初学神经网络第一个接触的实例一般都是XOR,很不错的入门练习。
理论部分
异或门:
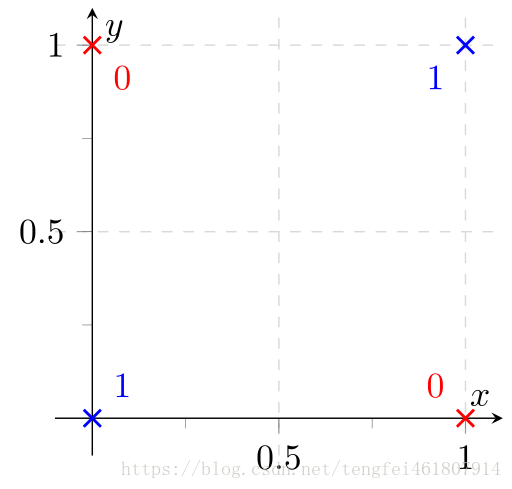
输入两个二进制值,如果两个值相同,结果为0,否则为1。
神经网络结构:
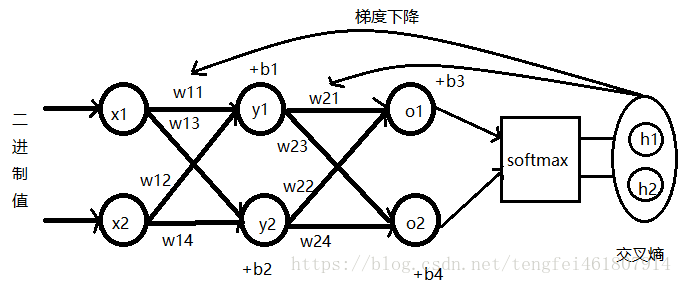
用矩阵来表示
输出得到的结果使用softmax计算结果的概率,该概率可以理解成和标准值的相似程度[p1,p2]。
然后,利用交叉熵得到计算使用神经网络“模拟”出的结果与真实结果之间的“距离”,再利用梯度下降函数反过来调整两个隐藏层中的参数,从而优化计算结果。
使用组件:
一个神经网络系统的基本组件如下
OneHotEncoder表达:
假设现在有一个集合{a,b,c,d},集合中有四个元素,每个元素是否存在使用一个4列1行01向量来表示。
例如,{a}表示为[1,0,0,0],即集合中第一个元素出现为1,其他元素未出现,为0。
同理,{b}为[0,1,0,0];{c}为[0,0,1,0];{d}为[0,0,0,1];{a,b}为[1,1,0,0],依次类推。
在程序中使用sklearn库中提供的onehotencoder来实现
from sklearn.preprocessing import OneHotEncoder假如,有一个标签如下:
labels = [0, 1, 1, 1, 0, 0, 1]建立一个onehotencoder对象
enc = OneHotEncoder()OneHotEncoder接受的参数类型是一个行扁平化的array,因此要将:
[0, 1, 1, 1, 0, 0, 1]
变为
[[0]
[1]
[1]
[1]
[0]
[0]
[1]]
形式设置函数来对原始list存储的标签进行转换
#后面的参数是-1表示不知道有多少列,但是想变成len(labels)行
def list_to_flat_array(labels):
return np.array(labels).reshape(len(labels), -1)使用如下函数,使sklearn中的onehotencoder对象确认标签中有多少个不同的组成:
例如[1,0,0,1]有两种组成,即0和1;[1,2,0,0,2]有三种组成,0,1,2
#flat_label是list扁平化后转换为array
enc.fit(flat_label)使用enc编码后会变成如下形式:
0用[1,0]表示
1用[0,1]表示
如果标签的组成有4种,例如[0,1,2]
那么0用[1,0,0]表示,1用[0,1,0]表示,2用[0,0,1]表示
输出结果
print(enc.transform(list_to_flat_array([0,1,0])).toarray().tolist())
'''
[[1.0, 0.0], [0.0, 1.0], [1.0, 0.0]]分别对应0,1,0
'''完整程序:
from sklearn.preprocessing import OneHotEncoder
import numpy as np
labels = [0, 1, 1, 1, 0, 0, 1]
enc = OneHotEncoder()
#后面的参数是-1表示不知道有多少列,但是想变成len(labels)行
def list_to_flat_array(labels):
return np.array(labels).reshape(len(labels), -1)
labels_r = list_to_flat_array(labels)
print(labels_r)
enc.fit(labels_r)
'''
labels_r为:
[[0]
[1]
[1]
[1]
[0]
[0]
[1]]
只有两种值1和0
那么将这个列编码后得到两种onehot
分别是
[1,0]和[0,1]分别表示值为0和值为1
'''
print(enc.transform(list_to_flat_array([0, 1,0])).toarray().tolist())placeholder:
在调用时由run方法向其传递数据,参数有三个:
dtype:数据类型,必选的
shape:数据的形状,比如是一个几维的数据。输入一个列表,例如[1,2]表示存储一个1行2列的数据,输入[None,2]表示一个不知道多少行,但是有2列的数据。
name:名称,就是给起个名。
Variable:
传递初始值,使用前要初始化。
参数有很多,这里用到了两个,分别是initial_value和name
initial_value:填入一个任意形状的初始值
name:起名
random_uniform:
获得一个随机分布的值,主要参数:
shape:输入一个列表表示你想要一个什么形状的随机数矩阵。
minval:随机数取值范围的下限
maxval:随机数取值范围的上限
seed:随机数种子发生器,输入一个整数
name:命名
sigmoid:
激活函数,神经网络和机器学习中常用的函数。直观上是将输出的数据,利用激活函数映射到的一个区间范围当中,例如映射到区间[0,1]上,或者看作是对结果产生了多大变化的一个表示。
理论上,激活函数把神经网络的线性结构添加了上了一个非线性结构。这也是神经网络为什么能拟合异或操作或者很多曲线的原因。
就是把数据带入公式
参数很简单,就俩:
x:表示输入的一个矩阵、张量等等
name:命名
softmax:
很有名的分类函数,这个函数具体是怎么来的可以看andrew ng的公开课,里面详细的讲了这个函数的推导出来的过程。
该函数可以实现多个标签的分类,给出每个标签的所占概率,概率总和为1。例如,有三个标签a,b,c,现在通过一大堆计算,想要判断最后得到的结果时属于哪个标签的? 使用softmax函数得到了属于各个标签的概率是a=0.6,b=0.3,c=0.1。很明显,结果应该属于a。
参数两个
x:输入一个矩阵、张量
name:命名
结果返回一个array,里面是每个标签对应的概率。
reduce_sum:
累加求和使用的函数和python当中reduce差不多
参数主要有input_tensor和axis
input_tensor:表示输入的张量
axis:表示依照哪个轴进行求和
在程序中计算交叉熵时使用到。
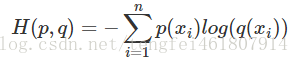
p是第i个数据 的真实概率,q是使用神经网络计算出来的概率。 得到的交叉熵时两个概率的“距离”。
GradientDescentOptimizer:
tensorflow中的优化器,梯度下降函数,具体的梯度下降原理资料非常丰富,使用范围也很广泛。目的就是为了寻找一个局部的极值,输入参数是学习率,表示寻找极值的速率,参数太大会过快收敛,找到一个很烂的极值,参数太小速度太慢。
本程序中利用得到的交叉熵来寻找极值,从而使隐藏层中的参数能够找到适合异或的参数值。
global_variables_initializer:
用于变量初始化和更新操作。
一般不用啥参数,神经网络的标配函数。
Session:
提供神经网络程序操作的和张量的执行环境,神经网络程序标配函数。
run:
可以简单的理解成开始执行程序,参数里面一般放置global_variables_initializer,同样的标配函数。
程序:
#!/usr/bin/env python
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import OneHotEncoder
def list_to_flat_array(labels):
return np.array(labels).reshape(len(labels), -1)
def analyze_classifier(sess, i, w1, b1, w2, b2, XOR_X, XOR_T):
print('\nEpoch %i' % i)
print('Hypothesis %s' % sess.run(hypothesis,
feed_dict={input_: XOR_X,
target: XOR_T}))
print('w1=%s' % sess.run(w1))
print('b1=%s' % sess.run(b1))
print('w2=%s' % sess.run(w2))
print('b2=%s' % sess.run(b2))
print('cost (ce)=%s' % sess.run(cross_entropy,
feed_dict={input_: XOR_X,
target: XOR_T}))
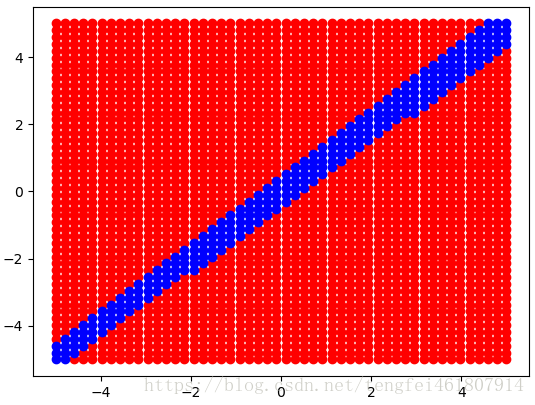
# 可视化分类边界
xs = np.linspace(-5, 5)
ys = np.linspace(-5, 5)
pred_classes = []
for x in xs:
for y in ys:
pred_class = sess.run(hypothesis,
feed_dict={input_: [[x, y]]})
pred_classes.append((x, y, pred_class.argmax()))
xs_p, ys_p = [], []
xs_n, ys_n = [], []
for x, y, c in pred_classes:
if c == 0:
xs_n.append(x)
ys_n.append(y)
else:
xs_p.append(x)
ys_p.append(y)
plt.plot(xs_p, ys_p, 'ro', xs_n, ys_n, 'bo')
plt.show()
# 训练数据
XOR_X = [[0, 0], [0, 1], [1, 0], [1, 1]]
XOR_Y = [0, 1, 1, 0] # 每个数据对应的结果
assert len(XOR_X) == len(XOR_Y) # 检查数据和标签是否一致
enc = OneHotEncoder()
enc.fit(list_to_flat_array(XOR_Y))
XOR_T = enc.transform(list_to_flat_array(XOR_Y)).toarray()
'''
XOR_T结果为
[[ 1. 0.]
