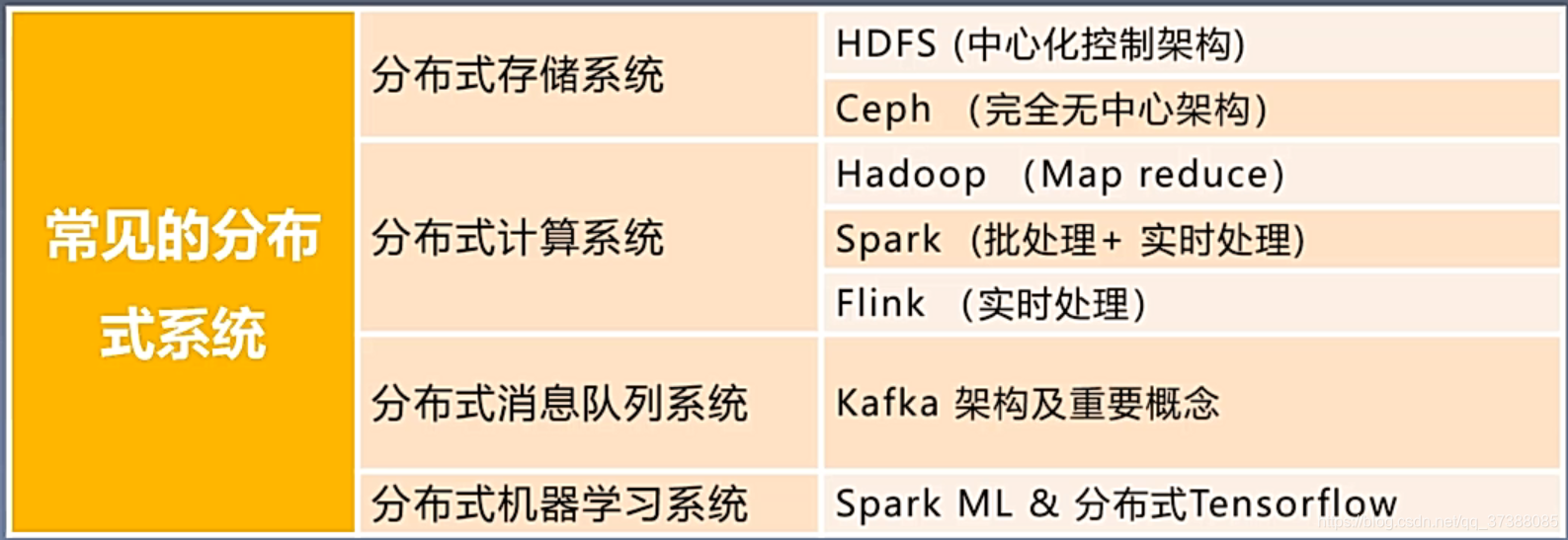
目录
1、分布式存储系统
分布式存储系统主要分为两个大类:
- 中间控制节点架构
- 完全无中心架构
1.1 中间控制节点架构
定义:以单独元数据服务器为中间控制,具体数据存储服务器为分布式存储的架构存储;
代表:Hadoop Distributed File System (HDFS);
元数据:描述数据的数据(包含具体数据的路径,以及相关信息);
架构图:
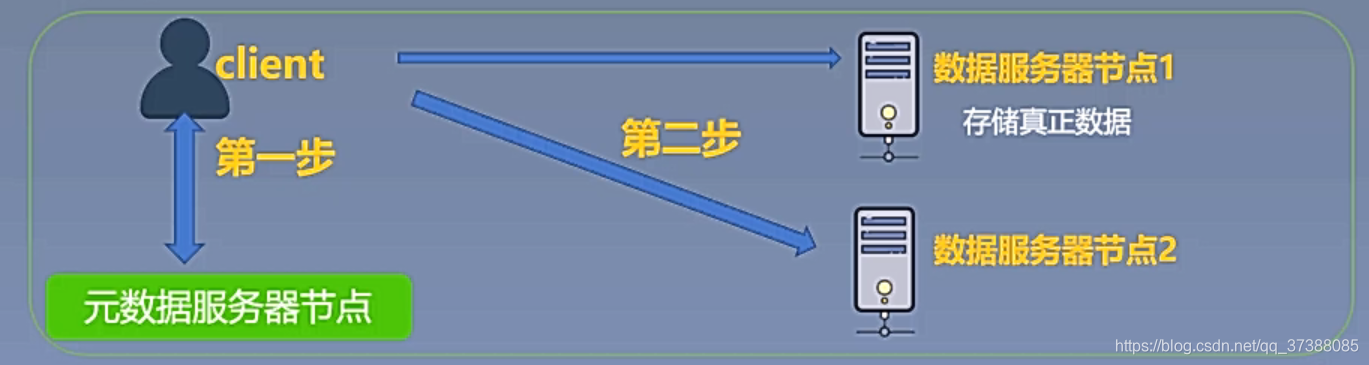
从架构图可以看到,用户第一步先访问元数据的服务器节点,这个元数据服务器为中间控制;每一次访问真正数据前,都需要先访问元数据服务节点,元服务器节点存储的是元数据,元数据是描述数据的数据,元数据存储了真实数据的描述信息,包含具体数据的路径以及相关信息;
中间控制节点架构的代表为HDFS,下面举一个例子:
