普通的Python库。下面的笔记展示了如何安装TensorFlow并让用户重复该文章的实验:
- Distributed processing of images using TensorFlow
- Testing the distribution processing of images using TensorFlow
大规模部署
TensorFlow 模型可以直接在管道内嵌入对数据集执行复杂的识别任务。作为一个例子,我们将展示我们如何能够使用一个已经训练完成的股票神经网络模型标注一组图片
首先使用 Spark 内置的广播机制将该模型分发到集群中的worker上:
with gfile.FastGFile( 'classify_image_graph_def.pb', 'rb') as f:
model_data = f.read()
model_data_bc = sc.broadcast(model_data)
之后,这个模型被加载到每个节点上,并且应用于图片。这是每个节点运行的代码框架:
def apply_batch(image_url):
# Creates a new TensorFlow graph of computation and imports the model
with tf.Graph().as_default() as g:
graph_def = tf.GraphDef()
graph_def.ParseFromString(model_data_bc.value)
tf.import_graph_def(graph_def, name='')
# Loads the image data from the URL:
image_data = urllib.request.urlopen(img_url, timeout=1.0).read()
# Runs a tensor flow session that loads the
with tf.Session() as sess:
softmax_tensor = sess.graph.get_tensor_by_name('softmax:0')
predictions = sess.run(softmax_tensor, {'DecodeJpeg/contents:0': image_data})
return predictions
通过将图片打包在一起,这份代码可以运行地更快。
下面是图片的一个样例:

这是神经网络对于这张图片的解释,相当精确:
('coral reef', 0.88503921),
('scuba diver', 0.025853464),
('brain coral', 0.0090828091),
('snorkel', 0.0036010914),
('promontory, headland, head, foreland', 0.0022605944)])
期待
我们已经展示了如何将 Spark 和 TensorFlow结合起来训练和部署手写数字识别和图片分类的神经网络。尽管我们使用的神经网络框架自身只能在单节点运行,但我们可以用 Spark 分发超参数调节过程和模型部署。这不仅缩短了训练时间,而且还提高了精度,使我们更好地理解各种超参数的灵敏度。
尽管这支持是只适用于Python的,我们仍期待着可以提供 TensorFlow 和 Spark其它框架之间更深度的集成。