一、HashMap底层实现
在JDK1.6,JDK1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。
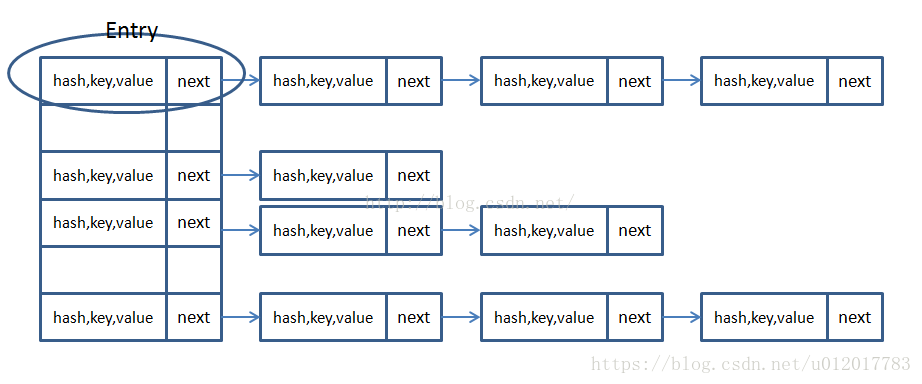
而JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。在java jdk8中对HashMap的源码进行了优化,在jdk7中,HashMap处理“碰撞”的时候,都是采用链表来存储,当碰撞的结点很多时,查询时间是O(n)。在jdk8中,HashMap处理“碰撞”增加了红黑树这种数据结构,当碰撞结点较少时,采用链表存储,当较大时(>8个),采用红黑树(特点是查询时间是O(logn))存储(有一个阀值控制,大于阀值(8个),将链表存储转换成红黑树存储)
简单说下HashMap的实现原理:
首先有一个每个元素都是链表(可能表述不准确)的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值的元素的后面,他们在数组的同一位置,但是形成了链表,同一各链表上的Hash值是相同的,所以说数组存放的是链表。而当链表长度太长时,链表就转换为红黑树,这样大大提高了查找的效率。
二、HashTable底层实现
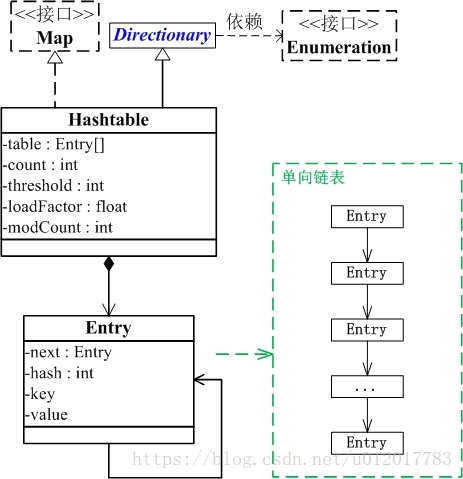
(01) Hashtable继承于Dictionary类,实现了Map接口。Map是”key-value键值对”接口,Dictionary是声明了操作”键值对”函数接口的抽象类。 依靠synchronized实现同步
