国内人工智能处理器独角兽寒武纪,在这个领域,算是走在了世界前沿,经过最近几年的迅猛发展,取得了辉煌的成果。
最近花了些时间研究了下寒武纪发表的一系列论文中介绍的NPU的结构。
记录下来,算是对最近学习内容的总结。
寒武纪从2014年开始,发表了一系列的论文,本文仅分析其中几篇:
(1)DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning
(2)DaDianNao: A Machine-Learning Supercomputer
(3)PuDianNao: A Polyvalent Machine Learning Accelerator
(4)ShiDianNao: Shifting Vision Processing Closer to the Sensor
(5)Cambricon-X: An Accelerator for Sparse Neural Networks
感谢寒武纪的分享!!
一、DianNao
这是寒武纪的开山之作。
本文所谓的人工智能处理器,是指专门处理人工智能算法的专属芯片。
最开始,广泛采用高性能CPU去计算,但是太慢了,于是有采用GPU去计算,发现速度明显提升,于是许多这类计算都基于成熟的GPU平台,这也是这几年NVIDIA股票起飞的主要原因之一。
但是GPU其实并不是专为人工智能算法而设计的,只能说是恰逢其会,自然就有许多不是那么高效的地方。
导致在加速人工智能算法时,虽然GPU比CPU快得多,但是速度还不够,功耗也很大,还有很大的提升空间。
为人工智能专用处理器的出现,埋下了伏笔。
下面先简单说说人工智能算法中主要涉及到的计算类型。
目前,人工智能算法主要的应用方向可以看成2个方面:(1)计算机视觉,也叫图像识别,属于平面二维数据的处理,具体的特征是某个像素与其周围上下左右的元素都有关系,这类问题一般采用CNN计算;(2)自然语言处理(语音识别,自同声传译,语义识别等),这种属于线性时序数据特征,也就是说这些数据有先后顺序,但是不存在上下关系,这类问题一般采用RNN计算,比如LSTM。
CNN与RNN的计算,分解开来,都可以看作大量矩阵乘法及向量对应元素相乘等基本计算。
以CNN计算为例,CNN计算可看作filter矩阵的每个元素与待识别图像的每个小块的对应元素对应相乘并累加,简单来看,就是两个向量对应元素相乘并累加。
文字描述很抽象,下面举个简单例子。
假设filter是A[3,3],尺寸是3X3,图像的某个小块是B[3,3],尺寸也是3X3,再加一个bias。
那么对应的CNN计算C如下:
C = A[3,3] X B[3,3] + bias
= a[0,0] * b[0,0] + a[0,1] * b[0,1] + … + a[2,2] * b[2,2] + bias
可以看出,为了计算得到C,中间包括9个乘法,9个加法。
如果是传统的CPU,那么一般一次只能计算一个乘法,就算是最先进的服务器用超标量CPU,data128bit宽,执行SIMD指令,也就最多同时计算4个定点乘法(32位的乘法),那么光是计算乘法,就需要3个周期,然后又需要几个周期计算加法。
或许有人会好奇,CPU那么强大,怎么可能一次只能计算最多4个乘法?
其实,CPU是为处理各种不同任务设计的,这就造成CPU内部有许多功能逻辑单元,应该说能用到的常用计算功能,比如定浮点的加减乘除/开方/求倒等常规操作,CPU内部都实现了,但是通常同一种功能只会有一套逻辑,最多4套,比如最常用的32位定浮点乘法计算,其他的计算,可能就只有一套,这就造成CPU可以执行各种复杂的计算,但是针对某种类型的计算任务,就不那么高效了。
为啥不多准备几套计算资源?
因为成本原因,芯片面积是有限的,在有限的面积上,只能放置有限的资源,而且,大部分时候,很多计算资源的使用率并不高,这也是一种浪费。
芯片设计,为了商业利益,可不会讲究养兵千日用兵一时。
好了,接下来,就来看看寒武纪的DianNao的内部结构。

