Master/slave 主从,单点故障处理
有一个向外提供的服务,服务必须7*24小时提供服务,不能有单点故障。所以采用集群的方式,采用master、slave的结构。一台主机多台备机。主机向外提供服务,备机负责监听主机的状态,一旦主机宕机,备机要迅速接代主机继续向外提供服务。从备机选择一台作为主机,就是master选举。
主从有多重方式,或者有成熟的产品,但是如果我们自己实现一个主从,该如何下手?像mysql-cluster集群版本。等等…很多产品内部的实现。现在我们来描述一个Zookeeper生成主从单点故障后切换服务的应用。
原理解析
右边三台主机会尝试创建master节点,谁创建成功了,就是master,向外提供。其他两台就是slave。
所有slave必须关注master的删除事件(临时节点,如果服务器宕机了,Zookeeper会自动把master节点删除)。如果master宕机了,会进行新一轮的master选举。本次我们主要关注master选举,服务注册、发现先不讨论。
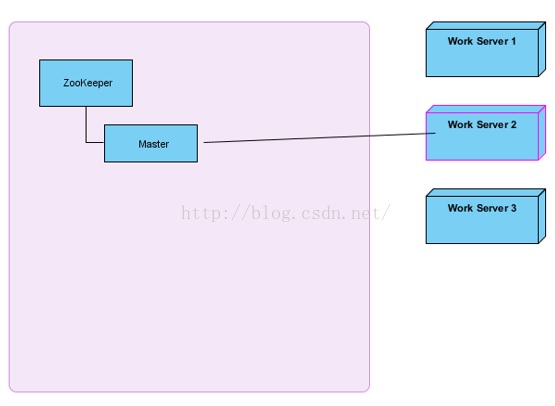
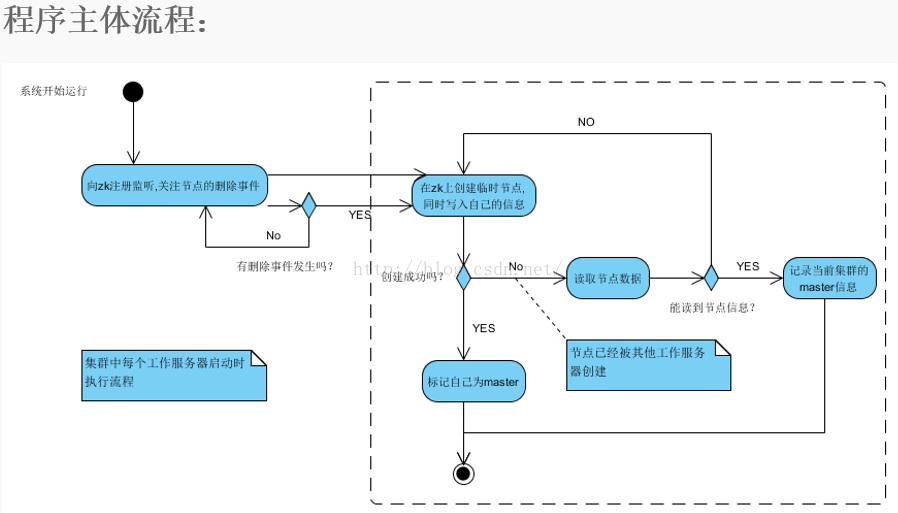
其实蛮简单的,zookeeper支持临时数据的创建和持久节点的创建,首先我们多个服务节点启动的时候去想zookeeper创建临时数据,创建成功,则意味着这台机器是master,之后的其他服务节点再去创建同样的临时数据时,zookeeper是不支持创建的。就会创建失败,这时去监听zookeeper临时数据的删除。(临时数据的删除发生在master 与 zookeeper session失效的时候)在临时数据被删除的时候,我们的其他服务节点,就去抢着再次创建临时数据,创建的成功的服务节点从salve切换成master。其他salve又失败,然后继续监听这个临时数据。这就是注册到zookeeper做master/salve 服务的支持。非常简单且高效。
临时数据:zookeeper 的 path。
不贴代码了,主从服务的最核心的实现,当然服务的提供还需要做业务的处理,如:
apache lucene 服务的索引服务,当master的某个端口的接口服务崩掉时候,我们的slave抢到master角色之后,启动新的端口接口服务。这是一个最简单的应用。真实的场景要复杂得多。代码下一天在贴出来,玩的就是先理论后实践.