1、Doc2vec概述
Doc2vec 和熟知的 Word2vec 类似,只不过 Word2vec 是训练词向量,而 Doc2vec 可以训练句子,段落,文档的向量表示。
Doc2vec 将文本向量化的应用解决了几个问题:
1)解决了文本中词之间的顺序问题
2)解决了文本中词的语义问题
3)解决了文本向量化后的高稀疏高维度的问题
4)解决了文本长度不均的问题,可以转变成等长的向量,适用于句子,段落和文本。
利用 Doc2vec 可以极大地提高在文本分类,情感分析等问题上的准确率
2、Doc2vec模型
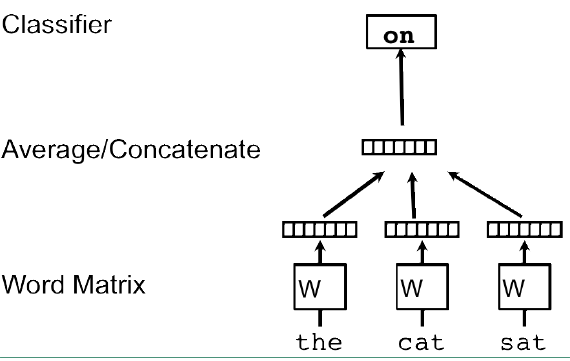
Doc2vec 中的两个模型都是受到 word2vec 激发的。在 word2vec 中的CBOW模型是利用上下文的词预测中心词。其具体模型图如下:
而在 Doc2vec 有个类似的模型,称为 Distributed Memory Model of Paragraph Vectors (PV-DM)。其具体模型结构如下图:
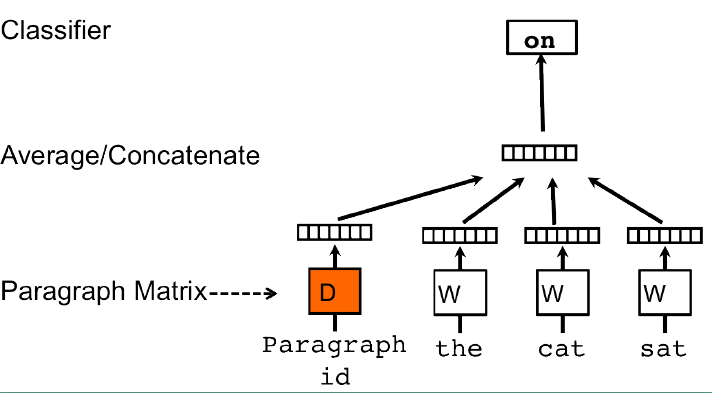
PV-DM 模型较 CBOW 的不同点就是引入了段落作为输入值。假设在我们的语料库中有 N 个段落、M 个词,段落映射后的向量长度为p,词映射后的向量长度为q。则整个模型的参数就是 N × p + M × q 。
而在输入值也是采用固定的滑动窗口来输入的。但是在这里段落该怎么处理呢?原文中是这么说的(不是很明确意思,各位自己理解):
The contexts are fixed-length and sampled from a sliding window over the paragraph. The paragraph vector is shared across all contexts generated from the same paragraph but not across paragraphs. The word vector matrix W, however, is shared across paragraphs. I.e., the vector for “powerful” is the same for all paragraphs。
对于这段话我的理解是,段落与段落之间是相互独立的,而词在所有段落之间是共享的。
在预测新的段落(不在语料库中)的向量时,固定词向量W 和 softmax时的权重 U 和偏置 b。将新的段落加入到矩阵D中,然后梯度下降求新段落的向量。
除了PV-DM 模型之外,还有一个 PV-DBOW (Distributed Bag ofWords version of Paragraph Vector)模型(该模型有点类似于skip-gram 模型)。具体的模型结构如下:
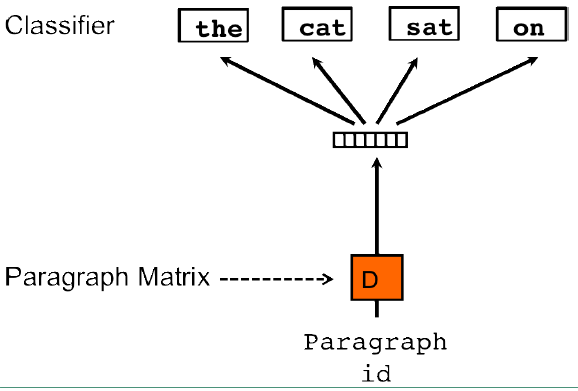
PV-DBOW 模型是一种忽略了上下文的方法。这个模型输入时段落矩阵,输出是从段落中随机采样的词,而且在每次梯度下降迭代时都会重新采样,以此来训练段落向量。
一般来说 PV-DM 模型就可以获得很好的结果,但是将 PV-DM 和 PV-DBOW 两个模型生成的向量结合起来的效果会更好。所以更推荐后者。