前言
上一次我们学习了如何简单的制作一个可以显示消息的网页,这一次我们做一个复杂一点的,可以通过爬虫获取某视频网站视频名字及播放地址,再将获取的信息在网页上展现出来。
工具
- requests库
- django框架
- 多线程库 threading
代码时间
首先,我们新建一个项目名为my91(老司机们懂得),之后开始写我们的爬虫代码。这里由于篇幅,暂时不放出爬虫代码,直接利用返回值开始工作。
第一步,先写一个初始化页面用来做首页,名字叫做 index.html ,还有一个视频页 video.html。
目录结构在这里
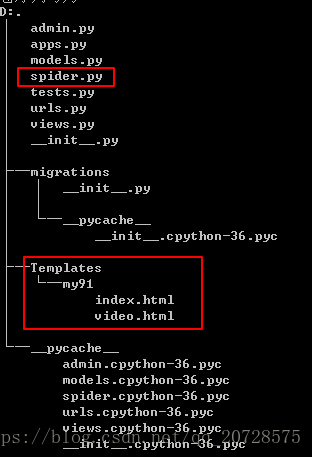
这里解释一下, 两个红框是这次操作的主要文件,之前提到过由于Django会在所有 app 中寻找模版文件,为了防止出现检索错误,所以我们添加一个 app 名字的子文件夹叫做 my91 ,在里面新建这两个网页文件,代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>我的91小站</title>
</head>
<body>
<h1>hello gay</h1>
</body>
</html>接下来是视频页的代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>视频页-详情</title>
</head>
<body>
<h1>详情列表</h1>
视频列表:
{% for url in urls%}
{% for key, value in url.items%}
<p>
<a href="{{value}}">影片名字:{{key}}</a>
</p>
{%endfor%}
{%endfor%}
<p>
<a href = "{% url 'video' %}?url_1={{next_page}}">下一页</a>
</p>
</body>
</html>这里先不着急代码是什么意思,我们进入 django 最重要的视图文件 view.py 看看就知道了。
from django.shortcuts import render #引入 Django 自带的渲染函数
from spider import * #导入爬虫类
from django.http import HttpResponse #导入简单响应
# Create your views here.
def index(request):
return render(request,'my91/index.html')
def video(request):
url_1 = request.GET['url_1'] #获得网址中 url_1 的值
temp = Spider_91() #继承爬虫类
temp.set_url('免翻地址') #设置爬虫类的起始网页
next_page = int(url_1) + 1 #将采集到的页码加一用于翻页
result = temp.run(url_1) #得到爬虫类的返回值
return render(request, 'my91/video.html', {'urls':result, 'next_page':next_page}) #返回 video 网页,并将返回值与页码传入代码具体意思里面都有解析,现在来讲一讲 request,GET[参数] 这个用法,我们平时浏览网页经常可以看到在主域名后面有时候会出现 ?value=1234 这样的字符串,这里其实就是向网页传递了一个名为 value 的参数, 1234 是它的值。所以我们这里的 request,GET[参数] 其实就是采集网址中指定参数的值。
接下来我们看看网址配置怎么写,详情见 url.py 文件
#!/usr/bin/env python
# _*_coding:utf-8 _*_
from django.urls import path #Django2.0 以上开始使用 path 进行路径设置
from django.contrib import admin
from . import views #导入视图文件
urlpatterns = [
path('', views.index, name = 'home'), #当路径为主域名时,返回 views.index 方法的值,也就是 index.html 网页
path('video/', views.video, name = 'video') #同理,路径为 主域名/video 时,返回 views.video 的值,也就是 video.html 网页。
]
这里要解释一下,爬虫的返回值是一个列表,列表中是一个字典,形式如下:
[{视频名称1:视频地址1},{视频名称2:视频地址2}] ,通过 render() 函数,可以将这个值传入网页中
return render(request, 'my91/video.html', {'urls':result, 'next_page':next_page})第一个是请求 request, 第二个是返回的网页 video.html ,第三个是一个字典文件,首先是之前提到的爬虫返回值,我们将他赋予变量 result ,并把它添加进字典中,这样在网页中可以调用这个返回值。
{% for url in urls%}
{% for key, value in url.items%}
<p>
<a href="{{value}}">影片名字:{{key}}</a>
</p>
{%endfor%}
{%endfor%}这里就是将 url 变量 放入传入的 urls 中遍历,之后将其中的字典文件的 key 和 value 值在网页中显示出来。
接下来直接访问 127.0.0.0:8000/my91/video/?url_1=2 来测试一下
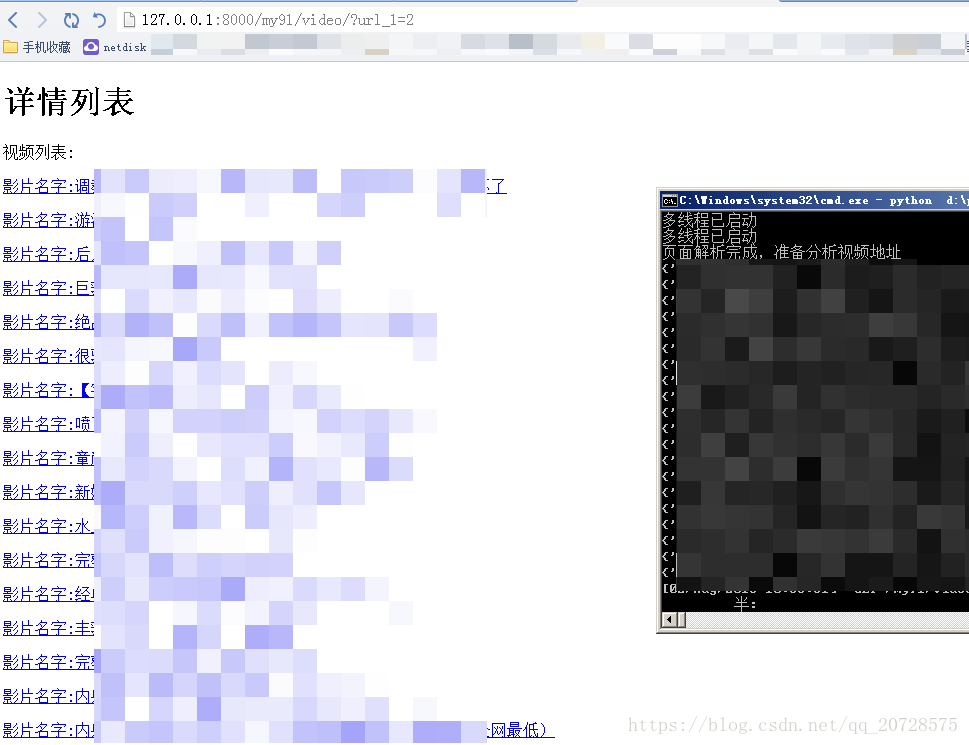
可以看到已经成功利用爬虫采集将页面展示出来了,接下来我们来实现翻页功能。
video.html
<a href = "{% url 'video' %}?url_1={{next_page}}">下一页</a>
views.py
return render(request, 'my91/video.html', {'urls':result, 'next_page':next_page})利用在 url.py 中定义好的类名,直接在 HTML 中将网址写入,再加上 render 函数中传递的页码值,可以实现自动翻页。

可以看到网页已经自动翻页,内容也发生改变,爬虫源码将会放在 github 上,欢迎围观