转载:http://www.cnblogs.com/nevermorewang/p/5611807.html
窃以为,对于zookeeper这种东西,仅仅知道怎么安装是远远不够的(废话么这不是,,,),至少要对其几个典型的应用场景进行了解,才能比较全面的知道zk究竟能干啥,怎么玩儿,以后的日子里才能知道这货如何能为我所用。于是,有了如下的学习:
我们知道zookeeper可以用于搭建高可用服务框架,主要先看以下几个应用场景:
1、 master的选举基本思路和编码实现
2、 数据的发布和订阅
3、 软负载均衡
4、 分布式队列
5、 分布式锁
6、 命名服务
目前zookeeper常用的开发包有zkclient跟curator,后者更为方便,日常开发使用较多。
----------------正文分割线-----------------------------------------------------------
master选举
1、使用场景及结构
现在很多时候我们的服务需要7*24小时工作,假如一台机器挂了,我们希望能有其它机器顶替它继续工作。此类问题现在多采用master-salve模式,也就是常说的主从模式,正常情况下主机提供服务,备机负责监听主机状态,当主机异常时,可以自动切换到备机继续提供服务(这里有点儿类似于数据库主库跟备库,备机正常情况下只监听,不工作),这个切换过程中选出下一个主机的过程就是master选举。
对于以上提到的场景,传统的解决方式是采用一个备用节点,这个备用节点定期给当前主节点发送ping包,主节点收到ping包后会向备用节点发送应答ack,当备用节点收到应答,就认为主节点还活着,让它继续提供服务,否则就认为主节点挂掉了,自己将开始行使主节点职责。如图1所示:
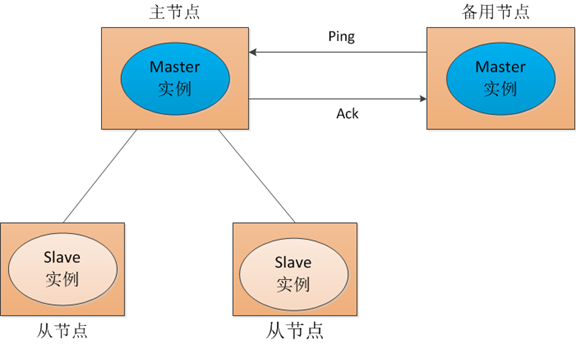
图1
但这种方式会存在一个隐患,就是网络故障问题。看一下图2:
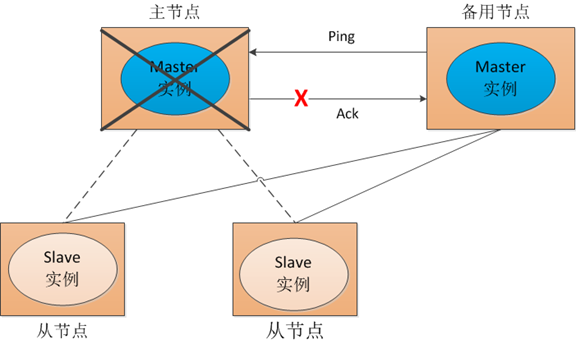
图2
也就是说,我们的主节点并没有挂掉,只是在备用节点ping主节点,请求应答的时候发生网络故障,这样我们的备用节点同样收不到应答,就会认为主节点挂掉,然后备机会启动自己的master实例。这样就会导致系统中有两个主节点,也就是双master。出现双master以后,我们的从节点会将它做的事情一部分汇报给主节点,一部分汇报给备用节点,这样服务就乱套了。为了防止这种情况出现,我们可以考虑采用zookeeper,虽然它不能阻止网络故障的出现,但它能保证同一时刻系统中只存在一个主节点。我们来看zookeeper是怎么实现的:
在此处,抢主程序是包含在服务程序中,需要程序员来手动写抢主逻辑的,比如当当开源框架elastic-job中,就有关于选主的部分,参见:elastic-job-core/main/java/com/dangdang/ddframe/job/internal/election文件夹下的选主代码。
一点额外的话:zookeeper自己在集群环境下的抢主算法有三种,可以通过配置文件来设定,默认采用FastLeaderElection,不作赘述;此处主要讨论集群环境中,应用程序利用master的特点,自己选主的过程。程序自己选主,每个人都有自己的一套算法,有采用“最小编号”的,有采用类似“多数投票”的,各有优劣,本文的算法仅作演示理解使用:
结构图:
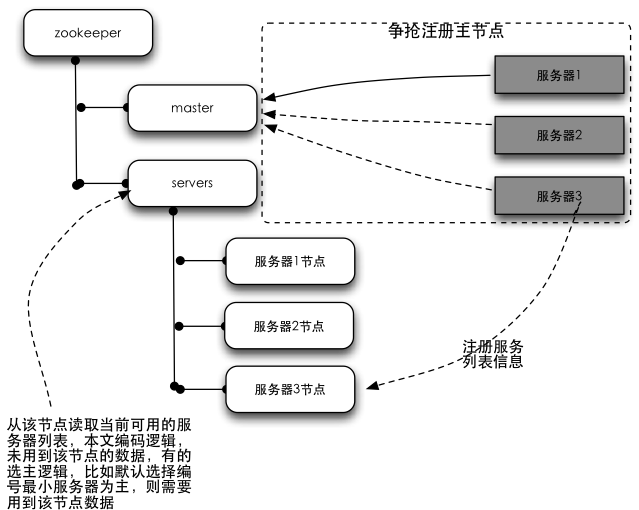
结构图解释:左侧树状结构为zookeeper集群,右侧为程序服务器。所有的服务器在启动的时候,都会订阅zookeeper中master节点的删除事件,以便在主服务器挂掉的时候进行抢主操作;所有服务器同时会在servers节点下注册一个临时节点(保存自己的基本信息),以便于应用程序读取当前可用的服务器列表。
