一、概要
随着系统日益庞大、逻辑业务越来越复杂,系统架构由原来的单一系统到垂直系统,发展到现在的分布式系统。分布式系统中,可以做到公共业务模块的高可用,高容错性,高扩展性,然而,当系统越来越复杂时,需要考虑的东西自然也越来越多,要求也越来越高,比如服务路由、负载均衡等。此文将针对负载均衡算法进行讲解,不涉及具体的实现。
二、负载均衡算法
在分布式系统中,多台服务器同时提供一个服务,并统一到服务配置中心进行管理,消费者通过查询服务配置中心,获取到服务到地址列表,需要选取其中一台来发起RPC远程调用。如何选择,则取决于具体的负载均衡算法,对应于不同的场景,选择的负载均衡算法也不尽相同。负载均衡算法的种类有很多种,常见的负载均衡算法包括轮询法、随机法、源地址哈希法、加权轮询法、加权随机法、最小连接法、Latency-Aware等,应根据具体的使用场景选取对应的算法。
1、轮询(Round Robin)法
轮询很容易实现,将请求按顺序轮流分配到后台服务器上,均衡的对待每一台服务器,而不关心服务器实际的连接数和当前的系统负载。使用轮询策略的目的是,希望做到请求转移的绝对均衡,但付出的代价性能也是相当大的。为了保证pos变量的并发互斥,引入了重量级悲观锁synchronized,将会导致该轮询代码的并发吞吐量明显下降。
轮询法适用于机器性能相同的服务,一旦某台机器性能不好,极有可能产生木桶效应,性能差的机器扛不住更多的流量。
2、随机法
通过系统随机函数,根据后台服务器列表的大小值来随机选取其中一台进行访问。由概率概率统计理论可以得知,随着调用量的增大,其实际效果越来越接近于平均分配流量到后台的每一台服务器,也就是轮询法的效果。
同样地,它也不适用于机器性能有差异的分布式系统。
3、随机轮询法
所谓随机轮询,就是将随机法和轮询法结合起来,在轮询节点时,随机选择一个节点作为开始位置index,此后每次选择下一个节点来处理请求,即(index+1)%size。
这种方式只是在选择第一个节点用了随机方法,其他与轮询法无异,缺点跟轮询一样。
4、源地址哈希法
源地址哈希法的思想是根据服务消费者请求客户端的IP地址,通过哈希函数计算得到一个哈希值,将此哈希值和服务器列表的大小进行取模运算,得到的结果便是要访问的服务器地址的序号。采用源地址哈希法进行负载均衡,相同的IP客户端,如果服务器列表不变,将映射到同一个后台服务器进行访问。该方法适合访问缓存系统,如果为了增强缓存的命中率和单调性,可以用一致性哈希算法,相关博文在https://blog.csdn.net/okiwilldoit/article/details/51352743
5、加权轮询(Weight Round Robin)法
不同的后台服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不一样。跟配置高、负载低的机器分配更高的权重,使其能处理更多的请求,而配置低、负载高的机器,则给其分配较低的权重,降低其系统负载,加权轮询很好的处理了这一问题,并将请求按照顺序且根据权重分配给后端。Nginx的负载均衡默认算法是加权轮询算法。
Nginx负载均衡算法简介
有三个节点{a, b, c},他们的权重分别是{a=5, b=1, c=1}。发送7次请求,a会被分配5次,b会被分配1次,c会被分配1次。
一般的算法可能是:
1、轮训所有节点,找到一个最大权重节点;
2、选中的节点权重-1;
3、直到减到0,恢复该节点原始权重,继续轮询;
这样的算法看起来简单,最终效果是:{a, a, a, a, a, b, c},即前5次可能选中的都是a,这可能造成权重大的服务器造成过大压力的同时,小权重服务器还很闲。
Nginx的加权轮询算法将保持选择的平滑性,希望达到的效果可能是{a, b, a, a, c, a, a},即尽可能均匀的分摊节点,节点分配不再是连续的。
Nginx加权轮询算法
1、概念解释,每个节点有三个权重变量,分别是:
(1) weight: 约定权重,即在配置文件或初始化时约定好的每个节点的权重。
(2) effectiveWeight: 有效权重,初始化为weight。
在通讯过程中发现节点异常,则-1;
之后再次选取本节点,调用成功一次则+1,直达恢复到weight;
此变量的作用主要是节点异常,降低其权重。
(3) currentWeight: 节点当前权重,初始化为0。
2、算法逻辑
(1) 轮询所有节点,计算当前状态下所有节点的effectiveWeight之和totalWeight;
(2) currentWeight = currentWeight + effectiveWeight; 选出所有节点中currentWeight中最大的一个节点作为选中节点;
(3) 选中节点的currentWeight = currentWeight - totalWeight;
基于以上算法,我们看一个例子:
这时有三个节点{a, b, c},权重分别是{a=4, b=2, c=1},共7次请求,初始currentWeight值为{0, 0, 0},每次分配后的结果如下:
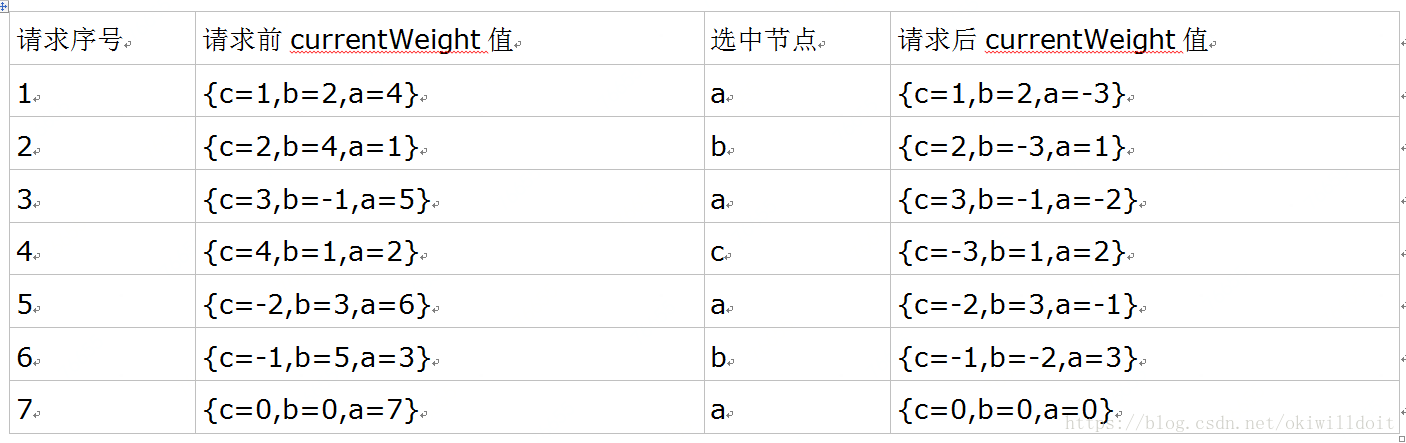
观察到七次调用选中的节点顺序为{a, b, a, c, a, b, a},a节点选中4次,b节点选中2次,c节点选中1次,算法保持了currentWeight值从初始值{c=0,b=0,a=0}到7次调用后又回到{c=0,b=0,a=0}。
参考文档为:https://www.cnblogs.com/markcd/p/8456870.html
6、加权随机(Weight Random)法
加权随机法跟加权轮询法类似,根据后台服务器不同的配置和负载情况,配置不同的权重。不同的是,它是按照权重来随机选取服务器的,而非顺序。
7、最小连接数法
前面我们费尽心思来实现服务消费者请求次数分配的均衡,我们知道这样做是没错的,可以为后端的多台服务器平均分配工作量,最大程度地提高服务器的利用率,但是,实际上,请求次数的均衡并不代表负载的均衡。因此我们需要介绍最小连接数法,最小连接数法比较灵活和智能,由于后台服务器的配置不尽相同,对请求的处理有快有慢,它正是根据后端服务器当前的连接情况,动态的选取其中当前积压连接数最少的一台服务器来处理当前请求,尽可能的提高后台服务器利用率,将负载合理的分流到每一台服务器。
8、Latency-Aware
与方法7类似,该方法也是为了让性能强的机器处理更多的请求,只不过方法7使用的指标是连接数,而该方法用的请求服务器的往返延迟(RTT),动态地选择延迟最低的节点处理当前请求。该方法的计算延迟的具体实现可以用EWMA算法来实现,它使用滑动窗口来计算移动平均耗时。具体代码如下:
public class EWMA {
private static final long serialVersionUID = 2979391326784043002L;
//时间类型枚举
public static enum Time {
MICROSECONDS(1),
MILLISECONDS(1000),
SECONDS(MILLISECONDS.getTime() * 1000),
MINUTES(SECONDS.getTime() * 60),
HOURS(MINUTES.getTime() * 60),
DAYS(HOURS.getTime() * 24),
WEEKS(DAYS.getTime() * 7);
private long micros;
private Time(long micros) {
this.micros = micros;
}
public long getTime() {
return this.micros;
}
}
//三个alpha常量,这些值和Unix系统计算负载时使用的标准alpha值相同
public static final double ONE_MINUTE_ALPHA = 1 - Math.exp(-5d / 60d / 1d);
public static final double FIVE_MINUTE_ALPHA = 1 - Math.exp(-5d / 60d / 5d);
public static final double FIFTEEN_MINUTE_ALPHA = 1 - Math.exp(-5d / 60d / 15d);
private long window;
private long alphaWindow;
private long last;
private double average;
private double alpha = -1D;
private boolean sliding = false;
private long requests;//请求量
private double weight;//权重
public EWMA() {
}
public EWMA sliding(double count, Time time) {
return this.sliding((long) (time.getTime() * count));
}
public EWMA sliding(long window) {
this.sliding = true;
this.window = window;
return this;
}
public EWMA withAlpha(double alpha) {
if (!(alpha > 0.0D && alpha <= 1.0D)) {
throw new IllegalArgumentException("Alpha must be between 0.0 and 1.0");
}
this.alpha = alpha;
return this;
}
public EWMA withAlphaWindow(long alphaWindow) {
this.alpha = -1;
