本文导读
- 本文承接《Solr 4.10.3 集成 IK Analyzer 2012FF 中文分词器》,在 Solr 集成 中文分词器之后,现在来掌握 Solr 批量导入 Mysql 数据
- 使用 Dataimport 插件批量导入数据库数据,步骤如下:
- 第一步:把 dataimport 插件依赖的 jar 包添加到 solrcore(如collection1)下的 lib 目录中,包括 Mysql 连接驱动包。
-
第二步:配置 solrconfig.mxl 文件,添加一个数据导入的 requestHandler。
-
第三步:创建一个 data-config.xml,保存到 collection1\conf\ 目录下 ,用于连接数据库,以及字段转换。
-
第四步:重启 tomcat,进行数据导入
环境准备
准备数据库
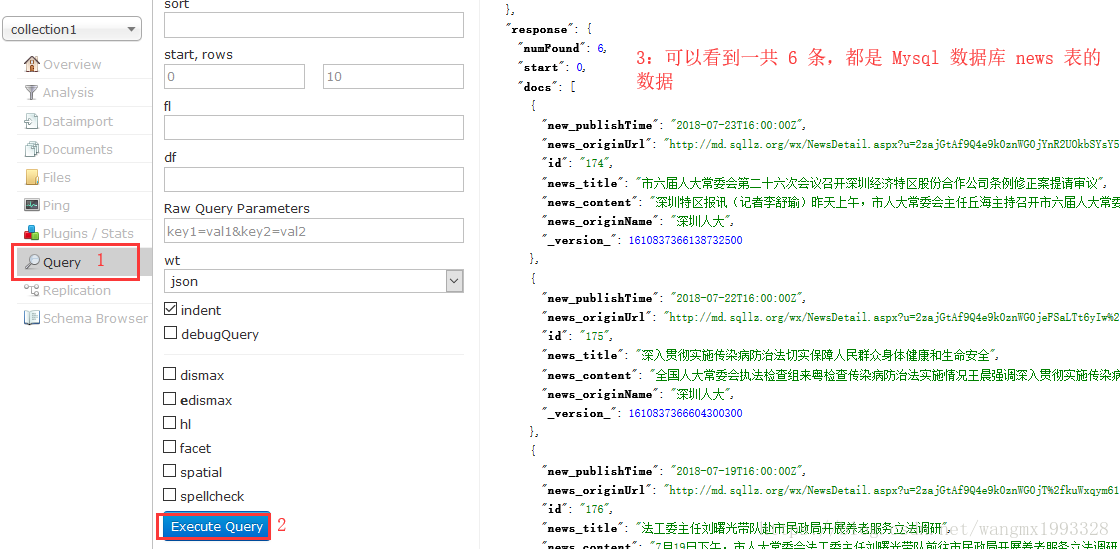
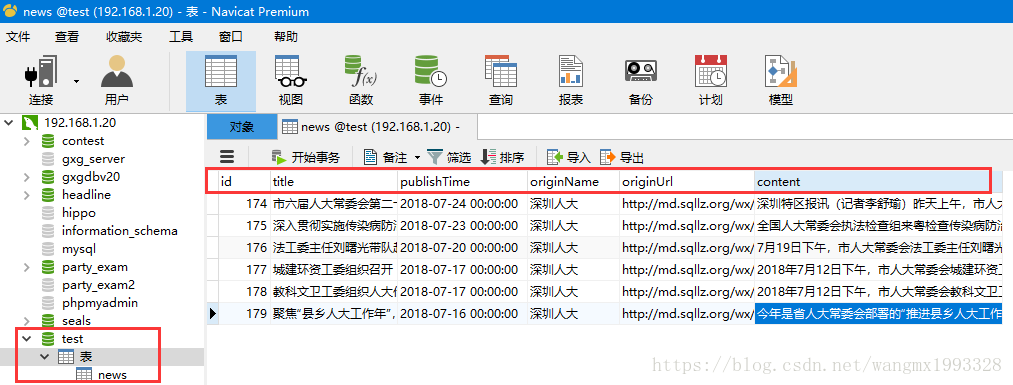
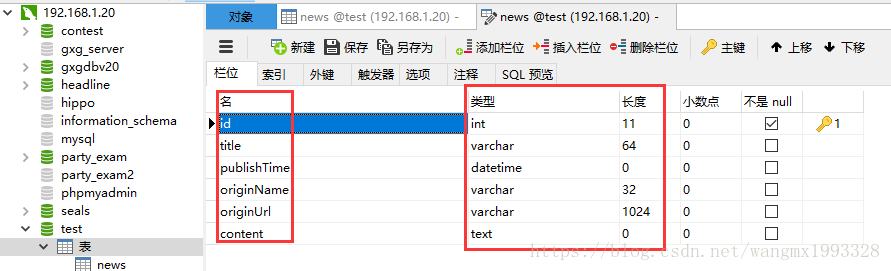
- 需求很明确:就是将 Mysql 数据库中的表数据批量导入到 Solr 文档中。
- 以如下所示的数据库表数据为例,表字段的数据类型将来会和 Solr 的 FieldType 进行转换。
自定义文档域
- 无论是否导入 Mysql 数据到 Solr 中,实际项目中通过 Solr 进行全文检索 或者 文档保存时,都应该先创建 Field 与 FieldType,如果不熟悉可以参考《 Solr 4.10.3 schema.xml 域类型详解》
- 文档域都是 先创建,后使用,虽然 Solr 的 schema.xml 文件本身已经自带了一些,但是为了更加清晰,建议新建。
- 如同 应用中约定好 POJO 类之后,就会新建 Mysql 数据库表一样,Solr 同样需要定义与 POJO 对应的域。

<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<!--IKAnalyzer Field-->
<field name="title_ik" type="text_ik" indexed="true" stored="true" multiValued="true"/>
<field name="content_ik" type="text_ik" indexed="true" stored="true" multiValued="true"/>
<field name="name_ik" type="text_ik" indexed="true" stored="true"/>
<!-- New Entity -->
<field name="news_title" type="text_ik" indexed="true" stored="true"/>
<field name="new_publishTime" type="date" indexed="true" stored="true"/>
<field name="news_originName" type="text_ik" indexed="true" stored="true"/>
<field name="news_originUrl" type="string" indexed="true" stored="true"/>
<field name="news_content" type="text_ik" indexed="true" stored="true"/>
<field name="news_text" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="news_title" dest="news_text"/>