选主原理介绍:zookeeper的节点有两种类型,持久节点跟临时节点。临时节点有个特性,就是如果注册这个节点的机器失去连接(通常是宕机),那么这个节点会被zookeeper删除。选主过程就是利用这个特性,在服务器启动的时候,去zookeeper特定的一个目录下注册一个临时节点(这个节点作为master,谁注册了这个节点谁就是master),注册的时候,如果发现该节点已经存在,则说明已经有别的服务器注册了(也就是有别的服务器已经抢主成功),那么当前服务器只能放弃抢主,作为从机存在。同时,抢主失败的当前服务器需要订阅该临时节点的删除事件,以便该节点删除时(也就是注册该节点的服务器宕机了或者网络断了之类的)进行再次抢主操作。从机具体需要去哪里注册服务器列表的临时节点,节点保存什么信息,根据具体的业务不同自行约定。选主的过程,其实就是简单的争抢在zookeeper注册临时节点的操作,谁注册了约定的临时节点,谁就是master。
ps:本文的例子中,并未用到结构图server节点下的数据。但换一种算法或者业务场景就会用到,算法比如提到的最小编号,主要逻辑是主节点挂掉后,从节点里边编号最小的成为主节点,此时会用到该节点内容。换一种业务场景:集群环境中,有很多任务要处理, 主节点负责接收任务,并根据一定算法将任务分配到不同的机器上执行;这种情况下,主节点跟从节点的职责也是不同的,主节点挂掉也会涉及到从节点进行master选举的问题。这种情况下,很显然,作为主节点需要知道当前有多少个从节点还活着,那么此时也会需要用到servers节点下的数据了。
2、编码实现
主要有两个类,WorkServer为主服务类,RunningData用于记录运行数据。因为是简单的demo,我们只做抢master节点的编码,对于从节点应该去哪里注册服务列表信息,不作编码。
采用zkClient实现,代码如下:
WorkServer类:
 View Code
View Code
RunningData类:
View Code
