词性标注(Part-of-Speech Tagging, POS)、命名实体识别(Name Entity Recognition,NER)和依存句法分析(Dependency Parsing)是自然语言处理中常用的基本任务,本文基于SpaCy python库,通过一个具体的代码实践任务,详细解释这三种NLP任务具体是什么,以及在实践中三个任务相互之间的关系。
介绍
说到数据科学时,我们经常想到的是数字的统计分析。但是,越来越多的情况下,社区会生成大量可以量化和分析的非结构化文本数据。比如,社交网络评论、产品评论、电子邮件、面试记录。
为了分析文本,数据科学家经常使用自然语言处理( NLP )技术。在这篇博客文章中,我们将讲解3个常见的NLP任务,看看它们如何一起用于分析文本。我们将讨论的三项任务是:
1、词性标注——这是什么类型的词?
2、依存句法分析——这个词和这个句子中的其他词有什么关系?
3、命名实体识别——这个词是专有名词吗?
我们将基于spaCy python库,将三种NLP任务综合放在一起,分析它们是如何协同工作的。在这儿,我们将使用这些结构化的数据进行一些有趣的可视化。
这种方法可以应用于任何问题,在这些问题拥有大量的文本数据,我们需要了解主要实体是谁,它们出现在文档中的位置,以及它们在做什么。例如,DocumentCloud在其“View Entities”分析选项中使用了与此类似的方法。
Token(符号)&词性标注
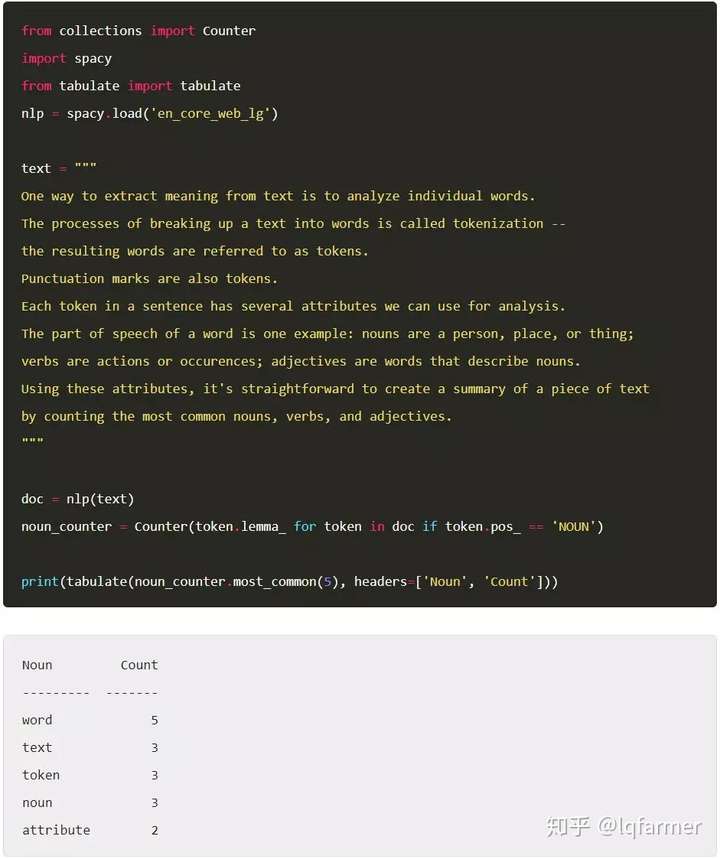
从文本中提取含义(meaning)的一种方法是分析单个单词。将文本分解成单词的过程称为tokenization——产生的单词称为token(tokens)。标点符号也是tokens。句子中的每一个token都有几个我们可以用来分析的属性。比如说一个词的词性:人、地方或事物是名词;动作或事件是动词;描述名词的词是形容词。使用这些属性,通过通过简单的计算最常见的名词、动词和形容词来创建一段文本的摘要。
