(一)配置dataimport步骤
1、所需jar包: 可在solr-4.10.4\dist目录下copy
1) solr-dataimporthandler-extras-4.10.4.jar;
2) solr-dataimporthandler-4.10.4.jar;
3)mysql-connector-java-5.1.18.jar;自己下载
将jar包放在...\solrhome\collection1\lib
2、修改solr的核心配置 :
E:\solrhome\collection1\conf\
之前创建的solrhome下的配置文件中:需要更改3个地方:
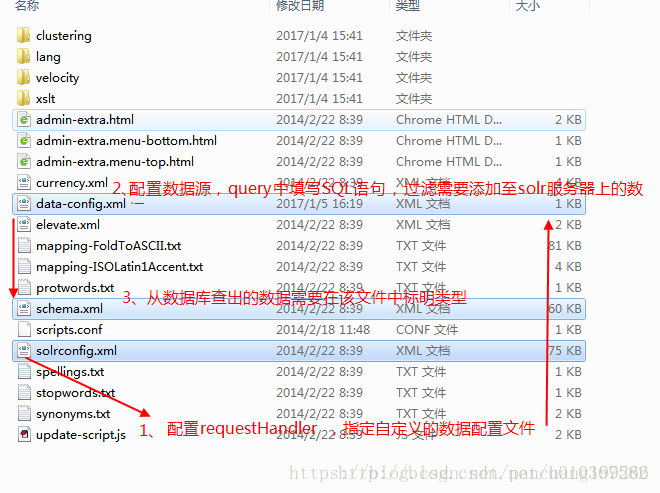
2.1)首先是solrconfig.xml文件,添加如下这段配置:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler> 指向一个自定义文件:data-config.xml,顾名思义,是配置相关数据源的。
2.2)然后在当前目录下新建data-config.xml文件,添加如下这段配置:
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/kindle"
user="root"
password="root"/>
<document>
<entity name="book" query="SELECT id,name,content,author,tags from book">
<field column="id" name="id"/>
<field column="name" name="book_name"/>
<field column="content" name="book_content"/>
<field column="author" name="book_author"/>
<field column="tags" name="book_tags"/>
</entity>
</document>
</dataConfig>2.3)最后的一个文件配置是修改schema.xml文件,添加在data-config中定义的字段,如果已经存在如id,name,则可不用重新添加。 备注:其中的type类型是我们引入的中文分词器自定义类型!
<field name="name_com" type="text_mmseg4j_complex" indexed="true" stored="true"/>
<field name="name_max" type="text_mmseg4j_maxword" indexed="true" stored="true"/>
<field name="name_sim" type="text_mmseg4j_simple" indexed="true" stored="true"/>
<!-- book 自定义-->
<field name="book_name" type="text_mmseg4j_complex" indexed="true" stored="true"/>
<field name="book_content" type="text_mmseg4j_complex" indexed="true" stored="false"/>
<field name="book_author" type="text_mmseg4j_complex" indexed="true" stored="true"/>
<field name="book_tags" type="text_mmseg4j_complex" indexed="true" stored="true"/>
<!-- 拷贝域:将book_name和book_content放到一个字段,实现多条件检索。比如查询“文化”,既在书名(book_name)中找,又在书籍简介(book_content)里找-->
<field name="book_keywords" type="text_mmseg4j_complex" indexed="true" stored="false" multiValued="true"/>
<copyField source="book_name" dest="book_keywords"/>
<copyField source="book_content" dest="book_keywords"/>3、最后一步,全量或者增量导入数据:
启动tomcat,选择collection1,选择dataimport命令界面:
我们可以选择是全量导入还是增量导入,并且选择配置好的实体。