(02) Hashtable是通过”拉链法”实现的哈希表。它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的”key-value键值对”都是存储在Entry数组中的。
count是Hashtable的大小,它是Hashtable保存的键值对的数量。
threshold是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值=”容量*加载因子”。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的
Hashtable 的实例有两个参数影响其性能:初始容量 和 加载因子。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)。
三、ConcurrentHashMap底层实现
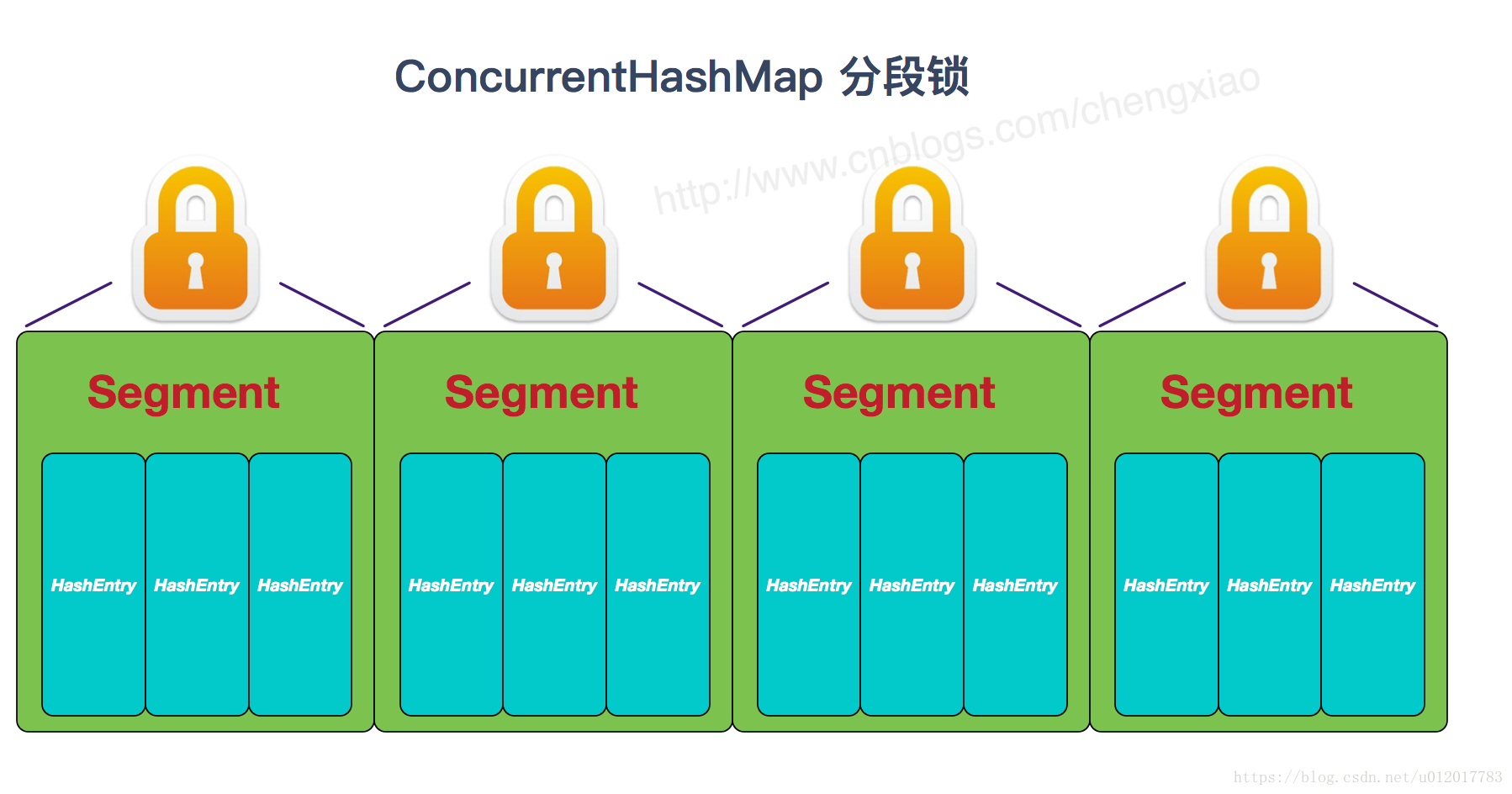
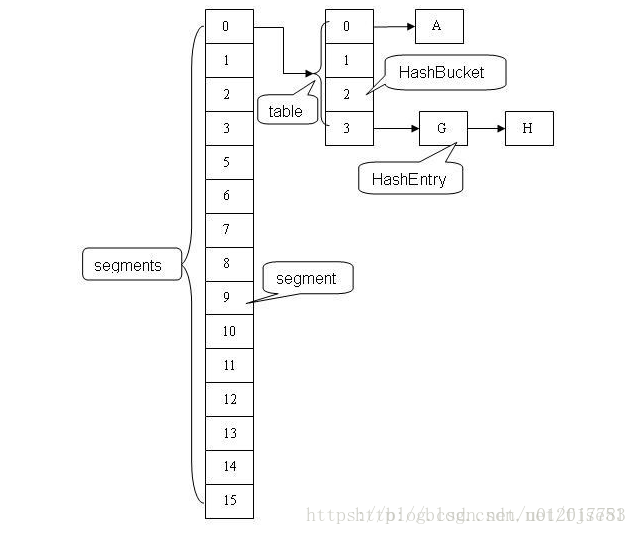
ConcurrentHashMap采用分段锁的机制,实现并发的更新操作,底层由Segment数组和HashEntry数组组成。Segment继承ReentrantLock用来充当锁的角色,所以它就是一种可重入锁(ReentrantLock),其中每个Segment 对象守护每个散列映射表的若干个桶。HashEntry 用来封装映射表的键 / 值对;每个桶是由若干个 HashEntry 对象链接起来的链表,一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组(就按默认的ConcurrentLeve为16来讲,理论上就允许16个线程并发执行)