版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qy20115549/article/details/82154887
本文作者:合肥工业大学 管理学院 钱洋 email:[email protected] 内容可能有不到之处,欢迎交流。
未经本人允许禁止转载。
训练文档向量
在上一小节中,本人介绍了使用DeepLearning4J训练得到词向量(https://blog.csdn.net/qy20115549/article/details/82152462)。本篇主要介绍给定任意文本数据(分词后的数据),如何使用DeepLearning4J训练得到文档的向量。
在平时的使用中,我们可以将文档转化成向量形式,进而进行聚类分类等其他操作。常用的将文档转化成向量形式的方法有one-hot编码、TF-IDF编码、主题模型(LDA)以及本篇要介绍的Doc2Vec操作。如下为笔者使用的文本数据:
对应的操作程序如下:
package org.deeplearning4j.examples.nlp.paragraphvectors;
import java.io.File;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.List;
import org.deeplearning4j.models.embeddings.loader.WordVectorSerializer;
import org.deeplearning4j.models.paragraphvectors.ParagraphVectors;
import org.deeplearning4j.models.word2vec.VocabWord;
import org.deeplearning4j.models.word2vec.wordstore.inmemory.AbstractCache;
import org.deeplearning4j.text.documentiterator.LabelsSource;
import org.deeplearning4j.text.sentenceiterator.LineSentenceIterator;
import org.deeplearning4j.text.sentenceiterator.SentenceIterator;
import org.deeplearning4j.text.tokenization.tokenizer.preprocessor.CommonPreprocessor;
import org.deeplearning4j.text.tokenization.tokenizerfactory.DefaultTokenizerFactory;
import org.deeplearning4j.text.tokenization.tokenizerfactory.TokenizerFactory;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Doc2VecTest {
private static Logger log = LoggerFactory.getLogger(Doc2VecTest.class);
//文档向量输出路径
private static String outputPath = "E:/doc2vec.txt";
public static void main(String[] args) throws Exception {
//输入文本文件的目录
File inputTxt = new File("E:/raw_sentences.txt");
log.info("开始加载数据...."+inputTxt.getName());
//加载数据
SentenceIterator iter = new LineSentenceIterator(inputTxt);
//切词操作
TokenizerFactory token = new DefaultTokenizerFactory();
//去除特殊符号及大小写转换操作
token.setTokenPreProcessor(new CommonPreprocessor());
AbstractCache<VocabWord> cache=new AbstractCache<>();
//添加文档标签,这个一般从文件读取,为了方面我这里使用了数字
List<String> labelList = new ArrayList<String>();
for (int i = 0; i < 97162; i++) {
labelList.add("doc"+i);
}
//设置文档标签
LabelsSource source = new LabelsSource(labelList);
log.info("训练模型....");
ParagraphVectors vec = new ParagraphVectors.Builder()
.minWordFrequency(1)
.iterations(5)
.epochs(1)
.layerSize(100)
.learningRate(0.025)
.labelsSource(source)
.windowSize(5)
.iterate(iter)
.trainWordVectors(false)
.vocabCache(cache)
.tokenizerFactory(token)
.sampling(0)
.build();
vec.fit();
log.info("相似的句子:");
Collection<String> lst = vec.wordsNearest("doc0", 10);
System.out.println(lst);
log.info("输出文档向量....");
WordVectorSerializer.writeWordVectors(vec, outputPath);
//获取某词对应的向量
log.info("向量获取:");
double[] docVector = vec.getWordVector("doc0");
System.out.println(Arrays.toString(docVector));
}
}
程序在控制台输出的结果为:
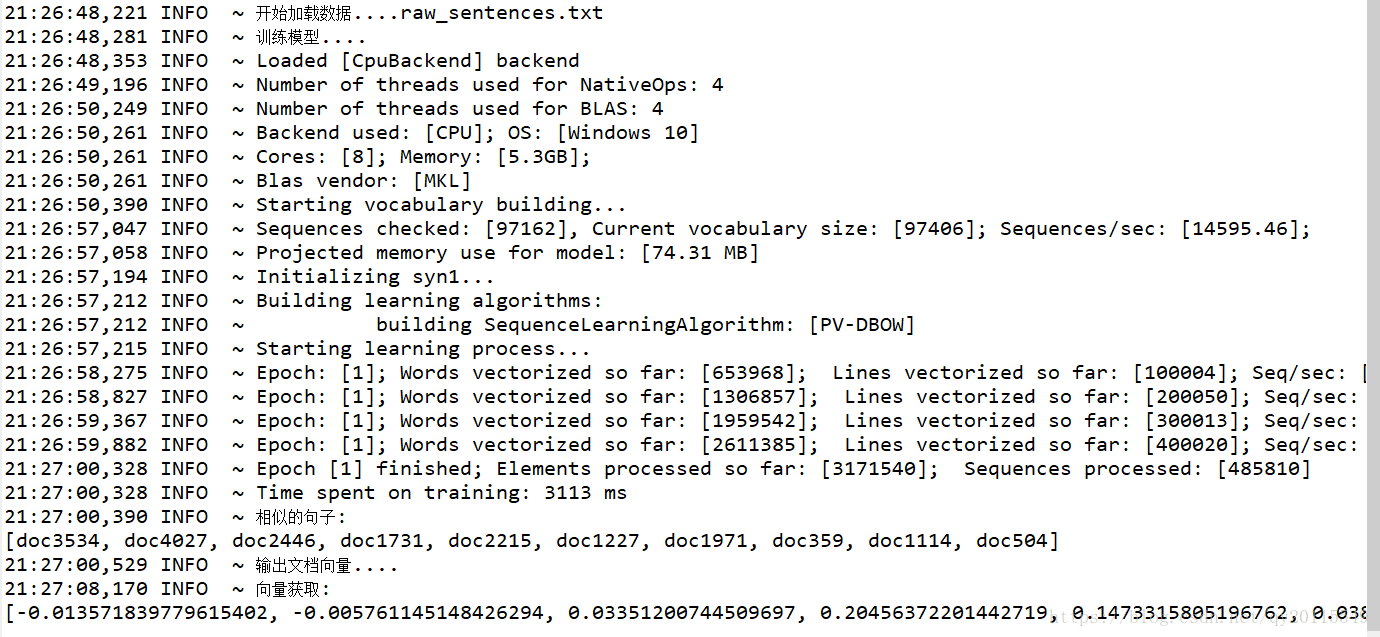
另外,我们也成功的将每篇文档对应的向量输出到本地文件中,如下图所示为每篇文档对应的向量结果:

改写输出方式
另外,我们也可以写一个操作方法,是的输出结果按照每个人的需求来,比如我个人的需求是:
文档内容 Tab键分割 向量内容
那么,上述的程序可以重写为:
package com.qian;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.deeplearning4j.models.paragraphvectors.ParagraphVectors;
import org.deeplearning4j.models.word2vec.VocabWord;