[ 0. 1.]
[ 0. 1.]
[ 1. 0.]]
表示
[0,1,1,0]对应的onehotencoding值
'''
# 分成几类
nb_classes = 2
'''
placeholder参数:
数据类型
数据形状(如果不填写,自动变形)
常量名
'''
input_ = tf.placeholder(tf.float32,
shape=[None, len(XOR_X[0])],
name="input")
target = tf.placeholder(tf.float32,
shape=[None, nb_classes],
name="output")
nb_hidden_nodes = 2
# enc = tf.one_hot([0, 1], 2)
# 第一层,输入数据获取参数
w1 = tf.Variable(tf.random_uniform([2, nb_hidden_nodes], -1, 1, seed=0),
name="Weights1")
w2 = tf.Variable(tf.random_uniform([nb_hidden_nodes, nb_classes], -1, 1,
seed=0),
name="Weights2")
b1 = tf.Variable(tf.zeros([nb_hidden_nodes]), name="Biases1")
b2 = tf.Variable(tf.zeros([nb_classes]), name="Biases2")
'''
matmul做矩阵乘法
input为?行2列的矩阵,w1为2行2列的矩阵
'''
activation2 = tf.sigmoid(tf.matmul(input_, w1) + b1)
#返回一个?行2列的矩阵表示每个结果对应的概率
hypothesis = tf.nn.softmax(tf.matmul(activation2, w2) + b2)
#计算交叉熵
cross_entropy = -tf.reduce_sum(target * tf.log(hypothesis))
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(cross_entropy)
# Start training
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(20001):
#输入值input_是 [[0, 0], [0, 1], [1, 0], [1, 1]]
#标签target是 [[ 1. 0.][ 0. 1.][ 0. 1.][ 1. 0.]]
sess.run(train_step, feed_dict={input_: XOR_X, target: XOR_T})
if i % 10000 == 0:
analyze_classifier(sess, i, w1, b1, w2, b2, XOR_X, XOR_T)
结果:
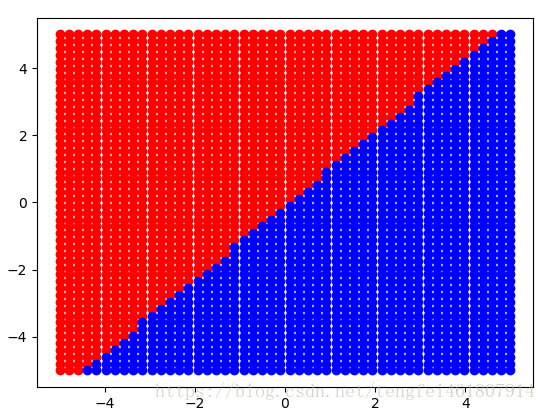
Epoch 0
Hypothesis [[ 0.48712057 0.51287943]
[ 0.3380821 0.66191792]
[ 0.65063184 0.34936813]
[ 0.5031724 0.49682763]]
w1=[[-0.79593647 0.93947881]
[ 0.68854761 -0.89423609]]
b1=[-0.00733338 0.00893857]
w2=[[-0.79084051 0.93289936]
[ 0.69278169 -0.8986907 ]]
b2=[ 0.00394399 -0.00394398]
cost (ce)=2.87031
Epoch 10000
Hypothesis [[ 0.99773693 0.00226305]
[ 0.00290443 0.99709558]
[ 0.00295531 0.99704474]
[ 0.99804318 0.00195681]]
w1=[[-6.62694883 7.52302551]
[ 6.91208267 -7.39292049]]
b1=[ 3.32245088 3.76204109]
w2=[[ 6.63464451 -6.49259472]
[ 6.40471601 -6.61061907]]
b2=[-9.65064335 9.65065002]
cost (ce)=0.0100926
Epoch 20000
Hypothesis [[ 9.98954773e-01 1.04520307e-03]
[ 1.35455513e-03 9.98645484e-01]
[ 1.37042650e-03 9.98629570e-01]
[ 9.99092221e-01 9.07784502e-04]]
w1=[[-7.04857349 7.84673071]
[ 7.33061361 -7.6883769 ]]
b1=[ 3.53246331 3.89587522]
w2=[[ 7.35947943 -7.21742964]
[ 7.14059544 -7.34649324]]
b2=[-10.74944305 10.7494421 ]
cost (ce)=0.00468077理论参考:深度学习,人民邮电出版社