说明:在实际生产环境中,可能会由于插拔网线等导致网络短时的不稳定,也就是网络抖动。由于正式生产环境中可能server在zk上注册的信息是比较多的,而且server的数量也是比较多的,那么每一次切换主机,每台server要同步的数据量(比如要获取谁是master,当前有哪些salve等信息,具体视业务不同而定)也是比较大的。那么我们希望,这种短时间的网络抖动最好不要影响我们的系统稳定,也就是最好选出来的master还是原来的机器,那么就可以避免发现master更换后,各个salve因为要同步数据等导致的zk数据网络风暴。所以在WorkServer中,54-63行,我们抢主的时候,如果之前主机是本机,则立即抢主,否则延迟5s抢主。这样就给原来主机预留出一定时间让其在新一轮选主中占据优势,从而利于环境稳定。
测试代码:
View Code
两次测试,本地模拟10台server,分别不启用防止网络抖动跟启动防抖动两次测试结果如下:
未启动防抖动:
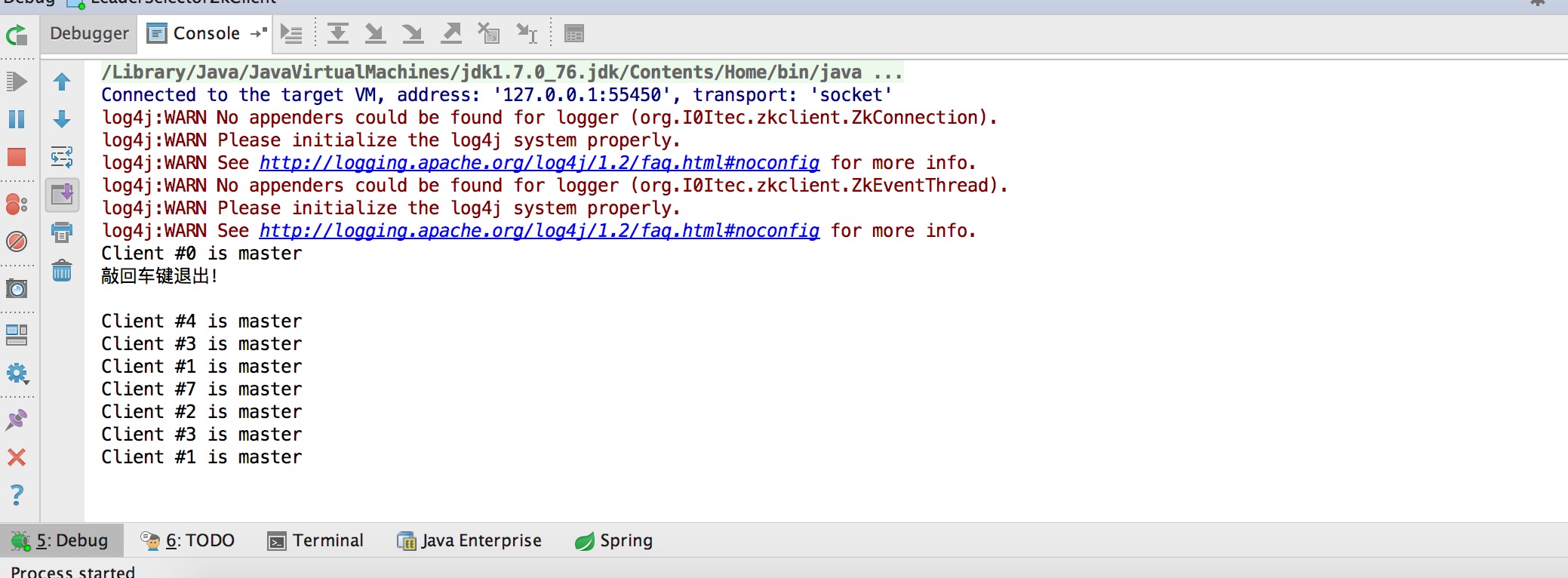
启用防抖动:
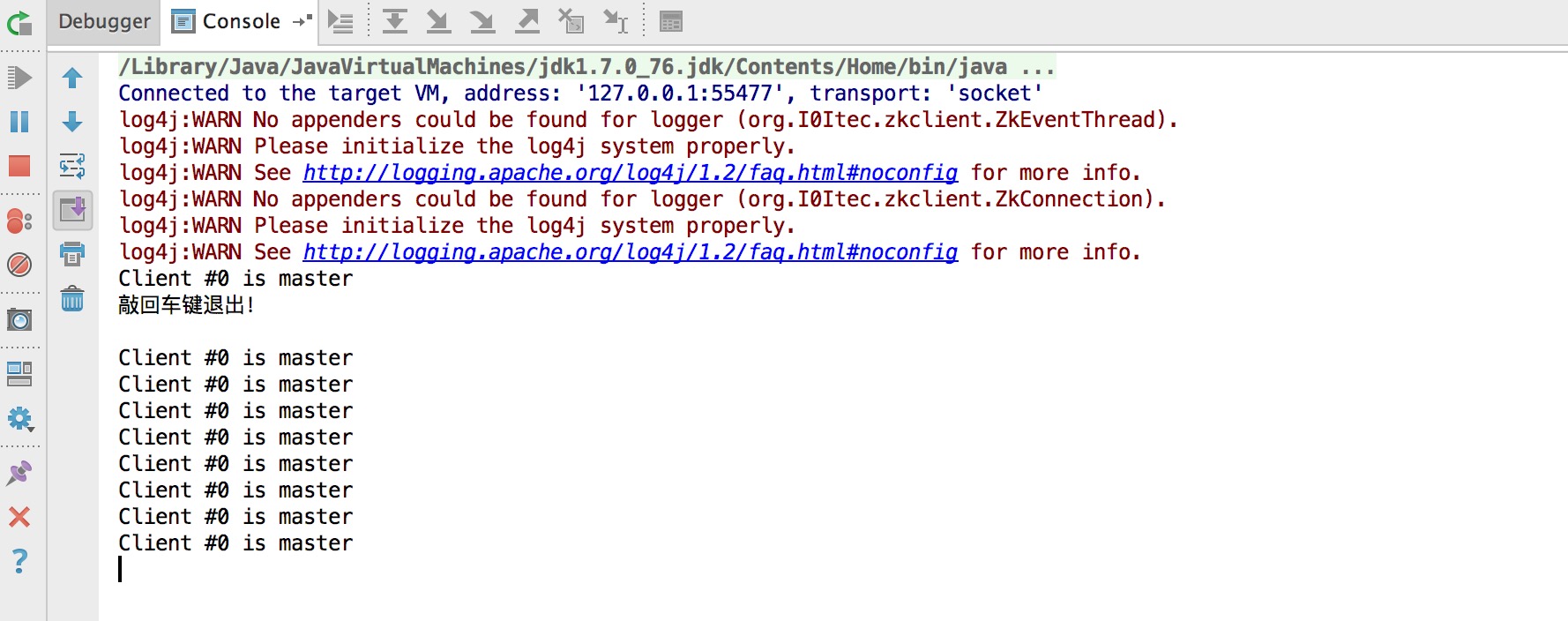
可以看到,未启用的时候,断线后重新选出的主机是随机的,没规律;启用防抖动后,每次选出的master都是id为0的机器。
-----------------------------------------------------------------------------------------------------------------------------
至此,我们已经通过编码实现了简单的master选举。但是,不知你有没有发现,,,,这个选主过程的代码还真是麻烦啊!
我们只是做一个demo,其中并未考虑复杂的业务场景,但其中的 监听,异常 等代码的处理还是让我觉得有些头大,怎么办?Curator应运而生!
为了熟悉Apache Curator,接下来,将用curator来实现master选举的demo。