自动识别验证码与初识Scrapy框架
1、多线程优化
2、登录古诗文
登录:直接发送post,然后发送get
登录:先发送get,获取一下信息,然后再发送post,然后发送get
登录:get、post、get、get。 访问登录后的页面
验证码,下载到本地,手动输入
3、自动识别验证码
(1)光学识别 tesseract
指令识别
识别率不行,但是可以训练它 代码识别
pip install pytesseract
pip install pillow
通过图像处理处理一下图片,然后再去识别,提高识别率(2)打码平台
(2)打码平台
云打码4、scrapy
Scrapy是一个非常强大、精悍的Python网络爬虫框架,它的底层使用Python语言实现的, 为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据或者通用的网络爬虫。
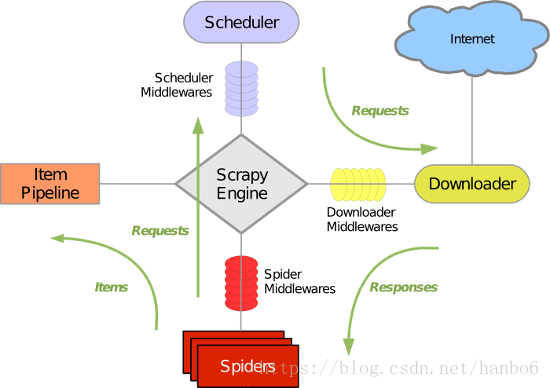
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下:
(1)安装Scrapy
pip install scrapy(2)Acrapy组件
1). 引擎(Scrapy engine)
用来处理整个系统的数据流处理, 触发事务(框架核心)
2). 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
3). 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
4). 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
5). 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后, 将被发送到项目管道,并经过几个特定的次序处理数据。
6). 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7). 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
8). 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
(3)处理流程
Scrapy的整个数据处理流程由Scrapy引擎进行控制,通常的运转流程包括以下的步骤:
- 引擎询问蜘蛛需要处理哪个网站,并让蜘蛛将第一个需要处理的URL交给它。
- 引擎让调度器将需要处理的URL放在队列中。
- 引擎从调度那获取接下来进行爬取的页面。
- 调度将下一个爬取的URL返回给引擎,引擎将它通过下载中间件发送到下载器。
- 当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎;如果下载失败了,引擎会通知调度器记录这个URL,待会再重新下载。
- 引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
- 蜘蛛处理响应并返回爬取到的数据条目,此外还要将需要跟进的新的URL发送给引擎。
- 引擎将抓取到的数据条目送入条目管道,把新的URL发送给调度器放入队列中。
上述操作中的2-8步会一直重复直到调度器中没有需要请求的URL,爬虫停止工作。
(4)创建项目
scrapy startproject xxx(5) 目录结构解释
firstbloodpro 工程总目录
firstbloodpro 工程目录
__pycache__ 缓存目录
spiders 爬虫目录 如:创建文件,编写爬虫规则。
__pycache__ 缓存目录
__init__.py 包的标记
lala.py 爬虫文件(*)
__init__.py 包的标记
items.py 定义数据结构的地方(*)设置数据存储模板,如:Django的Model
middlewares.py 中间件
pipelines.py 管道文件(*)数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件(*)如:递归的层数、并发数,延迟下载等
scrapy.cfg 工程配置信息(一般不用)主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)(6)生成爬虫文件
cd firstbloodpro
scrapy genspider xxx www.xxx.com(7)运行命令
cd firstbloodpro/firstbloodpro/spiders
scrapy crawl qiubai
修改settings.py,将遵从robots协议去掉,将UA定制一下
启动命令中 'qidian'参数为我们定义爬虫中的name属性的值
执行流程:
name: spider对应不同的name
start_urls:是spider抓取网页的起始点,可以包括多个url。
parse():spider抓到一个网页以后默认调用的callback,避免使用这个名字来定义自己的方法。当spider拿到url的内容以后,会调用parse方法,并且传递一个response参数给它,response包含了抓到的网页的内容,在parse方法里,你可以从抓到的网页里面解析数据。(8)认识response对象
response.text : 字符串格式的内容
response.body : 字节格式的内容
response.url : 请求的url
response.headers : 响应的头部
response.status_code : 得到状态码
在scrapy里面,已经为你集成了xpath,直接使用即可
response.xpath('')(9)一键指定输出
scrapy crawl qiubai -o qiubai.json
scrapy crawl qiubai -o qiubai.xml
scrapy crawl qiubai -o qiubai.csv
解决输出csv有空行问题见博客
https://blog.csdn.net/qq_38282706/article/details/80279912