| 数据类型 | 描述 | 位置 |
|---|---|---|
| 学生信息 | 学生的相关信息 | 服务器1 |
| 学生成绩 | 学生的考试成绩 | 服务器2 |
元数据是描述数据的数据,包含具体数据的数据路径和相关信息,表格中就是一个元数据,其包括具体数据的数据类型、描述和具体存储位置;
所以当用户想访问真实数据前,必须先访问元数据服务器节点;
HDFS概括图
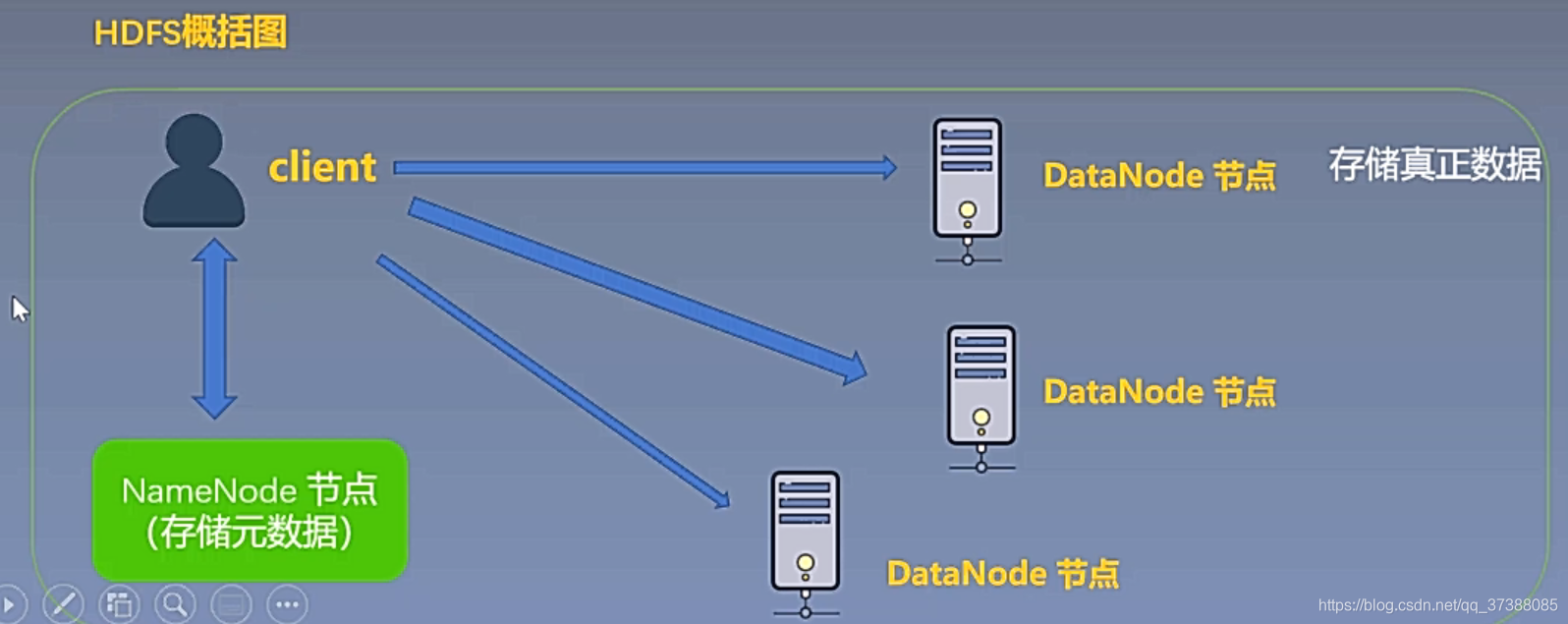
- Namenode:负责管理元数据(真正数据的位置及相关信息);
- Datanode:负责存储实际数据;
HDFS中元数据服务器节点被称为NameNode节点,存储真实数据的节点被称为DataNode节点;
中间控制节点架构特点
- 用户进行数据读写时,先访问存储元数据的节点(Namenode),得到真正数据的存储信息后,去真正存储数据的节点(Datanode)进行读写;
