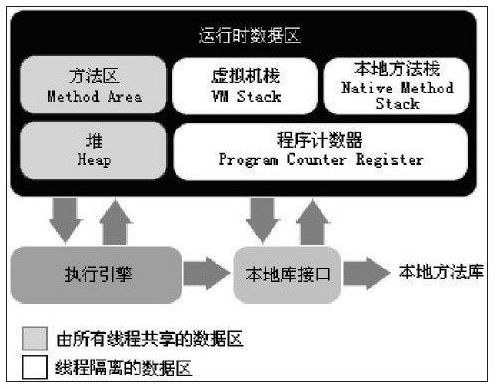
内存区域划分
线程隔离区
- 程序计数器(Program Counter Register):当前线程所执行的字节码的行号指示器
- 虚拟机栈(VM Stack):描述的是Java方法执行的内存模型,每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息;每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程;局部变量表所需的内存空间在编译期间已经确定,在方法运行期间不会改变局部变量表的大小;栈可能抛出StackOverflowError、OutOfMemoryError异常
- 本地方法栈(Native Method Stack):与虚拟机栈类似,只不过执行的方法是Native方法
线程共享区
- 堆(Heap):存放所有对象实例和数组,堆是垃圾收集器管理的主要区域,可能抛出OutOfMemoryError异常
- 方法区(Method Area):别名Non-Heap(非堆),还被称为“永生代”(Permanent Generation),用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据,可能抛出OutOfMemoryError异常
- 运行时常量池(Runtime Constant Pool):是方法区的一部分,可能抛出OutOfMemoryError异常
注意!在JDK1.7的HotSpot中,已经把原本放在方法区(永久代)的字符串常量池移出。
垃圾收集算法
如何判断对象已死?
- 引用计数法
- 可达性分析
HotSpot的垃圾收集采用分代收集算法,根据对象存活周期的不同将内存划分为几块,堆被分为新生代与老年代,根据各个年代的特点采用不同的垃圾收集算法。
- 标记-清除算法(Mark-Sweep)
- 复制算法(Copying)
- 标记-整理算法(Mark-Compact)
问:年轻代为什么采用的是复制算法?
答:在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,所以选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。
问:年轻代为什么被划分成Eden空间、From Survivor空间、To Survivor空间?
答:HotSpot将新生代分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性地复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,也就是每次新生代中可用内存空间为整个新生代容量的90%(80%+10%),只有10%的内存会被“浪费”。
另外,如果另外一块Survivor空间没有足够空间存放上一次新生代收集下来的存活对象时,这些对象将直接通过分配担保(Handle Promotion)机制进入老年代。
问:老年代为什么采用的是标记清除、标记整理算法?
答:因为老年代中对象存活率高,且没有额外空间对它进行分配担保。
垃圾收集器
jdk8的HotSpot虚拟机运行在Server模式下,默认使用Parallel Scavenge+Serial Old(PS MarkSweep)的收集器组合进行内存回收,jdk9默认使用G1收集器
新生代(Young generation)收集器
- Serial收集器:单线程,client模式下的默认新生代收集器
- ParNew收集器:Serial收集器的多线程版本
- Parallel Scavenge收集器
- G1收集器
老年代(Tenured generation)收集器
- CMS(Concurrent Mark Sweep)收集器
- Serial Old收集器:单线程,Serial收集器的老年代版本
- Parallel Old收集器:Parallel Scavenge收集器的老年代版本
- G1收集器
内存分配策略
- 对象优先在Eden分配
- 大对象直接进入老年代
- 长期存活的对象将进入老年代