import org.deeplearning4j.models.word2vec.wordstore.VocabCache;
import org.deeplearning4j.models.word2vec.wordstore.inmemory.AbstractCache;
import org.deeplearning4j.text.documentiterator.LabelsSource;
import org.deeplearning4j.text.sentenceiterator.LineSentenceIterator;
import org.deeplearning4j.text.sentenceiterator.SentenceIterator;
import org.deeplearning4j.text.tokenization.tokenizer.preprocessor.CommonPreprocessor;
import org.deeplearning4j.text.tokenization.tokenizerfactory.DefaultTokenizerFactory;
import org.deeplearning4j.text.tokenization.tokenizerfactory.TokenizerFactory;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Doc2VecTest {
private static Logger log = LoggerFactory.getLogger(Doc2VecTest.class);
//文档向量输出路径
private static String outputPath = "data/doc2vec.txt";
private static String inputPath = "data/raw_sentences.txt";
public static void main(String[] args) throws Exception {
//输入文本文件的目录
File inputTxt = new File(inputPath);
log.info("开始加载数据...." + inputTxt.getName());
//加载数据
SentenceIterator iter = new LineSentenceIterator(inputTxt);
//切词操作
TokenizerFactory token = new DefaultTokenizerFactory();
//去除特殊符号及大小写转换操作
token.setTokenPreProcessor(new CommonPreprocessor());
AbstractCache<VocabWord> cache=new AbstractCache<>();
//添加文档标签,这个一般从文件读取,为了方面我这里使用了数字
List<String> labelList = new ArrayList<String>();
for (int i = 1; i < 97163; i++) {
labelList.add("doc"+i);
}
//设置文档标签
LabelsSource source = new LabelsSource(labelList);
log.info("训练模型....");
ParagraphVectors vec = new ParagraphVectors.Builder()
.minWordFrequency(1)
.iterations(5)
.epochs(1)
.layerSize(50)
.learningRate(0.025)
.labelsSource(source)
.windowSize(5)
.iterate(iter)
.trainWordVectors(false)
.vocabCache(cache)
.tokenizerFactory(token)
.sampling(0)
.build();
vec.fit();
log.info("相似的句子:");
Collection<String> lst = vec.wordsNearest("doc1", 10);
System.out.println(lst);
log.info("输出文档向量....");
writeDocVectors(vec,outputPath);
//获取某词对应的向量
log.info("向量获取:");
double[] docVector = vec.getWordVector("doc1");
System.out.println(Arrays.toString(docVector));
}
public static void writeDocVectors(ParagraphVectors vectors, String outpath) throws IOException {
//写操作
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File(outpath)),"gbk"));
//读操作
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(new FileInputStream(new File(inputPath)), "gbk"));
String line = null;
int i = 1;
Map<String, String> keyToDoc = new HashMap<>();
while ((line = bufferedReader.readLine())!=null) {
keyToDoc.put("doc" + i, line);
i++;
}
VocabCache<VocabWord> vocabCache = vectors.getVocab();
for (VocabWord word : vocabCache.vocabWords()) {
StringBuilder builder = new StringBuilder();
//获取每个文档对应的标签
INDArray vector = vectors.getWordVectorMatrix(word.getLabel());
//向量添加
for (int j = 0; j < vector.length(); j++) {
builder.append(vector.getDouble(j));
if (j < vector.length() - 1) {
builder.append(" ");
}
}
//写入指定文件
bufferedWriter.write(keyToDoc.get(word.getLabel()) + "\t" + builder.append("\n").toString());
}
bufferedWriter.close();
bufferedReader.close();
}
}
程序的输出结果如下图所示,前面是文档后面是文档对应的向量:
