【作者主页】:吴秋霖
【作者介绍】:Python领域优质创作者、阿里云博客专家、华为云享专家。长期致力于Python与爬虫领域研究与开发工作!
【作者推荐】:对JS逆向感兴趣的朋友可以关注《爬虫JS逆向实战》,对分布式爬虫平台感兴趣的朋友可以关注《分布式爬虫平台搭建与开发实战》
还有未来会持续更新的验证码突防、APP逆向、Python领域等一系列文章
1. 写在前面
说到验证码,必然是爬虫领域前行路上的一道坎!从Web到移动端哪都会有,不过话说回来目前各种成熟的解决方案倒也足以应付,正所谓有盾就有矛!本期网站讲述巧用第三方过点选验证码!
对于需求量、触发量并不大的建议前期对接三方,在这个过程中即可以收集后续自己训练的样本也能快速达到目标,避免前期投入过多的精力去研究训练识别模型(模型要达到满意的识别准确率这条路需要持续走)
再说现在验证码识别三方也是极为便宜!准确率经过我的测试目前100多次调用还未曾失败!(也许可能或许真的是大爷大妈在为你保驾护航)
爬虫的核心就是数据!如何拿到数据、如何有效且持续稳定的拿到数据才是最终的目标
这是使用三方平台过验证码顺带遗留保存下来的样本图片数据集,后续有需要的话自己也可以用来训练模型使用
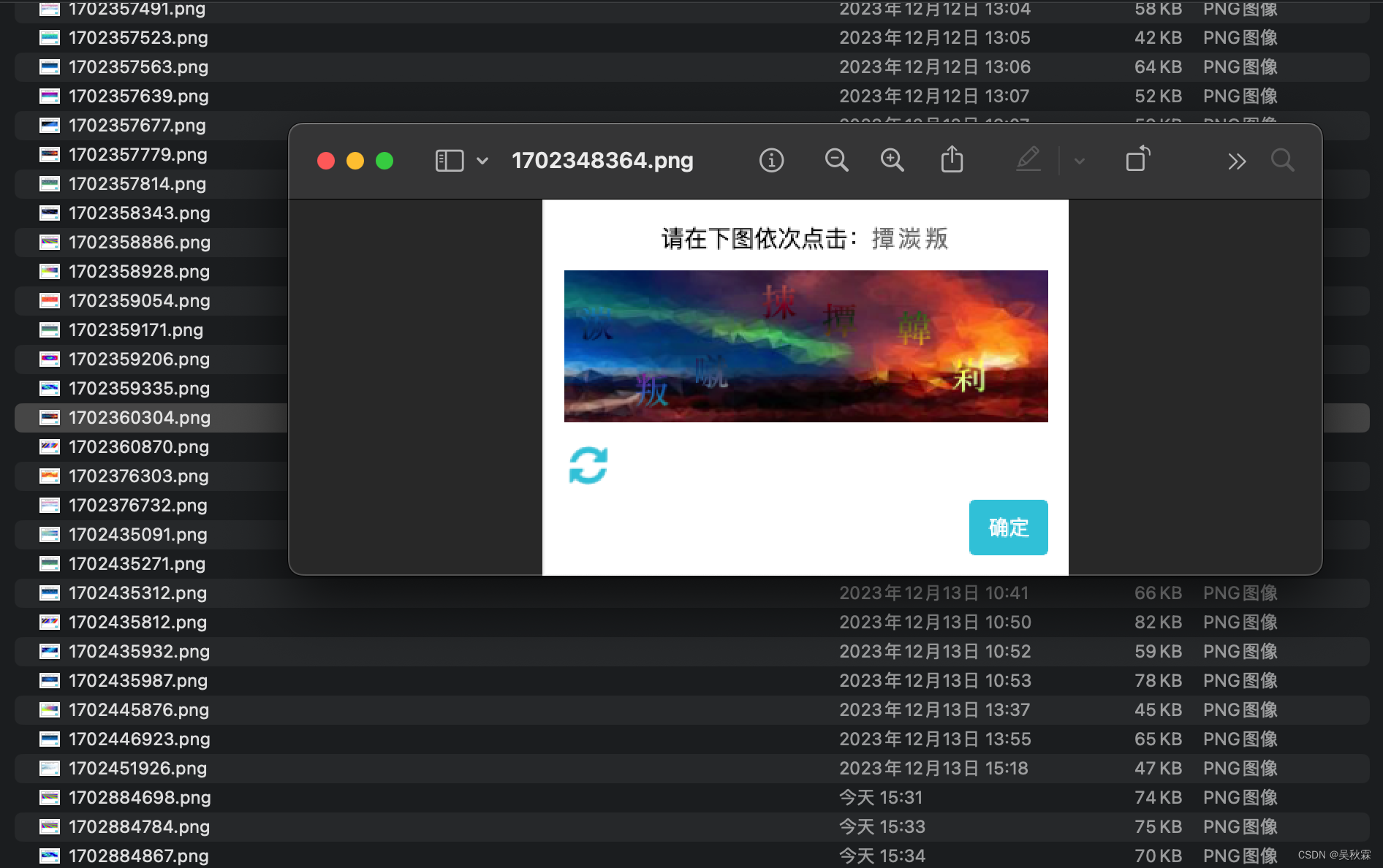
使用三方识别等于已经告诉了你下方点选验证码文字所属的具体坐标值,你需要实现的就是对验证码图片的裁剪、提交识别、模拟点击验证并提交结果

2. 风控描述
示例是一个招标平台的网站,这类数据风控目标往往会在IP+账号上做出一些策略!不定时会出现验证码检测,验证码一旦识别通过后,之前账号的Cookie信息将即刻失效,如下触发检测所示:
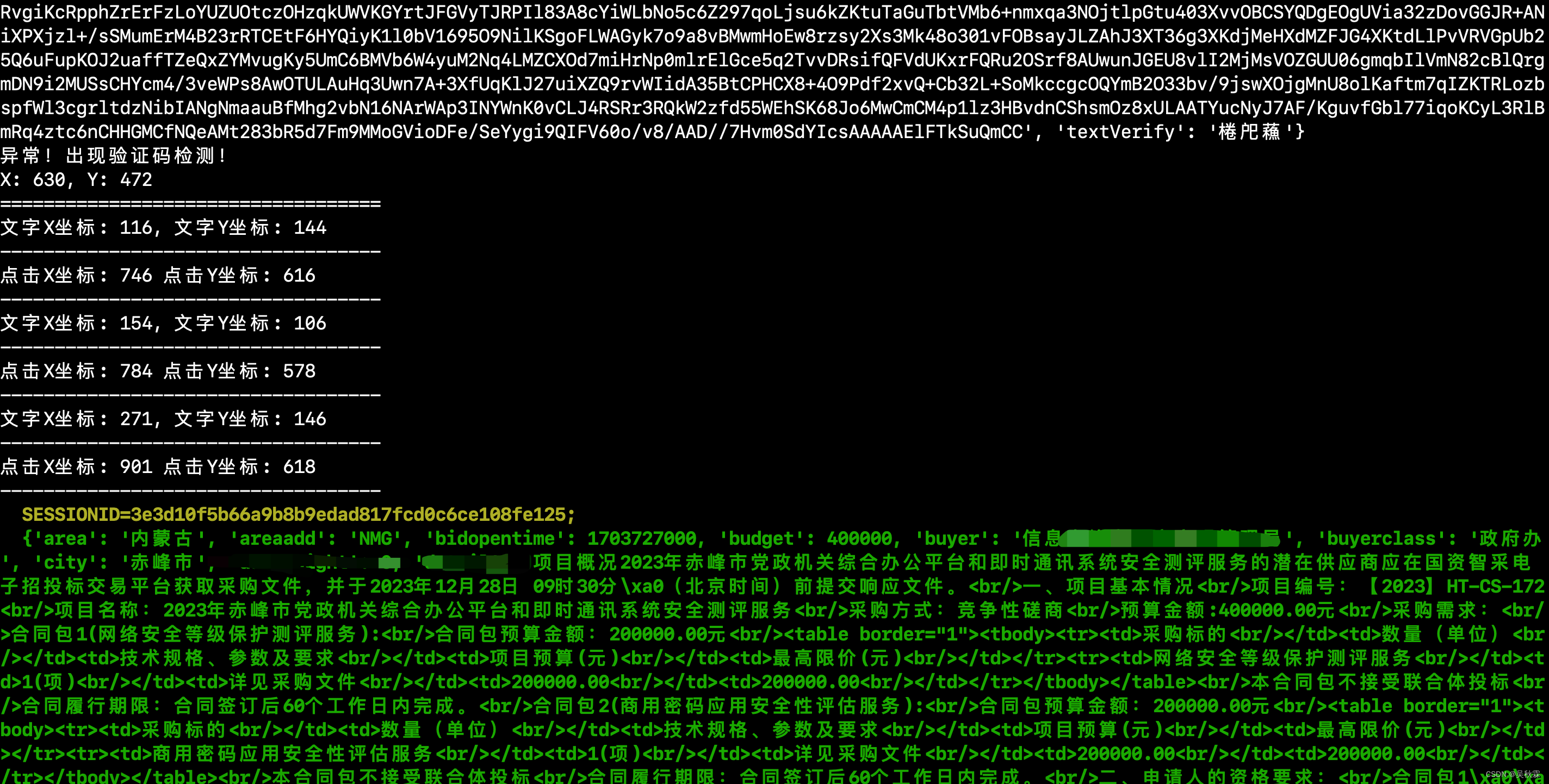
可以看到出现验证码时,接口能够拿到并返回经过编码后的验证码图片。但是接口的返回的只是一张文字底图,这里三方识别需要提供一张包含点击提示词的图片,如下所示:

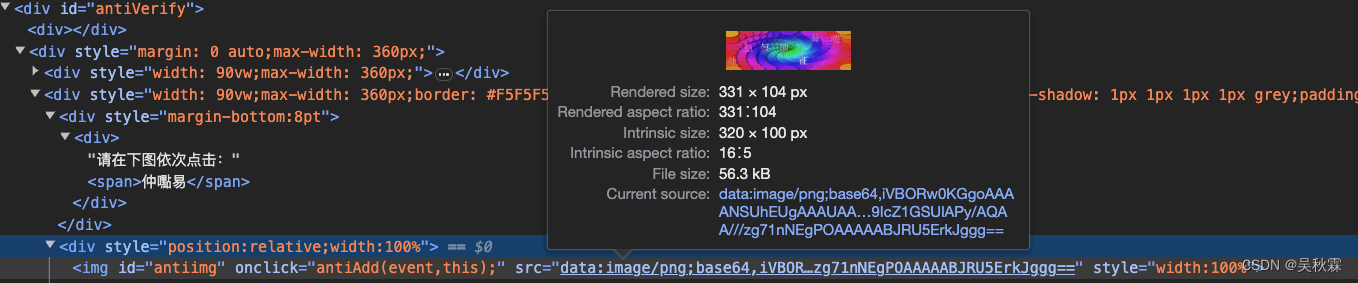
所以我们需要从网站页面自己去裁剪,如果网页中有嵌套链接是一张完整的含提示的验证码图片,就不需要自己去裁剪!当然这个网站并没有,网页链接依旧只是一张没有提示的底图,如下所示:
之后在验证码识别通过后爬虫将Cookie信息更新即可,采集的话肯定要使用协议。能走协议不要走自动化!
另外必须有一个Web挂着账号保持登录状态,它的作用不仅仅只是为了过验证码,因为它这个网站还有一个检测,如果账号没有保持在线状态,Cookie信息将过期,也就无法给到协议端采集数据!
还有对IP的检测与封禁,一般这类数据对账号、IP都有较高的风控检测!尤其是频率(账号特定时间段访问量、IP特定时间的访问量、或者其他组合策略),自己进行测试制定对抗策略即可,有资源这类风控就不难!