- 存储元数据的节点通常为单一的服务器节点,但是因为访问元数据节点的频率和访问量都相对数据节点较小,所以不太可能会出现性能瓶颈;
1.2 完全无中心架构
定义:客户端通过设备映射关系计算出具体数据的位置,客户端直接访问;
代表:计算模式(Ceph);
流程介绍:客户端通过Mon通信服务,计算得到客户端需要写到的具体文件路径;
架构图
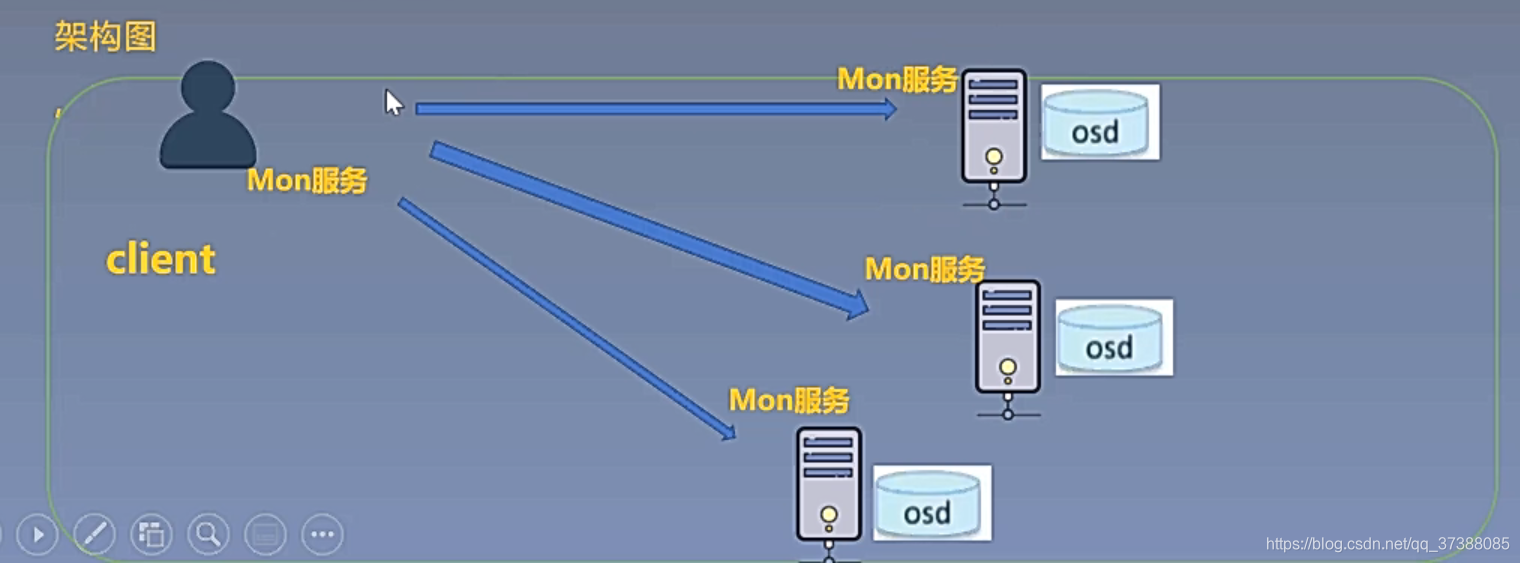
如上图,客户端有一个Mon服务,客户端根据Mon服务经过一系列的运算可以得到一个想要访问的数据的具体地址;Mon在客户端和数据段都存在,两者之间会有一个通信来保持相关信息的更新,保持相关节点的描述信息更新;客户端通过Mon服务和对应的信息可以计算得到想要访问的具体数据的具体文件路径,以便于直接访问;
完全无中心架构的特点
- 与中间控制节点架构相似的地方在于真实的数据都是分布式存储在各个服务器节点;