基于神经网络的人工智能算法,是模拟人类大脑内部神经元的结构。
上图中的neuron代表的就是单个神经元,synapse代表神经元的突触。
这个模型的工作模式,就要结合高中生物课的知识了。
应该还记得吧,一个神经元,有许多突触,给别的神经元传递信息。同样,这个神经元,也会接收来自许多其他神经元的信息。这个神经元所有接受到的信息累加,会有一个强烈程度,在生物上是以化学成分的形式存在,当这些信息达到一定的强烈程度,就会使整个神经元处于兴奋状态(激活),否则就是不兴奋(不激活)。如果兴奋了,就给其他神经元传递信息,如果不兴奋,就不传递。这就是单独一个神经元的工作模式。那么有成千上万个这样的神经元组合起来,就是一个神经网络模型。
下面就来看看DianNao的内部结构。

上图中央浅蓝色部分就是用硬件逻辑模拟的神经网络结构。
整个称为NFU(Neural Functional Units)。
分为三个部分,NFU-1,NFU-2,NFU-3.
NFU-1全是乘法单元。16X16=256个乘法器。这些乘法器同时计算,也就是说,一个周期可以执行256个乘法。
NFU-2是加法树。16个。每个加法树是按照8-4-2-1这样组成的结构。每个加法数有15个加法器。
NFU-3是激活单元。16个。
可以看出,NFU的所有逻辑资源,可以整体划分为16份,每一份,包括16个乘法器,15个加法器,1个激活。它的运算过程是,16个乘法器同时计算出16个结果,送给加法树(最左的8个加法器,每个有2个输入,恰好接收16个输入),形成一个结果,然后再送入激活。
NFU-1和NFU-2目的是计算出单个神经元接受到的所有刺激的量。
NFU-3是根据前面两个单元计算得到的刺激量,去判断是否需要激活操作。
除了这三个阶段的计算逻辑,剩下还有三个Buffer。一个存储输入数据,一个存储权值(filter值),一个存储计算结果。
整体来说,结构还是比较简明的。
看起来也不复杂,但是因为是ASIC,少了许多不必要的逻辑功能,所以速度就是快,功耗就是低,效果就是好。
毕竟人家ASIC是专业的。
DianNao的出现,性能甩了CPU好几百条街,就算是GPU,那也是好几十条街。
在当时,引起巨大的震动。
开启了深度学习神经网络专用处理器的先河。
之后,迅速涌现出许多不同的架构。
包括谷歌的TPU。
是滴,大名鼎鼎的TPU,面世也要晚于DianNao。
另外,也就是在DianNao面世的2014年,谷歌将参与了DianNao研发的法国专家挖到了谷歌主持研发TPU。
如果说TPU某种程度上借鉴了DianNao的经验,也是说得过去的。
二、DaDianNao
DaDianNao的诞生稍晚于DianNao,同样也是在2014年。(这里仅仅指论文发表时间)
如果把DianNao看作是嵌入式终端使用的处理器,那么DaDianNao就是服务器上用的大规模高性能处理器。
DaDianNao其实就是采用的DianNao的NFU作为内核,然后在一块芯片上同时放置了16个NFU,于是乎,性能也就是DianNao的16倍。
文章说,在DaDianNao的设计过程中,首先想到的是,直接将DianNao中NFU的逻辑资源扩大成原来的16倍即可简单实现性能16倍的提升。但是这里就要考虑芯片上实际的晶体管布局及布线。发现,如果单纯扩大NFU规模,那么最终布线所占用的芯片面积远远超过NFU逻辑模块,貌似并不高效,如下图中的Figure4所示。
于是乎,就想到了多核并行的架构。
将上面的大NFU拆分成16个小NFU(DianNao),通过合理布局布线,能够大幅缩小布线需要的面积,最终面积的减小28.5%,而性能与上面的设计相同。
芯片上,那可真的是寸土寸金。
没说的,选第二种,也就是下图中的Figure5。