3. 验证码裁剪
裁剪验证码的图片我们可以根据网页元素去定位,首先找到验证码区域中辨识度高且固定的特征元素,如下所示:
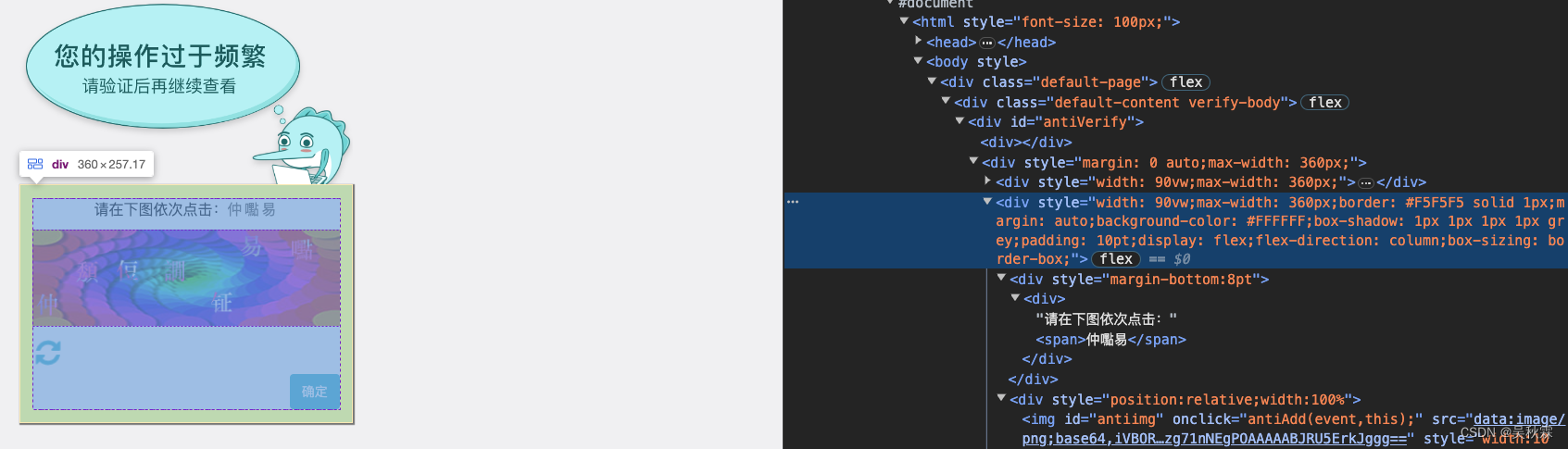
如上图所示,按照div元素所覆盖图片区域对图片进行保存,代码实现如下所示:
target_div = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, 'div[style*="width: 90vw;max-width: 360px;border"]')
)
)
driver.save_screenshot("validate_code.png")
保存下来的图片如下所示:

得到如上图片,继续按照上面的div标签元素去对保存图片进行裁剪,代码实现如下:
location = target_div.location
size = target_div.size
left, top, width, height = (
location["x"],
location["y"],
size["width"],
size["height"],
)
right, bottom = left + width, top + height
full_screenshot = Image.open("validate_code.png")
target_area = full_screenshot.crop((left, top, right, bottom))
image_file_name = int(time.time())
target_area.save("{}.png".format(image_file_name))
这里我按照时间戳对裁剪后的验证码识别图片进行统一保存,如上刚开始所看到的验证码文件那样,为了后续的识别模型训练而积累验证码样本
4. 验证码识别
图片自动裁剪保存后提交到三方平台接口进行识别,除了一些简单的字符型验证码,目前绝大部分验证码基本都会以坐标值的方式返回,拿到坐标后自行按照坐标实现点击功能
首先按照我们裁剪验证码的元素来进行定位,因为返回过来的坐标值,就是通过所裁剪提交的图片继续识别标注的,代码实现如下:
def get_location(element):
location = element.location
size = element.size
left, top, width, height = (
location["x"],
location["y"],
size["width"],
size["height"],
)
right, bottom = left + width, top + height
rect = {
"left": int(left),
"top": int(top),
"right": int(right),
"bottom": int(bottom),
}
return rect["left"], rect["top"]
X, Y = get_location(target_div)
上述代码根据target_div的定位拿到预坐标,接下来根据下图三方返回的坐标值,实现点击代码,如下所示:
coordinate是接口返回的识别结果,也就是需要点选文字的坐标值,实现点击代码如下:
coord_list = coordinate.split("|")
x, y = map(int, index.split(","))
ActionChains(self.driver).move_by_offset(X + x, Y + y).click().perform()
ActionChains(self.driver).move_by_offset(-(X + x), -(Y + y)).perform()
# 点击提交验证
driver.find_element(
By.XPATH, '//button[@οnclick="antiReload(1);"]'
).click()
# 验证通过后更新协议端采集Cookie
validate_cookies = self.driver.get_cookies()
session_cookie = next(
(
f"{
cookie['name']}={
cookie['value']};"
for cookie in validate_cookies
if cookie["name"] == "SESSIONID"
),
None,
)
好了,到这里又到了跟大家说再见的时候了。创作不易,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章