使用spaCy,我们可以tokenize一段文本,并访问每个token(token)的词性属性。作为一个示例应用程序,一下代码给出了一个实例,我们先对一段话进行标签化,然后计算其中最常见的名词。我们还将对这些token进行归类,定义一个词为根节点,方便我们对其他的词进行标准化。
依存句法分析
单词之间也是有关系的,有几种类型的关系。例如,名词可以成为句子的主语,表示它执行了一个动作(一个动词),如“吉尔笑了”。名词也可以是句子的宾语,表示被句子的主语所作用,就像这句话中的约翰一样:”吉尔嘲笑约翰。"
依存句法分析是理解句子中单词之间关系的一种方法。虽然吉尔和约翰都是句子“吉尔嘲笑约翰”中的名词,但吉尔是笑的主体,约翰是被嘲笑的对象。依存关系是一种更细粒度的属性,可以通过句子中的关系来理解单词的含义。
这些词之间的关系会变得复杂,这取决于句子的结构。依存句法分析的结果是以动词为根的树形数据结构。
让我们来看一下“The quick brown fox jumps over the lazy dog” 的依存关系分析。

依存关系也是token属性,spaCy有一个很好的API,可以访问不同的token属性。下面我们将打印出每个token的文本、其依存关系以及其parent(头)token的文本。
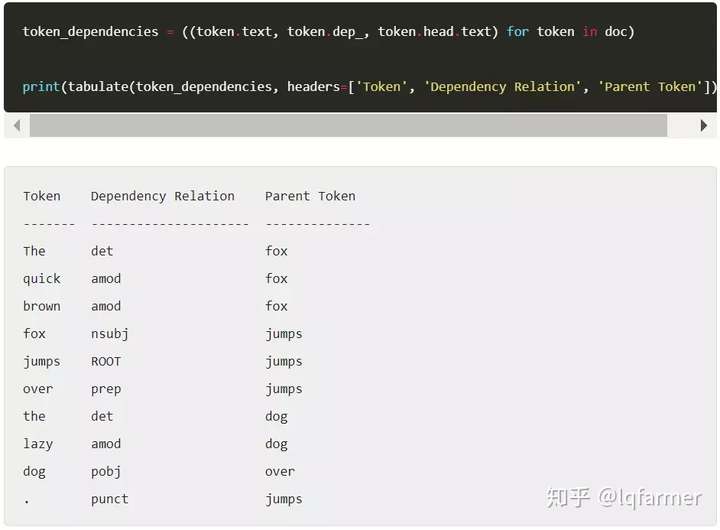
出于分析的目的,我们关心任何具有nobj关系的token,表明它们是句子中的对象。在例句中,这意味着我们想要捕捉“狐狸”这个词。
命名实体识别
最后是命名实体识别。命名实体是句子的专有名词。计算机已经非常擅长于判断在句子中是否存在实体,以及区分它们是什么类型的实体。
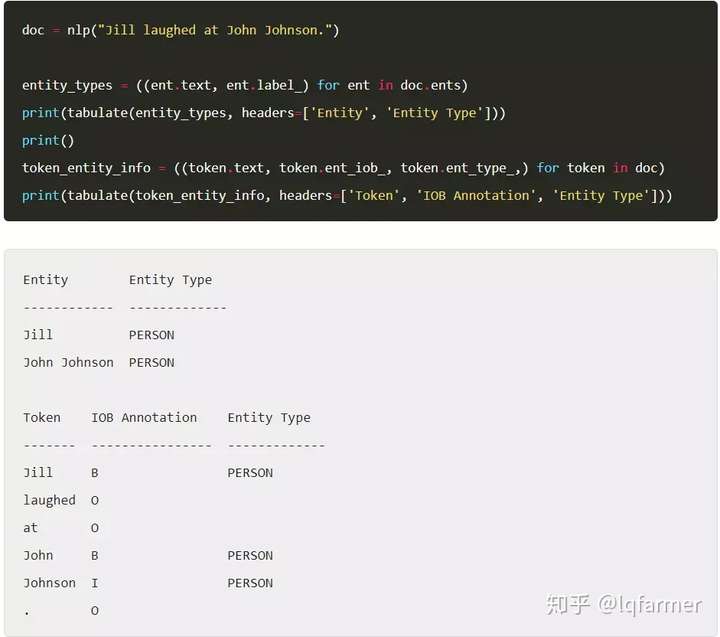
spaCy可以处理document level的命名实体识别,因为一个实体的名称可以跨越多个token。使用IOB方案将分别表示单个token实体的一部分,分别表示token实体的开始、内部和外部。
在下面的代码中,我们将打印初文档中所有命名实体。然后,我们将打印每个token、其IOB注释、其实体类型(如果它是实体的一部分)。我们将使用的例句是“Jill laughed at John Johnson."
