推荐系统的分类:
基于应用领域分类:电子商务推荐,社交好友推荐,搜索引擎推荐,信息内容推荐
基于设计思想:基于协同过滤的推荐,基于内容的推荐,基于知识的推荐,混合推荐
基于使用何种数据:基于用户行为数据的推荐,基于用户标签的推荐,基于社交网络数据,基于上下文信息(时间上下文,地点上下文等等)
协同过滤:
协同过滤的基本思想(基于用户):
协同过滤一般是在海量的用户中发掘出一小部分和你品味比较类似的,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的其他东西组织成为一个排序的目录作为推荐给你
核心问题:
如何确定一个用户是不是和你有相似的品味?
如何将邻居们的喜好组织成一个排序的目录?
实现协同过滤的步骤:
收集用户偏好
找到相似的用户或物品
计算推荐(基于用户,基于物品)
收集用户偏好的方法:

通过收集用户把用户的特征变成向量(一般变成向量前需要降噪(抛去或者修改),归一化)
相似度:
当已经对用户行为迚行分析得到用户喜好后,我们可以根据用户喜好计算相似用户和物品,然后基于相似用户戒者物品迚行推荐,这就是最典型的CF 的两个分支:基于用户的CF 和基于物品的CF。这两种方法都需要计算相似度
把数据看成空间中的向量(降噪,归一化)
距离的计算:
欧几里得距离
其它距离
基于距离计算相似度:

基于相关系数计算相似度:
皮尔逊相关系数:

基于夹角余弦计算相似度:

基于Tanimoto系数计算相似度:

同现相似度:

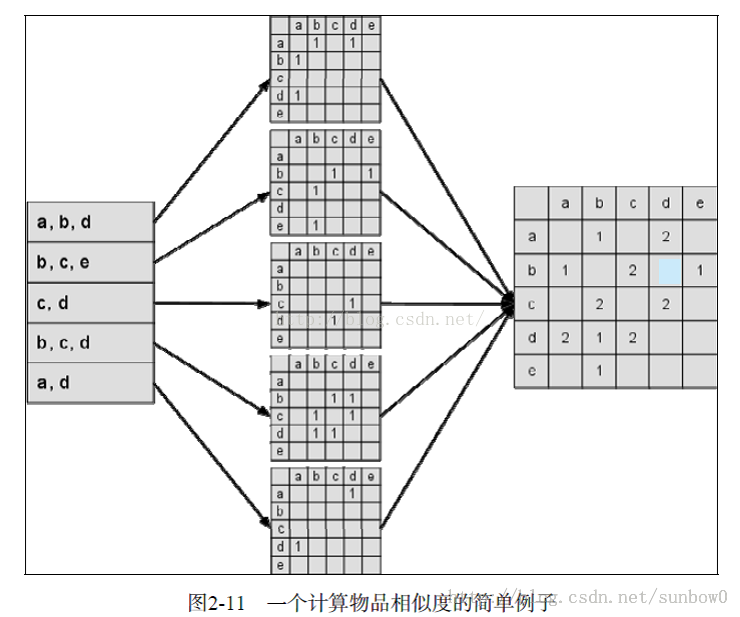
同现相似度模型:根据用户评分数据表,生成物品的相似矩阵;
邻居(用户,物品)的圈定:
固定数量的邻居:K-neighborhoods
基于相似度门槛的邻居:Threshold-based neighborhoods