到目前为止(2018年),国内的人工智能公司,大部分还是局限在算法领域,并不关注底层硬件。少数几个大体量的AI独角兽,如寒武纪/商汤/深鉴/地平线/比特大陆等公司,都对芯片有不同程度的涉足。这其中,大部分公司的芯片都只是涉及到终端的推断(inference),而没有涉足训练(training),所以芯片设计比较简单。
相反,国外的科技巨头,比如谷歌/intel/NviDia/facebook等,都有涉足training的深度学习处理器的研发。
寒武纪是少数已经涉足training的中国企业。DaDianNao就是可以用于服务器上进行大规模training的专用芯片。
看好寒武纪!
三、PuDianNao
上面的DianNao和DaDianNao,其实内部处理逻辑可以说是一样的。
这种架构,只能适用特定的算法类型,比如深度学习(CNN,DNN,RNN)等。
但是,深度学习只是机器学习中的某一类,整个机器学习,有很多其他种类的算法,和深度学习的不太一样,甚至经常用到除法等计算类型。这些算法,目前的应用范围也很广。
为了加快常用机器学习算法的运算,寒武纪又设计出专门针对这些算法的处理器方案:PuDianNao.
PuDianNao,内部实现了7种常用的机器学习算法:k-means, k-nearest neighbors , naive bayes , support vector machine , linear regression , and DNN.
PuDianNao的结构如下图所示。
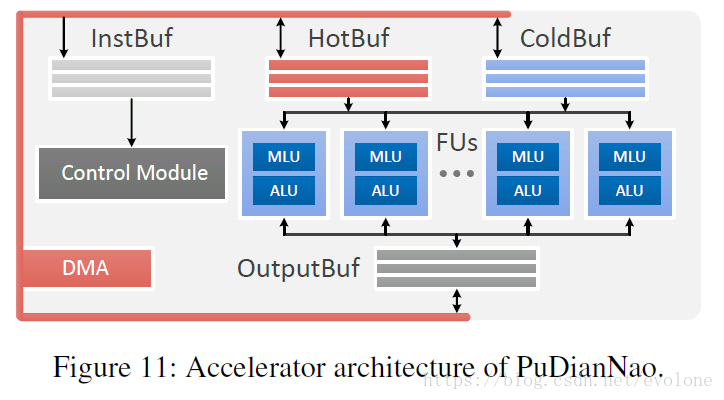
可以看出整体结构和DianNao比较像。
三个buffer存储数据,一个存储输出,2个存储输入。
核心是中间的运算逻辑。
PuDianNao的运算逻辑,可以看成由许多组相同的FU(Function Unit)并联组成。每个FU中包含一个MLU和一个ALU。
MLU结构如下图所示。
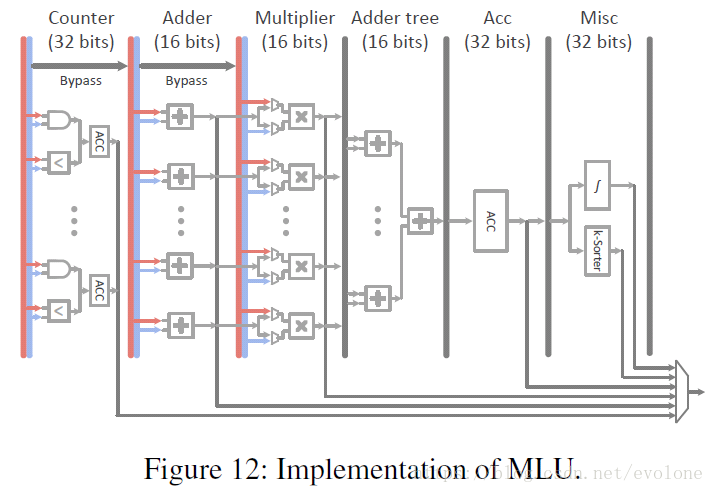
MLU
可以看出,MLU(Machine Learning Unit)的整体结构与DianNao的NFU比较像。
与NFU相比,PuDianNao在NFU-1的前面增加了2层逻辑Counter和Adder。
Counter用于累加,结果直接输出。Counter用于naive bayes 和 classification tree需要的。
Adder 用于大部分的机器学习算法,计算结果要么直接输出,要么作为下一级的输入。
Multiplier相当于DianNao的NFU-1.这里就不再赘述。
Adder tree相当于DianNao的NFU-2。