实例解析:NLPing圣经
上面提到的每种方法本身都很棒,但是当我们将这些方法结合起来提取遵循语言模式的信息时,自然语言处理的真正力量就显示出来了。我们可以使用词性标注、依存句法分析和命名实体识别来理解大量文本中的所有参与者(actors)及其行为(actions)。圣经是一个很好的例子,因为它很长且具有丰富的角色。
如下图所示,我们正在导入的数据包含每个圣经章节一个对象。经文被用作圣经部分的参考资料,通常包含一句或多句经文。我们将仔细阅读每一节,提取主题,确定它是否是一个人,并抽出这个人所做的动作。
首先,让我们将圣经以JSON格式从GitHub存储库中载入。然后,我们将抽出每一节中的文本,通过spaCy进行依存解析和tagging,并将结果存入文档。
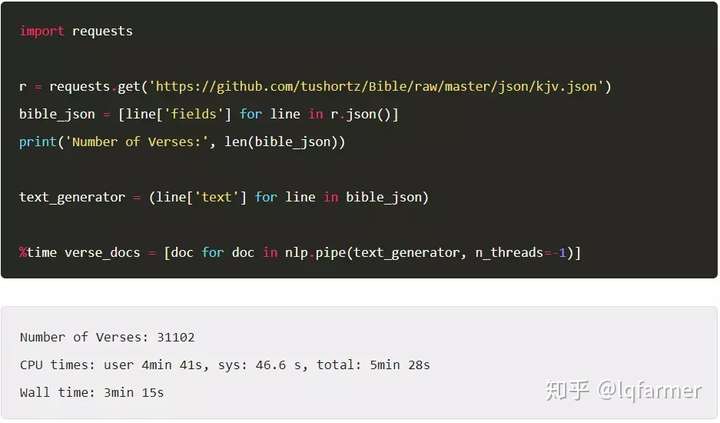
我们用3分钟左右的时间将JSON中的文本解析成verse_docs,大约每秒160节。作为参考,以下是bible_JSON的前3行:
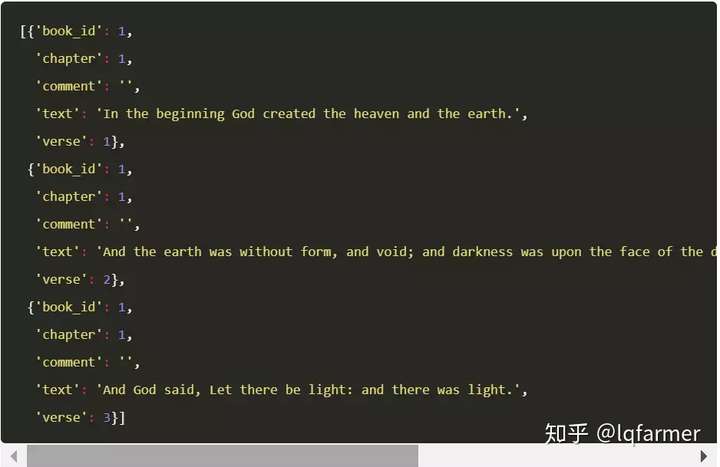
使用token属性
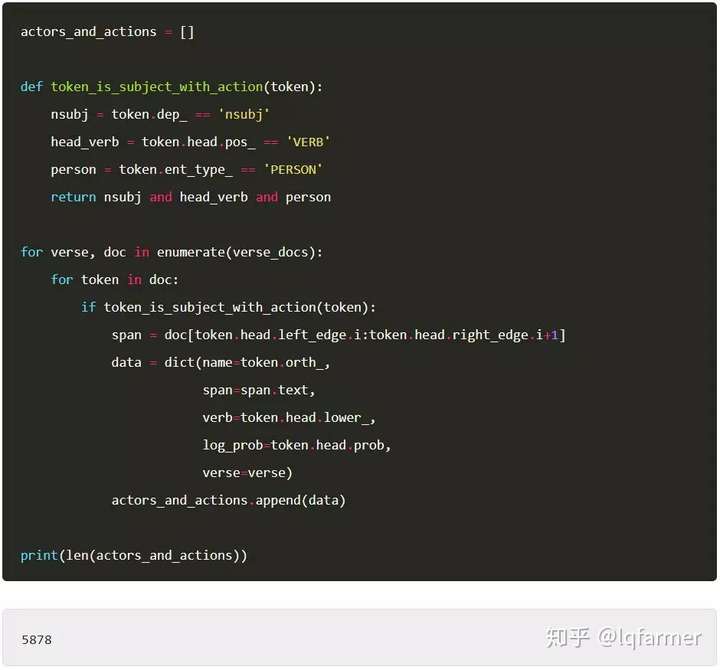
为了提取actors和actions,我们将迭代一首诗中的所有token,并考虑3个因素:
1. token是句子的主语吗(它是依存关系nsubj吗?) 。
2. 是一个动词token的parent吗?(这通常应该是真的,但是有时POS标记器和依存解析之间会有冲突,所以必须小心处理。另外,可能还存在其他一些奇怪的边缘案例(edge cases)。