- 与中间控制节点架构不同的地方在于,完全无中心架构中没有类似于Namenode的中心节点;客户端通过设备映射关系计算出其读写数据的数据节点位置,从而可以直接访问数据存储节点;
2、分布式计算系统
常用的分布式计算系统主要分为三类:
- Hadoop Map Reduce
- Spark
- Flink
2.1 Hadoop Map Reduce
定义:一种大数据编程模型,将数据处理运用Map和Reduce的概念进行分而治之的处理;
理念:分而治之,将大任务划分成小任务;
应用场景:批处理(一次性处理数据);

下面通过计数实例解释图进行分析:
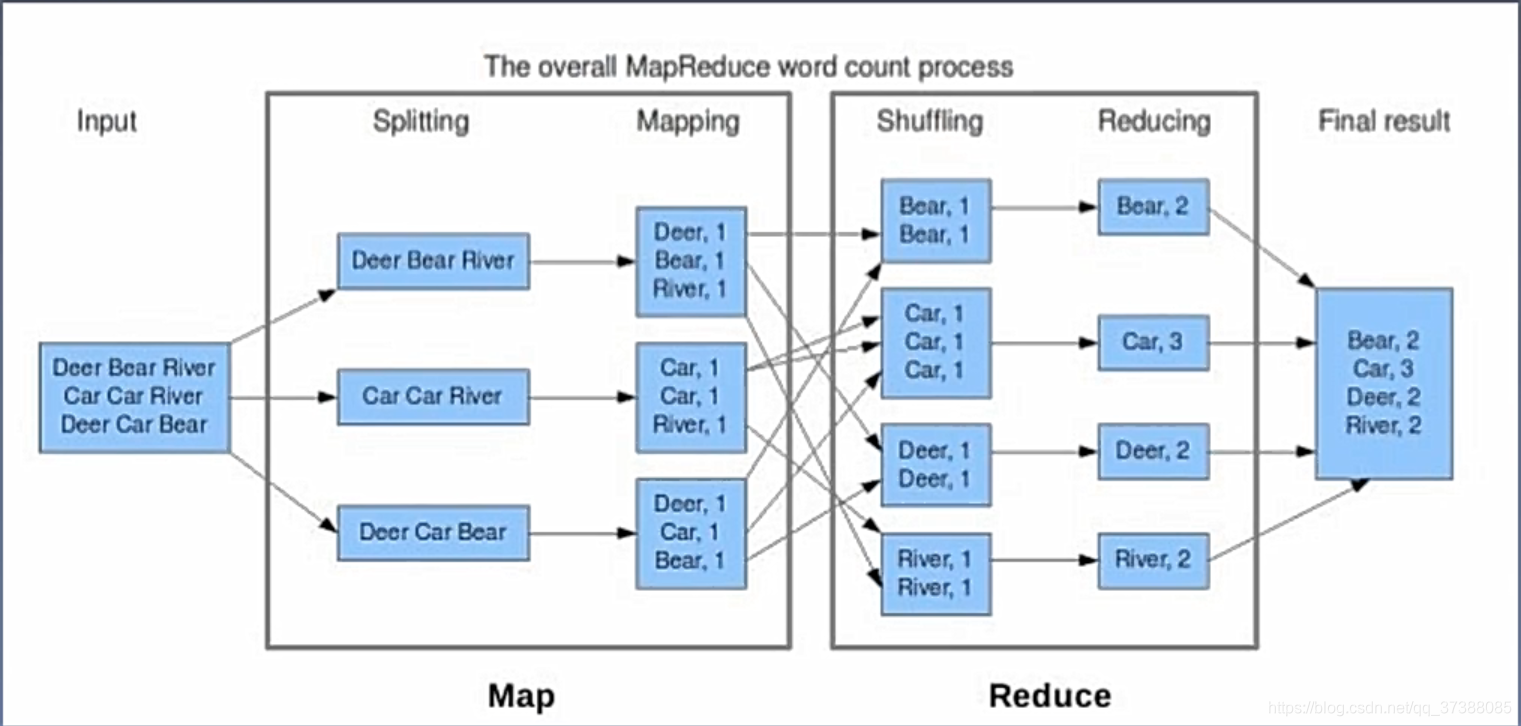
给定一串英文短句,在map端会细分为splitting和mapping,splitting会将英文短语细分为三个部分,然后进行mapping操作,计算出每种单词的计数;Map结束后会进入Reduce端,Reduce中有Shuffling和Reducing,Shuffling会把相同的key放到同一个分区,之后执行Reducing的操作,也就是加法操作;
Hadoop Map Reduce具体的应用程序流程图:

Hadoop Map Reduce的特点:
- 分布式计算;
- 中间结果都存放在硬盘;
- 无法查询上一步的结果;
- 效率一般;
在机器学习训练的时候我们会不断查看过去的数据,这在Hadoop中是没有办法实现的,所以我们迎来了第二个比较好的计算框架Spark;
2.2 Spark
定义:基于内存优化的分布式大数据计算框架;
理念:分而治之,将大任务划分成小任务,引入RDD概念;
应用场景:批处理(效率最好) + 流处理(微小批处理);
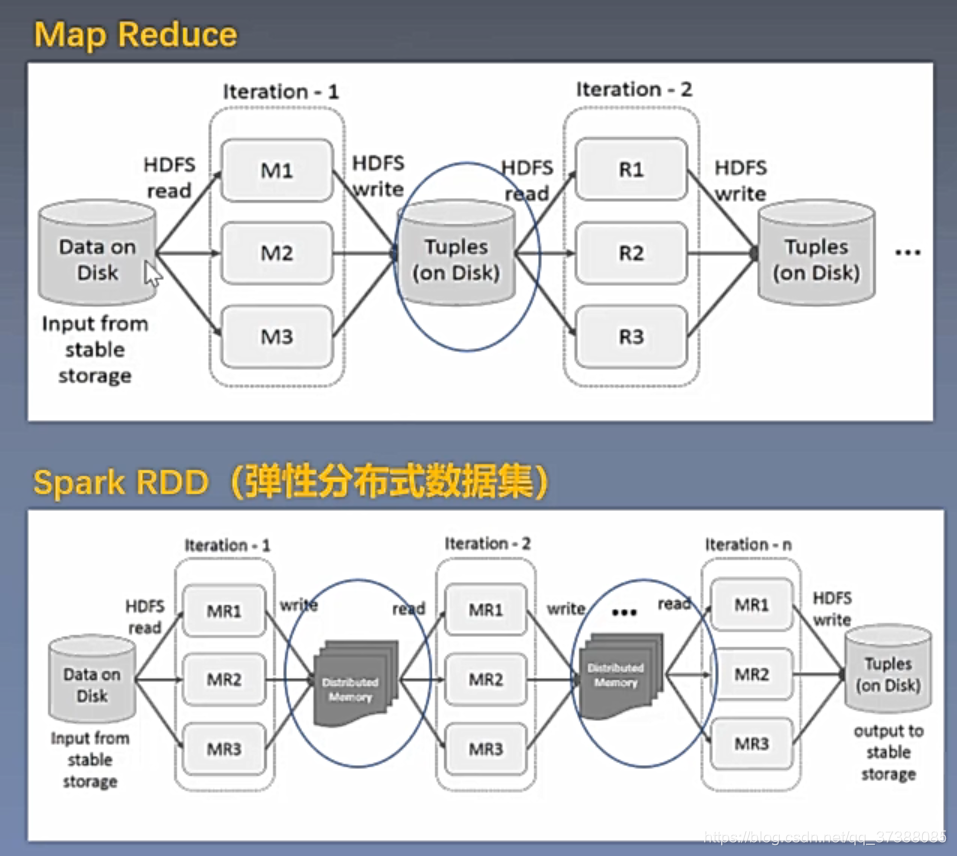