Acc,用于当计算的size大于硬件资源,比如需要累加30个输入,但是一次只能累加16个,所以需要连续累加2次,那么第一次的前16个的累加结果就暂时存在Acc中,等后面14个累加结果到了,再累加起来,形成30个输入的累加结果,直接输出或作为下一级的输入。这里与DianNao是有区别的。DianNao对这个问题的处理,选择将前16个输入的中间累加结果暂时存入NBout中,与剩下的14个输入一同完成累加,形成最终结果。二种方案的具体优劣,无从评判,但是个人感觉,PuDianNao增加了一级Acc,仅以很少的资源,比如一个累加器,几个控制信号,就能实现大size的计算,而DianNao的方案则需要将结果写入NBout,读写存储是很消耗功耗的,并且需要的布线资源也不少,信号传输需要时间,可能综合来看,个人觉得还是PuDianNao的方案更加高效。当然,这个判断并没有经过实际仿真验证,仅仅是一点直觉。当不得准。
Misc,相当于DianNao的NFU-3。
可以看出,MLU中的逻辑,只能执行乘法/加法/激活等操作,但是某些机器学习算法需要用到除法等不常用的计算类型。于是,必须增加对这些计算类型的支持。
ALU
PuDianNao选择在MLU之外,额外增加一个ALU(Arithmetic Logic Unit).
ALU中包含一个加法器,一个乘法器,一个除法器,一个converter。
增加ALU也很合理,毕竟有些机器学习算法,需要特殊的计算,不得不准备专门的逻辑资源,以保证算法功能得到正确执行。
四、ShiDianNao
ShiDianNao的出现是寒武纪在深度学习处理器上细分领域的更加深入。
前面介绍的DianNao针对的是大部分的深度学习神经网络算法,包括CNN和RNN等。
目前比较火而且应用面非常广的领域是计算机视觉,若在这个领域的算法精度实现巨大突破,那么,就将开启广阔的应用领域。比如自动驾驶/安防等等,利润丰厚的领域。
图像识别,这类算法主要采用CNN结构。
于是乎,开发专门针对CNN的ASIC就变得可行且有商业价值。
寒武纪为何在已经有了DianNao的基础上,还要设计ShiDianNao?
先来分析下,目前DianNao存在的缺陷。
众所周知,深度学习类的算法都是计算密集型和存储密集型。
这就造成了不低的功耗。
当这类芯片应用到终端嵌入式设备上有许多限制,比如智能手机,对芯片功耗有着严苛的要求。
因为DianNao中的数据会存储在DRAM中,而DRAM的读写会消耗非常大的功耗。
如果能够避免用DRAM存储数据,那么就能很大程度上降低功耗。
是的,就是基于这个想法,ShiDianNao诞生了。
ShiDianNao的想法就是,在实际应用时,将用于图像识别的人工智能处理器在物理位置上比较靠近图像来源(CMOS/CCD传感器),这样就避免了图像数据需要DRAM的存储。
另外,对于CNN算法,其中常用的一类CNN是共享权值的,这样权值的数量就不大,可以完整存放在片上SRAM中,从而使得权值也能避免存储在DRAM中。
这样处理后,整个系统就不需要DRAM做存储,从而大幅降低功耗。

