版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/vivizhangyan/article/details/81091509
最小值和梯度下降
1优化问题就是求最小值的问题
2梯度下降:
(1)梯度计算:
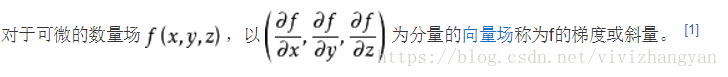
(2)梯度下降法:
a.先求出所在位置的梯度,然后取这个梯度的负方向(x沿着极小值前进的方向)
b.更新,梯度乘以一个系数,用来控制步长的大小(学习率)
c.终止条件:设定梯度小于某一个阈值
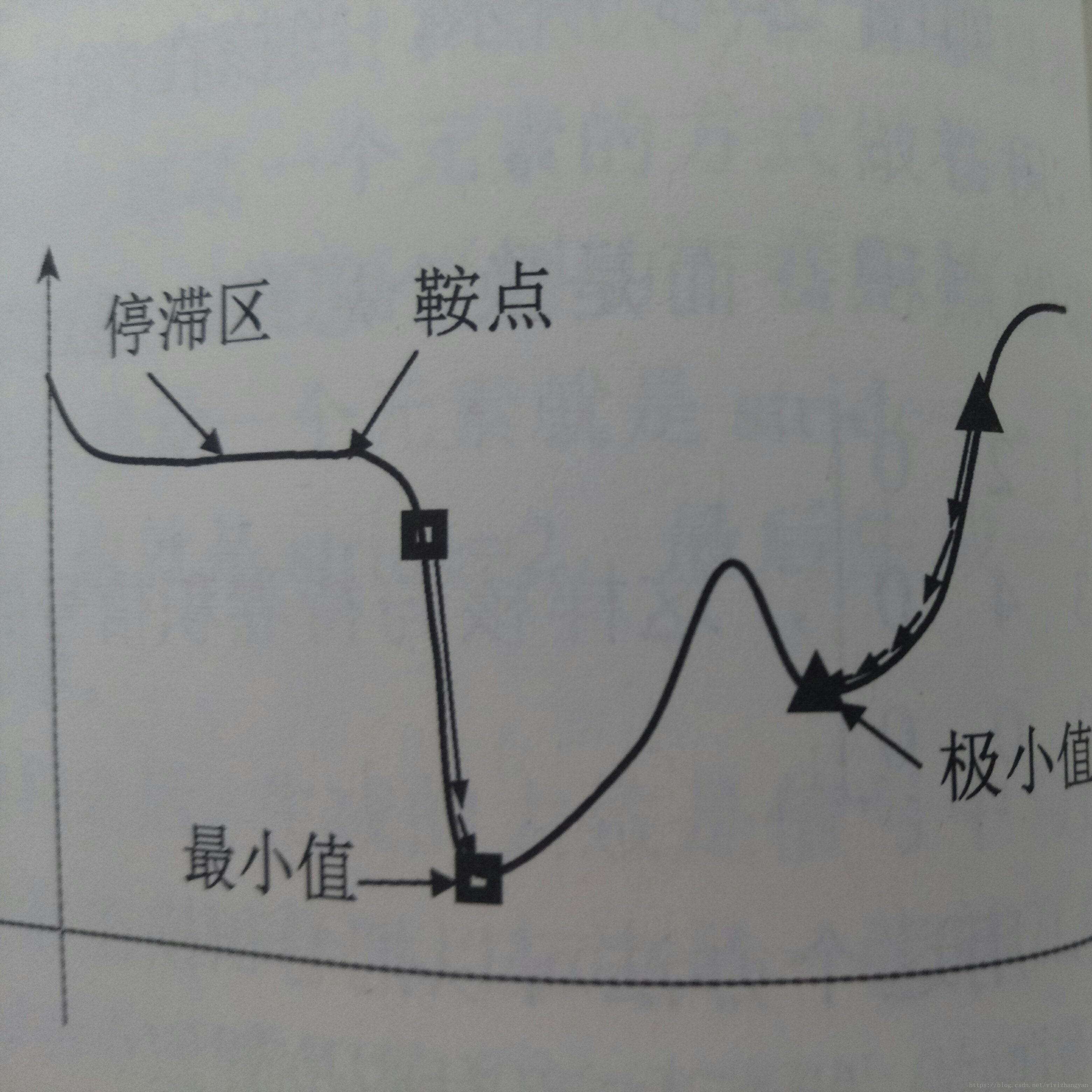
(3)极值和鞍点
a.鞍点是梯度为0的点
b,局部的最小值为极值点
c.梯度很小的区域为停滞区
2.冲量(Momentum)
(1)与惯性类似,可以成为动量
(2)与传统的GD不一样在于代表上一刻的动量加入到每一次迭代中,停止标准多了一个冲量小于某一个值
(3)NAG:对上一种方法的改进,求梯度的位置不是当前位置,而是沿着当前冲量乘以衰减系数前进一步后所在的位置,对于平滑度较高的函数有很多的效果
3.牛顿法
(1)Newton-Raphson算法:给函数当前位置进行一阶展开,然后用这个一阶展开作为下一次迭代的位置
