豆瓣电影推荐系统(Ⅰ)算法原理
来自github上的一个推荐系统项目的学习笔记,主要通过python与mysql实现,不足之处望读者多多指正
前言
关于推荐系统,主流算法主要有
- 基于用户(UserCF)
- 基于物品(ItemCF)
- LFM隐语义模型
- 二分图模型等,
这里项目使用的算法是基于物品的推荐算法(ItemCF),优点是对于具有大量用户的推荐系统计算量相对于UserCF。
ItemCF算法原理
常用术语(评价指标)
假设对用户u推荐N个物品(记为R(u)),令用户在物品集中喜欢的物品集合为T(u),评价算法的两个指标为:
- 召回率(Recall):Recall= ∑ u ∣ R ( u ) ∩ T ( u ) ∣ ∑ u ∣ T ( u ) ∣ \frac{\sum_{u}|R(u) \cap T(u)|}{\sum_{u}|T(u)|} ∑u∣T(u)∣∑u∣R(u)∩T(u)∣;描述的是用户的评分记录在喜欢列表中所包含的比例。
- 准确率(Precision):Precision= ∑ u ∣ R ( u ) ∩ T ( u ) ∣ ∑ u ∣ R ( u ) ∣ \frac{\sum_{u}|R(u) \cap T(u)|}{\sum_{u}|R(u)|} ∑u∣R(u)∣∑u∣R(u)∩T(u)∣;描述的的推荐列表的用户评分的比例。
- 覆盖率(Coverage):Coverage = U u ∈ U R ( u ) ∣ ∣ I ∣ =\frac{U_{u \in U} R(u) \mid}{|I|} =∣I∣Uu∈UR(u)∣
实现原理
基于物品的协同过滤算法主要分为两步。
(1) 首先计算物品之间的相似度;
(2)根据物品的相似度和用户的历史行为给用户生成推荐列表。
定义Wij为物品i与物品j之间的相似度,计算公式为: w i j = ∣ N ( i ) ∩ N ( j ) ∣ ∣ N ( i ) ∣ w_{i j}=\frac{|N(i) \cap N(j)|}{|N(i)|} wij=∣N(i)∣∣N(i)∩N(j)∣
其中N(i)表示喜爱物品i用户数量,N(j)为喜爱物品j的用户数量。
为了排除热门物品的影响,更好的挖掘挖掘长尾信息,使用改进的相似度公式为: w i j = ∣ N ( i ) ∩ N ( j ) ∣ ∣ N ( i ) ∣ ∣ N ( j ) ∣ w_{i j}=\frac{|N(i) \cap N(j)|}{\sqrt{|N(i)||N(j)|}} wij=∣N(i)∣∣N(j)∣∣N(i)∩N(j)∣
据此可以得到空闲矩阵C(C[i] [j]表示喜欢物品i与物品j的用户数量):算例如下图:
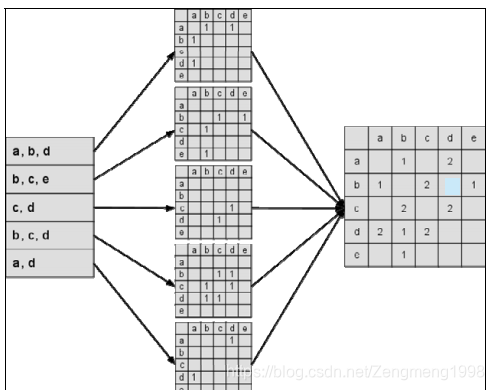
再将矩阵C归一化可以得到物品之间的余弦相似矩阵W。
得到物品间的相似度后,再计算用户u对一个物品j的兴趣,计算公式:
其中N(u)为用户喜欢的物品集合,S(j,k)为物品j最相似的K个物品集合,wij为物品i、j间的相似度,rui为用户u对物品i的兴趣,对于隐反馈数据集,如果用户u对物品i有过行为,即可令rui=1,该公式的含义是,和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。该公式的实现代码如下所示。
一个例子:

与UserCF比较
