许多网站使用验证码来防御与其网站交互的机器人程序。
注册帐号
注册页面这里写链接内容
加载验证码图像
首先需要从表单中获取该图像。
图像是嵌入网页中的,而不时从其他URL加载过来的。
Pillow提供了一个便捷的Image类,其中包含了很多用于验证码处理的高级方法。
from io import BytesIO
import lxml.html
from PIL import Image
from DownLoad import Downloader
def get_captcha(html):
tree=lxml.html.fromstring(html)
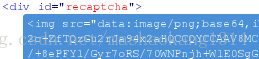
#图片在html中的信息
img_data=tree.cssselect('div#recaptcha img')[0].get('src')
#获取数据
img_data=img_data.partition(',')[-1]
# 解码图像数据,回到最初的二进制格式
binary_img_data=img_data.decode('base64')
#将二进制数据写入内存
file_like=BytesIO(binary_img_data)
# 以图片的形式打开
img=Image.open(file_like)
return img
if __name__=='__main__':
D=Downloader()
html=D('http://example.webscraping.com/places/default/user/register?_next=/places/default/index')
print get_captcha(html)
光学字符识别
光学字符识别用于从图像中抽取文本。使用开源的Tesseract OCR 引擎。安装后,再使用Python封装版本pytesseract。Tesseract的设计初衷是抽取更加典型的文本,比如背景统一的书页。如果想要更加有效的使用Tesseract,需要先修改验证码图像,去除其中的背景噪音,只保留文字部分。
D=Downloader()
html=D('http://example.webscraping.com/places/default/user/register?_next=/places/default/index')
img=get_captcha(html)
#保存原始图片
img.save('captcha original.png')
# 模式“L”为灰色图像,它的每个像素用8个bit表示,
# 0表示黑,255表示白,其他数字表示不同的灰度,
#转换为灰度图,以便后面提取文本
gray=img.convert('L')
gray.save('captcha_gray.png')
# 只有阙值小于1的像素才会被保留,也就是说只有全黑像素才会保留下来
bw=gray.point(lambda x:0 if x<1 else 255,'1')
bw.save('captcha_thresholded.png')原始图像

灰度图像

阙值化处理后的图像
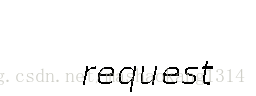
提取出来文字
img=Image.open('captcha_thresholded.png')
print pytesseract.image_to_string(img)
实现完整的注册
import cookielib
import string
import urllib
import urllib2
from login import parse_form
from checkcode import get_captcha
import pytesseract
REGESTER_URL='http://example.webscraping.com/places/default/user/register?_next=/places/default/index'
# 注册网站
def register(first_name,last_name,email,password):
cj=cookielib.CookieJar()
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
html=opener.open(REGESTER_URL).read()
# 获取表单
form=parse_form(html)
#填写表单
form['first_name']=first_name
form['last_name']=last_name
form['email']=email
form['password']=form['password_two']=password
# 获取html中的验证码
img=get_captcha(html)
#提取验证码中的文字
captcha=ocr(img)
#填写验证码表框
form['recaptcha_response_field']=captcha
encoded_data=urllib.urlencode(form)
request=urllib2.Request(REGESTER_URL,encoded_data)
response=opener.open(request)
# 判断是否注册成功,如果响应的不是原来的URL则注册成功
success='/user/register' not in response.geturl()
return success
# 获取验证码中的文字
def ocr(img):
gray=img.convert('L')
bw=gray.point(lambda x:0 if x<1 else 255,'1')
word=pytesseract.image_to_string(bw)
# 将字母转换为小写
ascii_word=''.join(c for c in word if c in string.letters).lower()
return ascii_word
if __name__=='__main__':
print register(first_name='Ma',last_name='ShaoK',email='[email protected]',password=1234)