- 网络监控
第一步:通过ifconfig 查看网卡
ifconfig[[email protected] mycat]# ifconfig
bond0 Link encap:Ethernet HWaddr F4:E9:D4:CB:EA:30
inet addr:10.205.64.60 Bcast:10.205.64.255 Mask:255.255.255.0
inet6 addr: fe80::f6e9:d4ff:fecb:ea30/64 Scope:Link
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:17589180689 errors:6246 dropped:0 overruns:6246 frame:0
TX packets:15416676087 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:17974947213419 (16.3 TiB) TX bytes:10243802504043 (9.3 TiB)
bond1 Link encap:Ethernet HWaddr F4:E9:D4:CB:EA:32
inet6 addr: fe80::f6e9:d4ff:fecb:ea32/64 Scope:Link
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:1855299 errors:0 dropped:0 overruns:0 frame:0
TX packets:6 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:540174664 (515.1 MiB) TX bytes:492 (492.0 b)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:17510695 errors:0 dropped:0 overruns:0 frame:0
TX packets:17510695 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:27644635246 (25.7 GiB) TX bytes:27644635246 (25.7 GiB)
p3p1 Link encap:Ethernet HWaddr F4:E9:D4:CB:EA:30
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:17588175295 errors:6246 dropped:0 overruns:6246 frame:0
TX packets:15416676087 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:17974598297453 (16.3 TiB) TX bytes:10243802504043 (9.3 TiB)
Interrupt:34 Memory:97800000-97ffffff
p3p2 Link encap:Ethernet HWaddr F4:E9:D4:CB:EA:32
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:927650 errors:0 dropped:0 overruns:0 frame:0
TX packets:6 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:270087364 (257.5 MiB) TX bytes:492 (492.0 b)
Interrupt:37 Memory:96800000-96ffffff
p4p1 Link encap:Ethernet HWaddr F4:E9:D4:CB:EA:30
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:1005394 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:348915966 (332.7 MiB) TX bytes:0 (0.0 b)
Interrupt:64 Memory:ad000000-ad7fffff
p4p2 Link encap:Ethernet HWaddr F4:E9:D4:CB:EA:32
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:927649 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:270087300 (257.5 MiB) TX bytes:0 (0.0 b)
Interrupt:68 Memory:ac000000-ac7fffff
第二步:watch -n 1 "watch -n 1 "ifconfig p3p1"
watch -n 1 "watch -n 1 "ifconfig p3p1"一秒钟 监控一次 如下图:
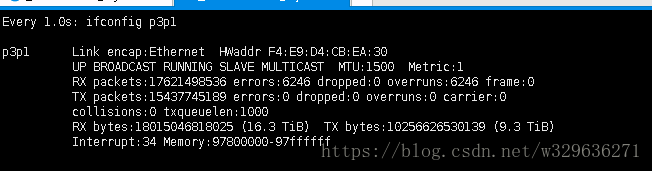
- io与cpu的监控
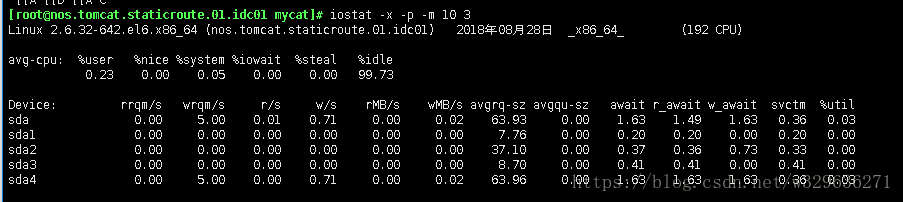
命令iostat -x 10
iostat -x 10显示详细信息,10秒钟显示一次

await: 平均每次设备 I/O 操作的等待时间(毫秒)
svctm: 平均每次设备 I/O 操作的服务时间(毫秒)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。