在Spark中,每一个执行计划的中间结果都是写在分布式内存中;当需要读取数据的时候,可以直接从分布式内存中直接进行读取;这种基于内存优化的分布式大数据框架在单纯计算的时候高于Hadoop Map Reduce,所以Spark在批处理中效率是最好的,而且Spark也可以做流处理,流处理就是实时的处理;
计数实例解释图

Spark应用程序流程图
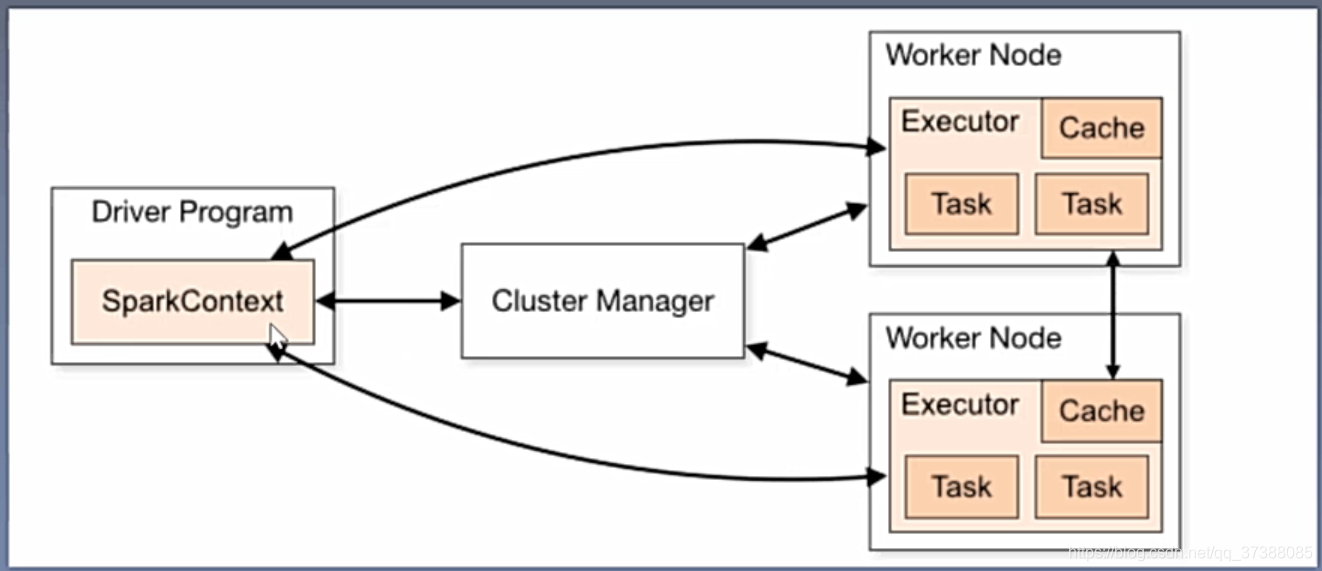
图中的Cluster Manager是集群管理器,Spark集群上有Master Node(主节点)和Worker Node(从节点),主节点用于监测从节点,从节点会真正执行分配的任务;集群管理器的作用是协调资源并且检测从节点的资源使用情况;
2.3 Flink
定义:分布式大数据处理框架,对流数据可以进行计算;
理念:实时处理;
应用场景:流处理;
架构图:
应用程序流程图:
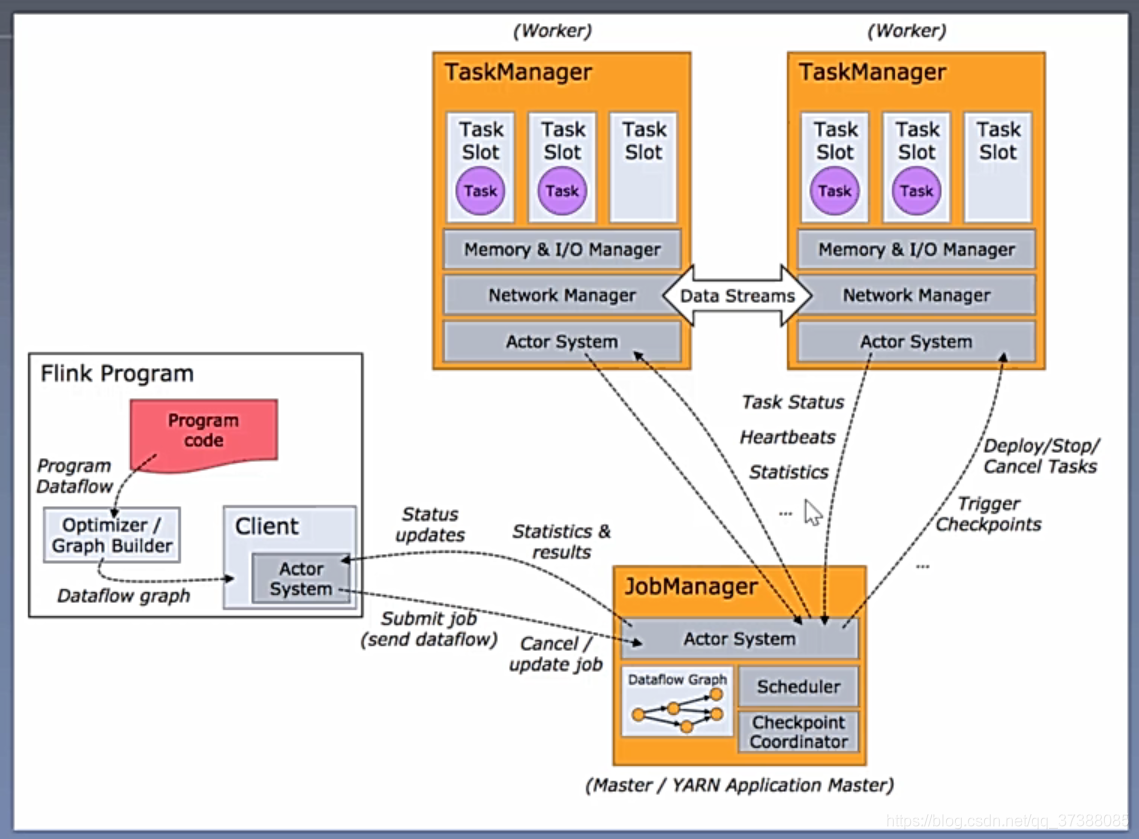
2.4 Hadoop & Spark & Flink 比较