3. token是一个人名实体吗?我们不想提取任何非人的名词。(为了简单起见,我们只提取名字)
如果我们的token满足上述三个条件,我们将收集以下属性:
1. 名词/实体token。
2. 从名词到动词之间的短语(span/phrase)。
3. 动词。
4. 标准英文文本中动词出现的概率(在这里使用使用这些记录是因为这些概率通常都很小)。
5. 诗号(verse number)。
分析
我们已经抽取出了一份包含所有actor及其actions的列表。为了加快分析,需要做两件事:
1、找出每个人最常见的action(动词)。
2、找出每个人最独特的action。它们往往是英语文本中出现概率最低的动词。
让我们看看按动词计数和最常见动词排列的top-15名actor。
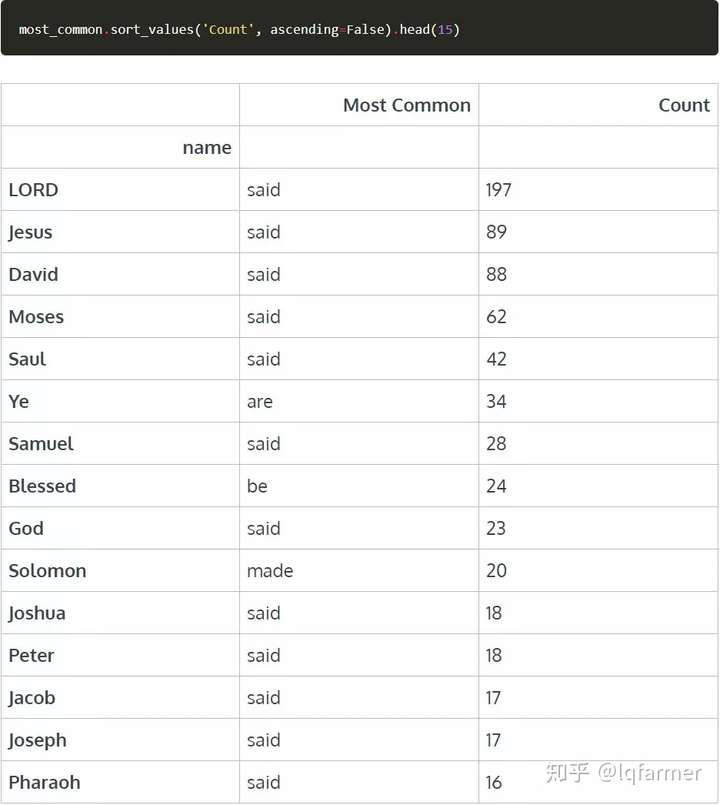
看起来圣经里的很多人都说过话,除了Solomon之外,他做了很多事情。
从动词出现的概率来看,最独特的动词是什么呢?(先删除重复词,这样每个词都是独一无二的)
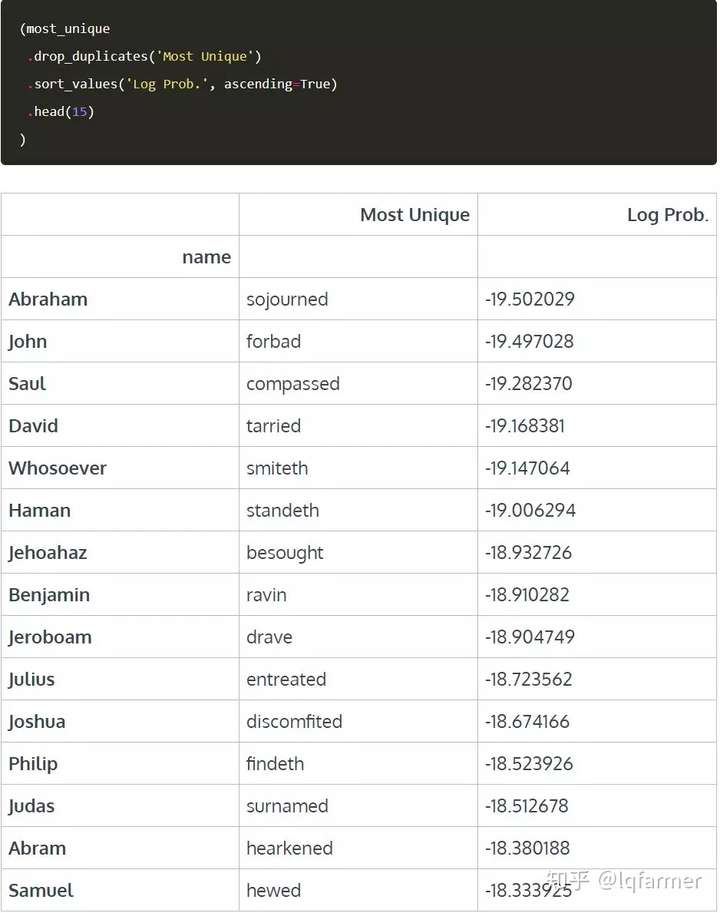
看来我们似乎有一些有趣的新单词要学!我最喜欢的是discomfited和ravin。
可视化
接下来让我们可视化我们的结果。选择行动最多的前50个名字,并在画出这些actions在整篇文章出现过的诗句。我们也将在圣经的每本书开始处画垂直线做标记。名字按首次出现的顺序排序。
我们可以看一下在圣经中的那些部分,这些人物最活跃。
我们将添加一些分隔符来区分圣经的不同章节。我本人不是圣经学者,所以我使用了如下分隔符:
旧约:
摩西五经,或法律书籍:Genesis, Exodus, Leviticus, Numbers, and Deuteronomy。
旧约历史书:oshua, Judges, Ruth, 1 Samuel, 2 Samuel, 1 Kings, 2 Kings, 1 Chronicles, 2 Chronicles, Ezra, Nehemiah, and Esther。
智慧文学:Job, Psalms, Proverbs, Ecclesiastes, and Song of Solomon。
先知: Isaiah, Jeremiah, Lamentations, Ezekiel, Daniel, Hosea, Joel, Amos, Obadiah, Jonah, Micah, Nahum, Habakkuk, Zephaniah, Haggai, Zechariah, 和Malachi。
新约:
福音书:马修、马克、卢克和约翰。
新约历史书:Acts
书信: Romans, 1 Corinthians, 2 Corinthians, Galatians, Ephesians, Philippians, Colossians, 1 Thessalonians, 2 Thessalonians, 1 Timothy, 2 Timothy, Titus, Philemon, Hebrews, James, 1 Peter, 2 Peter, 1 John, 2 John, 3 John, and Jude.。
预言/启示文学:启示
此外,我们将用红色的指示线将旧约和新约分开。
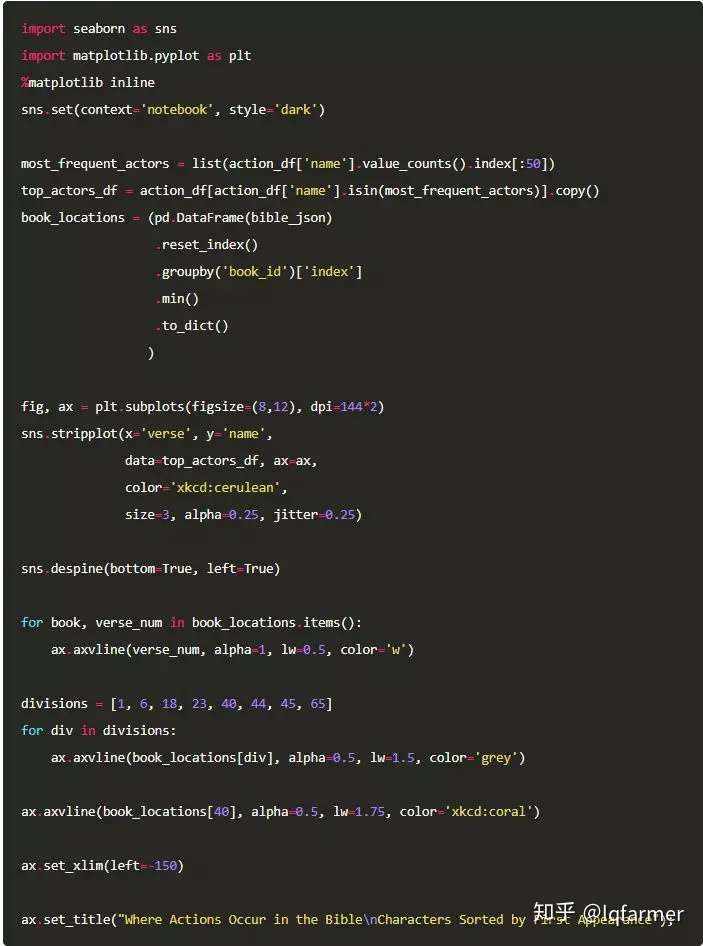
出现在圣经里面的Actions,按照它们第一次出现的位置排序。
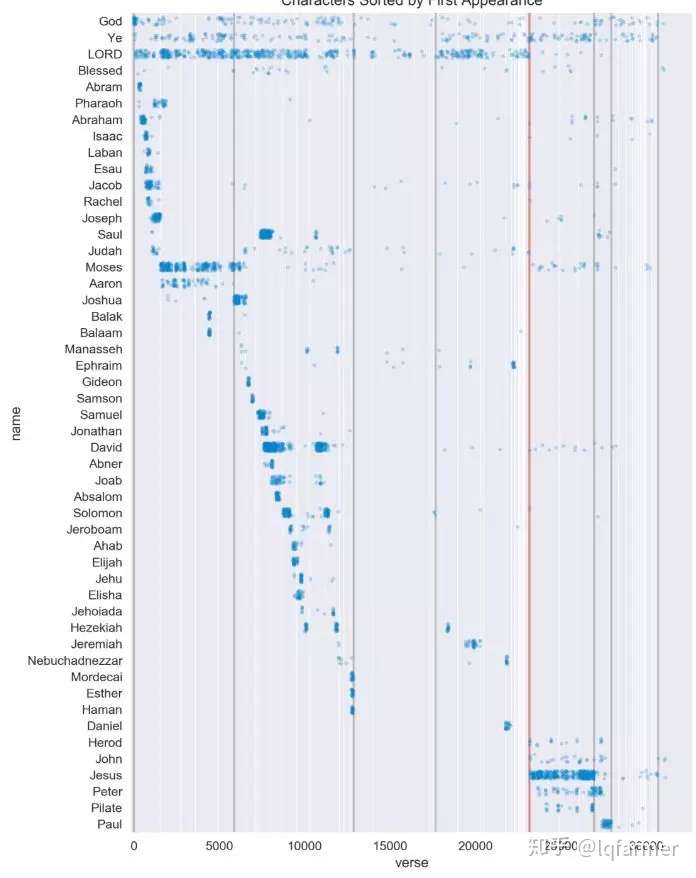
可视化分析
在圣经的开头,创世纪里,神被多次提到。
上帝不再被用作新约全书中的实体。
我们在使徒行传中第一次看到保罗。(福音书之后的第一本书)
圣经中的智慧和诗歌部分没有太多实体。
耶稣的一生在福音书中被详细记载。
彼拉多出现在每一部福音书的末尾。
这种方法的问题
实体识别无法区分同名的两个不同的人。比如:King Saul(旧约),Paul(使徒)被称为Saul,直到Acts书的中间部分。
有些名词不是实际的实体。
一些名词可以用更多的上下文和全名。(彼拉多)
下一步
一如既往,有一些方法可以扩展和改进这一分析。写这篇文章时,我想到了几个:
1 .使用依存关系查找实体之间的关系,并通过网络分析方法理解字符。
2. 改进实体提取方法以捕获单个名称以外的实体。
3. 对非个人实体及其语言关系进行分析——圣经中提到了哪些位置?
总结:
我们只需要使用文本中的token级属性就可以做一些有趣的分析。在这篇博客文章中,我们介绍了三个关键的NLP工具:
词性标注——这是什么类型的词?
依存句法分析——这个词和这个句子中的其他词有什么关系?
命名实体识别——这个词是专有名词吗?
我们一起运用这三种工具来发现圣经中的主要角色是谁,以及他们采取了什么行动。对这些actor和及他么的动作进行了可视化,以了解每个actor的主要action在哪里。