(2)Newton法:每次迭代时,对所在位置要求的函数做一个二次近似,对于高维则采用Hessian矩阵。好处是不需要指定学习率
4.学习率和自适应步长
(1)学习率衰减:前期用较大的学习率加速收敛,后期采用较小的学习率保证稳定。按步长衰减学习率的公式:
5.自适应算法
a.AdaGrad:对每个变量用不同的学习率,即每个变量随着学习的进行,根据历史学习率累积总量来决定当前学习率的衰减程度。在机器学习中,该方法适合处理样本稀疏的问题,需要注意的是初始的全局学习率需要手工设定。
b.AdaDelta: AdaGrad的改进版
具体表现为两点:
(1)将累积梯度信息从全部历史梯度变成当前时间向前的一个窗口期内的累积
(2)设置伪牛顿步长解决手动设置全局学习率的问题
c.其他自适应算法
RMSProp,Adam,Adammax
6.损失函数(目标函数)
(1)损失函数用来度量模型预测的值和真实值得误差
(2)由于损失函数不连续且高纬度不可计算,可以考虑转换为容易计算的函数,输出结果为概率(分类问题),这样只需要找到一组参数进行估计。
(3)通常采用似然函数进行,因为优化算法通常求最小值,用负对数似然更加直观。
7.逻辑回归
把任何输入通过变换转化为0~1之间的数值
8.Softmax:将输出转换为概率
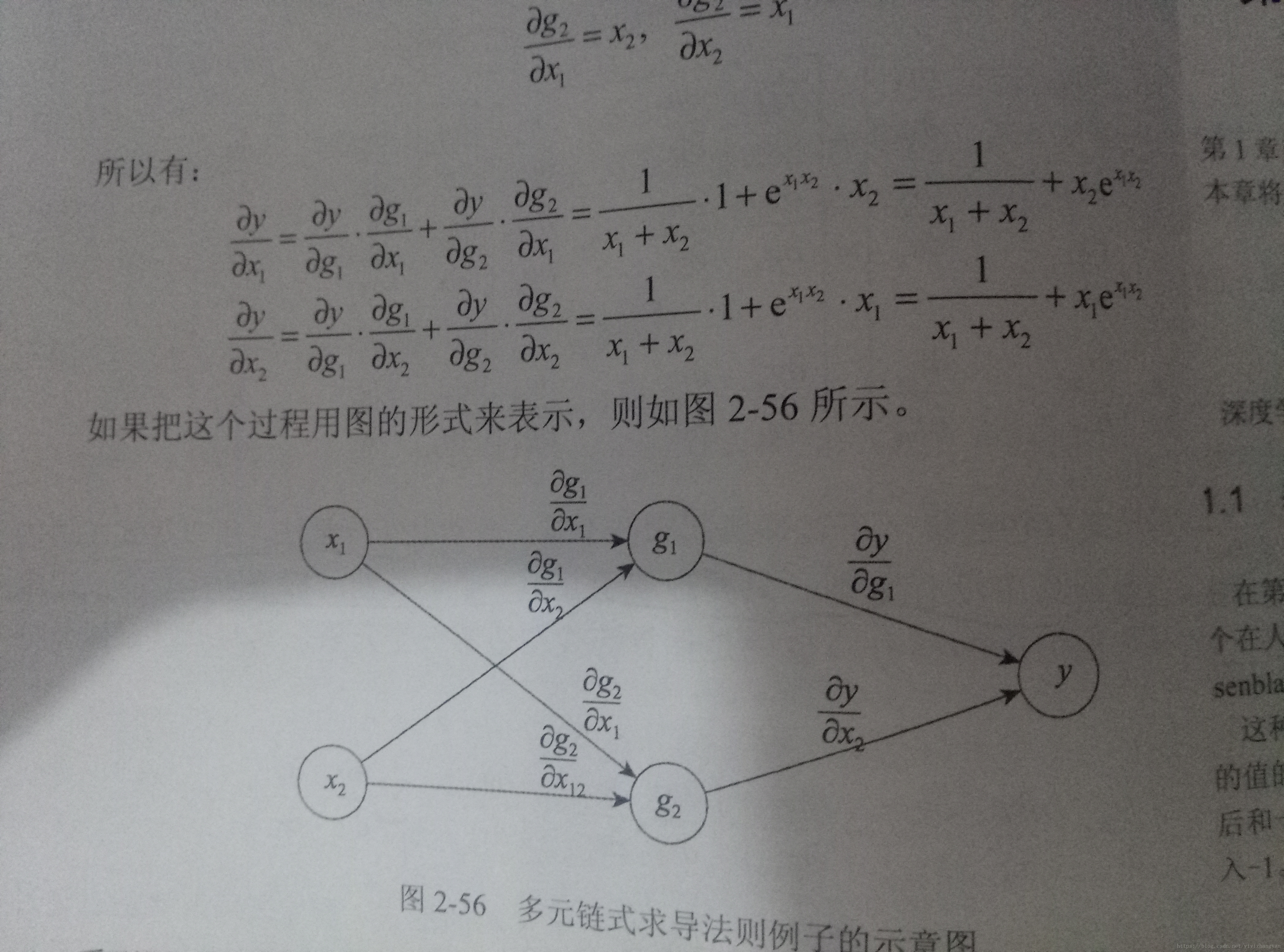
9.链式求导法则