<copyField source="news_originName" dest="news_text"/>
<copyField source="news_content" dest="news_text"/>
</schema>
- name="news_title":虽然 Mysql 中是 “title”,但为了区别于 schema.xml 默认的 “title”,统一加上前缀为 “new_title”。
- type="text_ik":Ik-Analyzer 中文分词器,标题、来源网站名称、新闻内容 都需要采用中文分词
- name="news_publishTime":对应 Mysql 的 publishTime,域类型为 date(日期),可以参考 schema.xml 文件默认的如下一句:
<field name="last_modified" type="date" indexed="true" stored="true"/>
- name="news_originUrl" type="string":对应 Mysql 的 originUrl,这个自动表示新闻的来源地址,所以不需要中文分词,可以参考 schema.xml 中的其它配置,如:
<field name="content_type" type="string" indexed="true" stored="true" multiValued="true"/>
- name="news_content":对应 Mysql 的 content,因为 schema.xml 默认也有一个 content 域,所以建议不要一致。
- 《 Solr 4.10.3 schema.xml 域类型详解》中已经说过 <copyField 域的作用,schema.xml 中默认有一个叫 "text" 域,可以仿写,如上所示,这样以后检索 "news_text" 域的时候,等同于同时检索 news_title、news_originName、news_content。
集成 Dataimport 插件
导入 Jar 包
- 把 dataimport 插件依赖的 jar 包添加到 solrcore(如collection1)下的 lib 目录中,包括 Mysql 连接驱动包。
- dataimport 插件的 jar 包可以在下载好的 Solr 应用中的 dist 目录下找到
- mysql 数据库连接驱动包对于 Java 开发人员来说自然不能找。

- 如下所示,将准备好的 dataimport 插件包和 mysql 数据库驱动包,放入 SolrHome 下的 SolrCore 下的 lib 目录中,lib 目录默认是没有的,手动新建即可

配置 solrconfig.xml
- 配置 solrconfig.mxl 文件,添加一个数据导入的 requestHandler
- 如下所示是 "/dataImport" 内容部分,添加的位置与 solrconfig.xml 默认已经存在的请求同级即可,如 "/select" 就是默认存在的请求。
<!-- SearchHandler
http://wiki.apache.org/solr/SearchHandler
For processing Search Queries, the primary Request Handler
provided with Solr is "SearchHandler" It delegates to a sequent
of SearchComponents (see below) and supports distributed
queries across multiple shards
-->
<!-- Data Import wangMaoXiong -->
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