avgqu-sz: 平均 I/O 队列长度。
主要看如下几个指标:
- 如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
- 如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;
- 如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。
- 如果avgqu-sz比较大,也表示有当量io在等待。
显示每个盘的io详情
其他说明:
命令格式:
iostat[参数][时间][次数]
命令参数:
-C 显示CPU使用情况
-d 显示磁盘使用情况
-k 以 KB 为单位显示
-m 以 M 为单位显示
-N 显示磁盘阵列(LVM) 信息
-n 显示NFS 使用情况
-p[磁盘] 显示磁盘和分区的情况
-t 显示终端和CPU的信息
-x 显示详细信息
-V 显示版本信息
CPU 属性值
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。
备注:
如果%iowait的值过高,表示硬盘存在I/O瓶颈,
%idle值高,表示CPU较空闲,
如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。
%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
磁盘每一列的含义如下:
rrqm/s: 每秒进行 merge 的读操作数目。 即 rmerge/s
wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
r/s: 每秒完成的读 I/O 设备次数。 即 rio/s
w/s: 每秒完成的写 I/O 设备次数。即 wio/s
rsec/s: 每秒读扇区数。即 rsect/s
wsec/s: 每秒写扇区数。即 wsect/s
rkB/s: 每秒读 K 字节数。是 rsect/s 的一半,因为扇区大小为 512 字节
wkB/s: 每秒写 K 字节数。是 wsect/s 的一半
avgrq-sz: 平均每次设备 I/O 操作的数据大小(扇区)
avgqu-sz: 平均 I/O 队列长度。
await: 平均每次设备 I/O 操作的等待时间(毫秒)
svctm: 平均每次设备 I/O 操作的服务时间(毫秒)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。
备注:
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;
如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。
如果avgqu-sz比较大,也表示有当量io在等待。
怎么理解这里的字段呢?
以超市结账的例子来说明。 我们在超市排队结账时,怎么决定该去哪个收银台呢? 首先是看每个收银台的排队人数,5 个人总比 20 人要快吧?
除了数人头,我们也常常看看前面人购买的东西多少,如果前面有个采购了一星期食品的大妈, 那么可以考虑换个队排了。
还有就是收银员的速度了,如果碰上了连钱都点不清楚的新手,那就有的等了。
另外,时机也很重要,可能 5 分钟前还人满为患的收款台,现在已是人去楼空,这时候交款就很爽啊,当然,前提是那过去的 5 分钟里所做的事情比排队要有意义(不过我还没发现什么事情比排队还无聊的)。
I/O 系统也和超市排队有很多类似之处:
r/s+w/s 类似于交款人的总数
avgqu-sz(平均队列长度): 类似于单位时间里平均排队的人数
svctm(平均服务时间) 类似于收银员的收款速度
await(平均等待时间) 类似于平均每人的等待时间
avgrq-sz(平均 IO 数据) 类似于平均每人所买的东西多少
%util(磁盘 IO 使用率) 类似于收款台前有人排队的时间比例。
我们可以根据这些数据分析出 I/O 请求的模式,以及 I/O 的速度和响应时间:
如果%util 接近 100%,说明产生的 I/O 请求太多,I/O 系统已经满负荷,该磁盘可能存在瓶颈。
svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm的增加。
await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。一般来说 svctm < await,因为同时等待的请求的等待时间被重复计算了。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间
如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。
如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU。
如果%util 很大,而 rkB/s 和 wkB/s 很小,一般是因为磁盘存在较多的磁盘随机读写,最好把磁盘随机读写优化成顺序读写。
- jstat 查看jvm的各种gc状态
jstat.exe -gcutil 3804

jstat.exe -gc 3804 15000
S0C:第一个幸存区的大小
S1C:第二个幸存区的大小
S0U:第一个幸存区的使用大小
S1U:第二个幸存区的使用大小
EC:伊甸园区的大小
EU:伊甸园区的使用大小
OC:老年代大小
OU:老年代使用大小
MC:方法区大小
MU:方法区使用大小
CCSC:压缩类空间大小
CCSU:压缩类空间使用大小
YGC:年轻代垃圾回收次数
YGCT:年轻代垃圾回收消耗时间
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
4.jconsle