今年5月份,谷歌CEO Sundar Pichai(劈柴哥)在谷歌IO大会上发布了TPU3.0芯片,声称其性能是上一代产品TPU2.0的8倍,达到了100Petaflops(Petaflops,每秒千万亿次浮点运算)。
在2016年的时候谷歌就发布了第一代TPU(Tensor Processing Unit),它是专门为机器学习定制的专用芯片(ASIC),一款谷歌自己高度定制化的AI芯片,也是为谷歌深度学习框架TensorFlow而设计的。傍着AlphaGo,TPU作为支撑起强大运算能力的芯片而闻名。今天,谷歌又宣布TPU3.0正式上岗了,进入Alpha内测阶段。

谷歌的TPU有多厉害?
这款芯片也是AlphaGo背后的功臣,即AlphaGo能以超人的熟练度下围棋都要靠训练神经网络来完成,而这又需要计算能力(硬件越强大,得到的结果越快),TPU就充当了这个角色,更重要的是借此显现出了在AI芯片领域相对于英特尔CPU和英伟达GPU的优势。也就是说,采用TPU之后的AlphaGo的运算速度和反应更快。
5年前,谷歌内部就开始使用消耗大量计算资源的深度学习模型,这对CPU、GPU组合而言是一个巨大的挑战,谷歌深知如果基于现有硬件,他们将不得不将数据中心数量翻一番来支持这些复杂的计算任务。
谷歌的专用机器学习芯片TPU处理速度要比GPU和CPU快15-30倍(和TPU对比的是英特尔Haswell CPU以及Nvidia Tesla K80 GPU),而在能效上,TPU更是提升了30到80倍。
TPU对比Haswell处理器
在和英特尔“Haswell”Xeon E5 v3处理器来的对比中,我们可以看到,TPU各方面的表现都要强于前者。
在Google的测试中,使用64位浮点数学运算器的18核心运行在2.3 GHz的Haswell Xeon E5-2699 v3处理器能够处理每秒1.3 TOPS的运算,并提供51GB/秒的内存带宽;Haswell芯片功耗为145瓦,其系统(拥有256 GB内存)满载时消耗455瓦特。
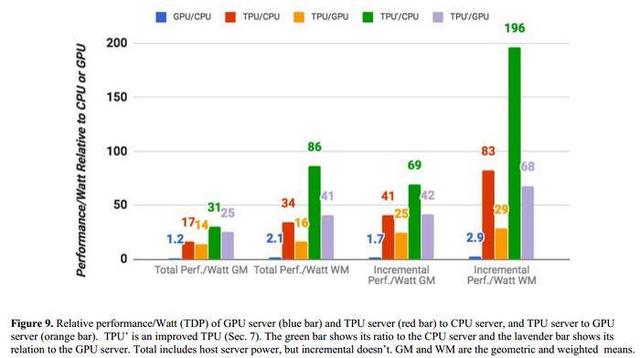
相比之下,TPU使用8位整数数学运算器,拥有256GB的主机内存以及32GB的内存,能够实现34GB/秒的内存带宽,处理速度高达92 TOPS ,这比Haswell提升了71倍,此外,TPU的热功率只有384瓦。
谷歌在人工智能领域的各种动作
谷歌越来越关注神经网络和人工智能,以解决搜索、图像处理和其他计算领域的问题。它也正在通过“AIY项目”这样的计划来促进开发人员和DIY社区对人工智能的兴趣,这些计划本身代表了人工智能。AIY Projects(AIY计划),其目标是让每个Maker(创客)都能DIY自己的 AI 人工智能产品,让更多人能学习、探索并体验人工智能。

比如今天上岗的TPU3.0,也传递着这样的信号。
谷歌的这一做法印证了一个芯片产业的发展趋势,即在AI负载和应用所占数据中心比重越来越大的今天和未来,像谷歌、微软、Facebook、亚马逊、阿里巴巴、腾讯等这些数据中心芯片采购的大户,其之前对于CPU和GPU的通用性需求可能会越来越少,而针对AI开发应用的兼顾性能和能效的定制化芯片需求则会越来越多。