上图将Acc(人工智能处理器)放置在离传感器很近的位置,直接从传感器获取图像数据,避免了DRAM的使用。
ShiDianNao架构
ShiDianNao的架构如下图所示。

整个架构与DianNao一脉相承。三个buffer分别存储权值/输入数据/输出数据。
核心逻辑是右边的NFU,也就是PE阵列。PE(processing elements),是最小的处理单元。
NFU的内部结构如下图所示。

从上图可以看出,权重是同时广播到所有的PE,输出也是同时传递到output,而输入数据则配合每个PE内部的两个fifo,有不同的输入规律,有时一次给所有PE提供输入,有时又只给一列提供输入其余列靠相邻右边的fifo提供,有时又给一列提供输入其余列靠相邻下方的PE的fifo提供。
单个PE结构如下图所示。

ShiDianNao与TPU1对比
与TPU的脉动矩阵相对比,发现二者都共用了权重和输入数据。但是细细分析,还是觉得TPU的脉动矩阵更加优秀高效。
比如,二者都共用了权值,ShiDianNao是统一获取权值,然后同一周期广播到所有PE。受限于信号在导线中传递速度,信号完整性以及时序同步的问题,ShiDianNao的PE阵列无法做到比较大的规模,且规模越大,需要的传输布线长度约长,传输时间越久,因此频率也无法做到很高。而且,每个PE都是单独出结果,也就是说,在PE阵列中央的PE也要直接给输出传递数据,这就意味着需要不菲的布线资源。所以,ShiDianNao的缺点还是比较明显的。
再比如,二者都共用了输入数据。ShiDianNao是在PE内部有两个FIFO来存储多个输入数据。而且因为输入数据共享的方式有几种不同的情况,所以就造成了为了共享数据,不同时刻,数据的传递方向是不同的,比如,可能是按列,从右往左传递,也可能是按行,从下往上传递。而反观谷歌的TPU,采用了脉动阵列,于是,输入数据只需要从阵列的左侧进入,然后所有输入数据都从左往右依次传递,传递方式非常简单,也不需要在PE中内置FIFO。
几种不同的输入数据传递方式,见下图所示。

另外,脉动阵列只有最下面一行的PE会输出计算结果,只有最左边的一列会接受输入数据,整体来说,所需要的布线资源就少很多。另外,因为PE所需的输入数据/权重相关信息/中间计算结果,都来自邻近的PE,不需要很长的走线,且能够轻易做到相邻PE的距离相同,那么相邻PE之间的信号传递时间就完全一致,可以保持整个脉动阵列工作在非常高的频率。
总体来看,个人认为还是谷歌TPU的脉动阵列更加高效。
计算卷积
下面看看ShiDianNao是怎么计算的。
以卷积为例。

Figure13(a)显示了一个2X2的PE阵列。所以可以同时计算4个输出。所需输入数据如图右侧的4个不同颜色方框所示。中间则表示了从cycle0开始,每个cycle,给每个PE的输入数据。可以看出,其中有部分数据可以反复利用。于是,这就给增加FIFO来实现数据复用提供了可能。
Figure13(b)则配合图(a),给出了每个cycle,每个PE中的FIFO应该如何存储输入数据,以及输出数据复用。
这种方式有个缺点,一般而言,图像数据存储在RAM中,都是按照一张图的数据集中存储在一起,那么,取同一张图像上的某些像素点作为输入数据时,每个周期的像素地址并未对齐,无法在一个周期中获取该周期需要的所有有效数据,难以满足PE阵列的需求,会降低计算速度。
状态机
整个ShiDianNao的运行,会因为算法中的不同计算而有不同的控制方式,这就需要用到状态机,如下图所示。

引入状态机控制ShiDianNao工作,就可以采用指令集的方式,描述需要的操作,然后由状态机执行。
这一点,比较赞。
猜测寒武纪的一系列芯片应该都采用了这样的状态机进行控制。
五、Cambricon-X
Cambricon-X是针对稀疏系数的矩阵计算架构。
深鉴科技的韩松等人的研究发现,可以将传统的深度学习网络模型的许多权重系数去掉,甚至能去掉90%以上,而并不影响模型的计算精度。如下图所示。

目前的深度学习模型的权重系数太多,造成需要的乘法计算非常多,计算时间长,速度慢。
相信,未来的模型会更加复杂,需要的计算更多,时间更久。
未来把模型进行系数删减,就成了必然。
但是,删减了大量权值系数后,模型网络所需要的乘法计算次数明显变少,但是因为系数的稀疏带有不可控的随机性,不同filter的有效权重可能是不同位置的,所以,这就造成了大量权重并行计算时,无法做到同步,导致目前现有的处理器设计都并不能充分利用系数稀疏带来的加速效果。
Cambricon-X就是寒武纪在这个方面的一个探索。
Cambricon-X架构
下图为Cambricon-X的架构。

可以看出,整个架构还是和DianNao很像。
当然还是有不同的。
最大的不同是,为了利用到稀疏系数带来的加速效果,首先就需要将系数为0的权重所对应的输入数据去掉。这个,由Fig4中的Buffer Controller来实现。
Buffer Controller的具体结构见Fig5,主要由indexing实现数据的筛选。
Indexing从输入神经元数据(input neurons)中挑选出非0权重对应的输入数据,按顺序排列好,然后传输给对应的PE。然后,由PE去执行乘法/加法等操作。
PE结构如下图所示。

可以看到,PE中有个小SB,用于存放有效的权重。
权重的存储方式如下图所示。

假设每个地址。