| Hadoop Map Reduce | Spark | Flink | |
|---|---|---|---|
| 应用场景 | 批处理 | 批处理+实时处理 | 实时处理 |
| 效率 | 中间结果在硬盘,效率一般 | 提供内存优化,批处理效率最好,实时处理为微型批处理 | 真正的实时处理效率最高的开源框架 |
| 功能性 | 无法交互式查询 | 可以交互式查询 | 可以实时进行状态交互式查询 |
| 支持语言 | Java,C++ | Java,Scala,Python,R | Java,Scala,Python,R |
| 扩展包 | HDFS,YARN | Spark Graph,Spark ML | Flink Sql |
3、分布式消息队列系统
Kafka:Kafka是一个分布式消息队列。具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑计算;
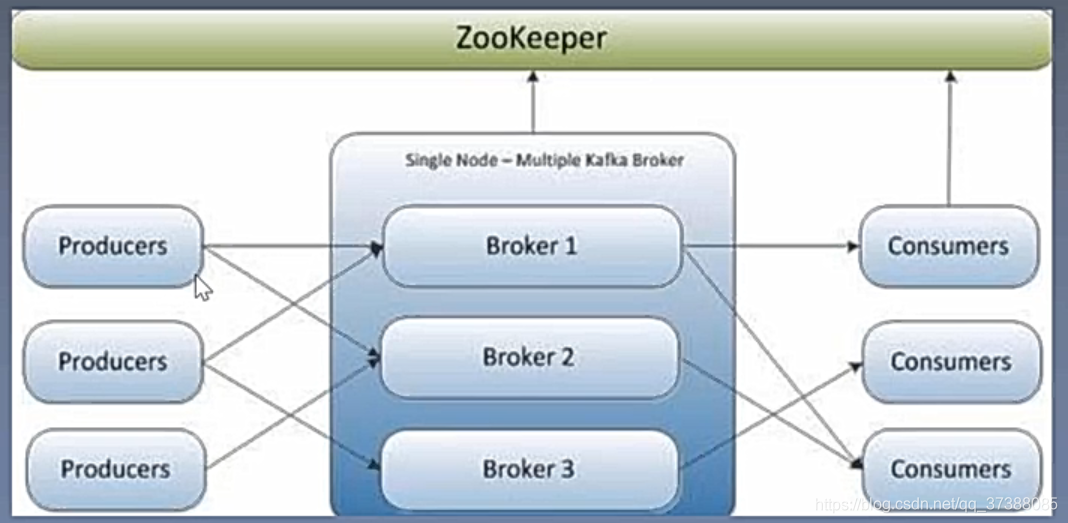
Producers可以想象为产生数据的进程,产生的数据会存放到Kafka中;消费者是可以读取Kafka中数据的进程;
Kafka重要概念
- Topic:定义特定的消息,可以让生产者和消费者都从该Topic中进行数据读写;
- Partition:一个Topic可以分成好几个分区;
- Broker:服务器存储数据,可以做备份;

4、分布式机器学习系统
主要介绍两个:
- Spark ML
- 分布式TensorFlow
4.1 Spark ML
定义:以Spark为计算引擎的分布式机器学习框架;
特点:提供一个分布式的模型训练环境;提供一个训练数据集分布式处理的环境;
常见机器学习框架比较:Sklearn、Tensorflow、Pytorch;
4.2 分布式TensorFlow
分布式TensorFlow,是在分布式集群上进行训练;
5、回顾与总结