this.alphaWindow = alphaWindow;
return this;
}
public EWMA withAlphaWindow(double count, Time time) {
return this.withAlphaWindow((long) (time.getTime() * count));
}
/**
* 默认使用当前时间更新移动平均值
*/
public void mark(){
mark(System.currentTimeMillis());
}
/**
* 更新移动平均值
* @param time
*/
public void mark(long time){
if(this.sliding){
//如果发生时间间隔大于窗口,则重置滑动窗口
if(time-this.last > this.window){
this.last = 0;
}
}
if(this.last == 0){
this.average = 0;
this.requests = 0;
this.last = time;
}
// 计算上一次和本次的时间差
long diff = time - this.last;
// 计算alpha
double alpha = this.alpha != -1.0 ? this.alpha : Math.exp(-1.0*((double)diff/this.alphaWindow));
// 计算当前平均值
this.average = (1.0-alpha)*diff + alpha*this.average;
this.last = time;
// 请求量加1
this.requests++;
// 计算权重值
// this.weight = this.average != 0 ? this.requests/this.average : -1;
}
//返回mark()方法多次调用的平均值
public double getAverage() {
return this.average;
}
//按照特定的时间单位来返回平均值,单位详见Time枚举
public double getAverageIn(Time time) {
return this.average == 0.0 ? this.average : this.average / time.getTime();
}
//返回特定时间度量内调用mark()的频率
public double getAverageRatePer(Time time) {
return this.average == 0.0 ? this.average : time.getTime() / this.average;
}
//返回mark()方法多次调用的权重值
public double getWeight() {return this.weight;}
public long getRequests() {return this.requests;}
public static void main(String[] args) {
//建立1分钟滑动窗口EWMA实例
EWMA ewma = new EWMA().
sliding(1.0, Time.MINUTES).
withAlpha(EWMA.ONE_MINUTE_ALPHA).
withAlphaWindow(1.0, EWMA.Time.MINUTES);
int randomSleep = 0;
long markVal = System.currentTimeMillis() * 1000;//单位为微秒
try {
ewma.mark(markVal);
for (int i = 1; i <= 10000000; i++) {
randomSleep = util.get_rand_32() % 1500;
markVal += randomSleep;
ewma.mark(markVal);
if (i % 1000 == 0) {
System.out.println("Round: " + i + ", Time: " + randomSleep
+ ", Requests: " + ewma.getRequests()
+ ", Average: " + ewma.getAverage()
+ ", Weight:" + ewma.getWeight());
}
}
}
catch (Exception e) {
e.printStackTrace();
}
}
}Twitter的负载均衡算法基于这种思想,不过实现起来更加简单,即P2C算法。首先随机选取两个节点,在这两个节点中选择延迟低,或者连接数小的节点处理请求,这样兼顾了随机性,又兼顾了机器的性能,实现很简单。
具体参见:https://linkerd.io/1/features/load-balancing/。