<requestHandler name="/select" class="solr.SearchHandler">
<!-- default values for query parameters can be specified, these
will be overridden by parameters in the request
-->
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
<str name="df">text</str>
</lst>创建 data-config. xml
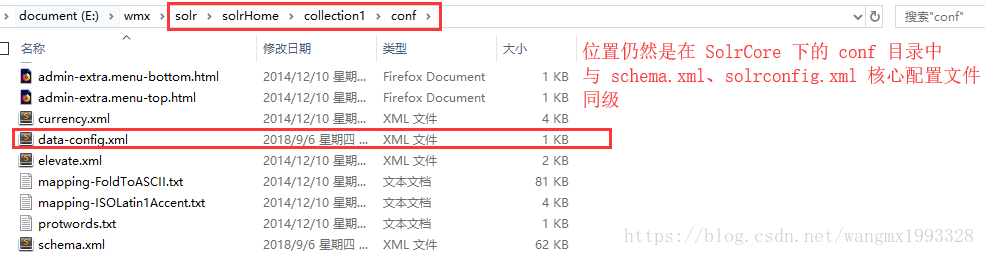
- 创建一个 data-config.xml,保存到 collection1\conf\ 目录下 ,用于连接数据库,以及字段转换。
- data-config.xml 这个文件名称可以自取,保持和 solrconfig.xml 中配置的一样即可,内容如下:
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/test"
user="root"
password="root"/>
<document>
<entity name="news" query="SELECT id,title,publishTime,originName,originUrl,content FROM news">
<field column="id" name="id"/>
<field column="title" name="news_title"/>
<field column="publishTime" name="new_publishTime"/>
<field column="originName" name="news_originName"/>
<field column="originUrl" name="news_originUrl"/>
<field column="content" name="news_content"/>
</entity>
</document>
</dataConfig>
- <dataSource:连接数据库的配置信息,配置数据源
- <document:Solr 文档配置
- <entity:实体类配置
- name="news" :POJO 名称
- query=xxx:查询被导入 Mysql 数据库表数据的 SQL,需要哪些字段就查询哪些字段。
- <field column="xxx" name="yyy":表示 Solr 域 与 Mysql 字段的对应关系。column 的值是 Mysql 数据库表的字段名;name 的值是 SolrCore 下的 schema.xml 中事先定义好的 Field(域)。
重启 Tomcat 导入数据
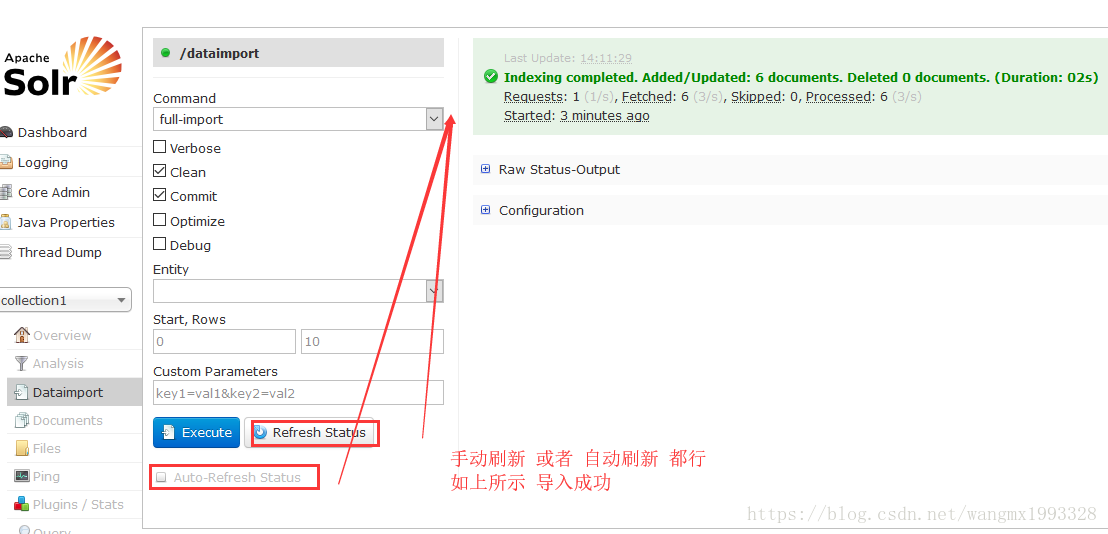
- 重启部署了 Solr 应用的 Tomcat 服务器,然后访问 Solr

- Command->full-import:全部导入
- Clean:清理,意思是导入数据之前,会先删除 Solr 中原来的所有数据,默认是勾选的,如果需要保留 Solr 中原来的数据,则切记要取消勾选。
- Commit:提交,即执行数据导入的时候自动提交,默认勾选
- Optimize:优化
- Entity:实体,即 data-config.xml 文件中配置的 <entity 实体,可以选择其中一个实体进行导入,不选时,表示执行所有实体导入。
- Execute:执行,点击按钮之后就会开始数据导入
- Redresh Status:刷新状态,点击 Execute 按钮执行数据导入后,默认状态是不会自动刷新的,此时可以点击此按钮进行刷新
- Auto Refresh Status:勾选之后,点击 Execute 按钮执行数据导入,此时就会自动刷新状态