紧接上篇博客,上文已经介绍了前向-后向算法。前向-后向算法是通过递推地计算前向-后向概率来高效地进行隐马尔可夫模型的概率计算。该算法的时间复杂度是
五、学习算法
在很多实际的情况下,HMM 不能被直接地判断,这就变成了一个学习问题。因为对于给定的可观察状态序列
Baum-Welch算法首先对于HMM的参数进行一个初始的估计,但这个很可能是一个错误的猜测,然后通过对于给定的数据评估这些参数的的有效性(比如交叉验证)并减少它们所引起的错误来更新HMM参数,使得和给定的训练数据的误差变小。
实际上,Baum-Welch算法是EM算法的一个特例。EM算法是解决无监督学习问题的一把“利器”。下面我们就使用这把“利器”解决HMM的参数学习问题。
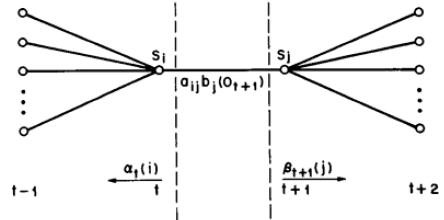
1.首先我们需要定义两个辅助变量,这两个变量可以用前文介绍过的前向概率和后向概率进行定义。
(1)给定模型
可以通过前向-后向概率计算,事实上
根据前向概率和后向概率的定义可知:
(2)给定模型
通过前向-后向概率计算得:
该变量在网格中所代表的关系如下:
(3)将
a.在观测
b.在观测
c.在观测
2.算法
Baum-Welch算法的推导过程实质上就是EM算法的过程,其中还会利用拉格朗日函数法求解极大化问题。具体的证明过程可查阅相关论文。下面直接给出算法:
输入:观测序列
输出:隐马尔科夫模型参数。
(1)初始化
对
(2)递推。对
这里的递推公式用到了1.(3)部分提及的期望值。
(3)结束。得到模型参数
3.代码实现
(1)依旧是相同的结构体(这里使用类并不是真的面向对象编程,当然封装完整的算法可以使用OOP范式)定义。
class HMM:
def __init__(self, pi, A, B):
self.pi = pi
self.A = A
self.B = B
self.M = B.shape[1]
self.N = A.shape[0](2)主算法函数
def baum_welch(hmm, obs):
T = len(obs)
M = hmm.M
N = hmm.N
alpha = zeros((N,T))
beta = zeros((N,T))
scale = zeros(T)
gamma = zeros((N,T))
xi = zeros((N,N,T-1))
# 计算初始化参数
logprobprev, alpha, scale = forward_with_scale(hmm, obs) # 计算前向概率
beta = backward_with_scale(hmm, obs, scale) # 计算后向概率
gamma = compute_gamma(hmm, alpha, beta) # 计算单个状态概率
xi = compute_xi(hmm, obs, alpha, beta) # 计算两个状态概率
logprobinit = logprobprev
# 开始迭代
while True:
# E-step
hmm.pi = 0.001 + 0.999*gamma[:,0] # 这里使用平滑化技巧,以免参数过于接近0
for i in range(N):
denominator = sum(gamma[i,0:T-1])
for j in range(N):
numerator = sum(xi[i,j,0:T-1])
hmm.A[i,j] = numerator / denominator
hmm.A = 0.001 + 0.999*hmm.A
for j in range(0,N):
denominator = sum(gamma[j,:])
for k in range(0,M):
numerator = 0.0
for t in range(0,T):
if observation.index(observed[t]) == k:
numerator += gamma[j,t]
hmm.B[j,k] = numerator / denominator
hmm.B = 0.001 + 0.999*hmm.B
# M-step
logprobcur, alpha, scale = forward_with_scale(hmm, obs)
beta = backward_with_scale(hmm, obs, scale)
gamma = compute_gamma(hmm, alpha, beta)
xi = compute_xi(hmm, obs, alpha, beta)
delta = logprobcur - logprobprev
logprobprev = logprobcur
if delta <= DELTA: # 迭代停止条件
break
logprobfinal = logprobcur
return hmm.A,hmm.B,hmm.pi(3)相关支持函数
主函数调用了均值平滑化的前向-后向概率计算算法:
def forward_with_scale(hmm, obs):
"""see scaling chapter in "A tutorial on hidden Markov models and
selected applications in speech recognition."
"""
T = len(obs)
N = hmm.N
alpha = zeros((N,T))
scale = zeros(T)
alpha[:,0] = hmm.pi[:] * hmm.B[:,observation.index(obs[0])]
scale[0] = sum(alpha[:,0])
alpha[:,0] /= scale[0]
for t in range(1,T):
for n in range(0,N):
alpha[n,t] = sum(alpha[:,t-1] * hmm.A[:,n]) * hmm.B[n,observation.index(obs[t])]
scale[t] = sum(alpha[:,t])
alpha[:,t] /= scale[t]
logprob = sum(log(scale[:]))
return logprob, alpha, scale
def backward_with_scale(hmm, obs, scale):
T = len(obs)
N = hmm.N
beta = zeros((N,T))
beta[:,T-1] = 1 / scale[T-1]
for t in reversed(range(0,T-1)):
for n in range(0,N):
beta[n,t] = sum(hmm.B[:,observation.index(obs[t+1])] * hmm.A[n,:] * beta[:,t+1])
beta[n,t] /= scale[t]
return beta计算
def compute_gamma(hmm, alpha, beta):
gamma = zeros(alpha.shape)
gamma = alpha[:,:] * beta[:,:]
gamma = gamma / sum(gamma,0)
return gamma
def compute_xi(hmm, obs, alpha, beta):
T = len(obs)
N = hmm.N
xi = zeros((N, N, T-1))
for t in range(0,T-1):
for i in range(0,N):
for j in range(0,N):
xi[i,j,t] = alpha[i,t] * hmm.A[i,j] * hmm.B[j,observation.index(obs[t+1])] * beta[j,t+1]
xi[:,:,t] /= sum(sum(xi[:,:,t],1),0)
return xi (4)测试程序
这里随机初始化参数,我们依然使用上篇博文的测试用例:
if __name__ == "__main__":
A = random.random([3,3])
B = random.random([3,2])
pi = random.random(3)
hmm = HMM(pi, A, B)
observed = ['red', 'write', 'red']
A,B,pi = baum_welch(hmm, observed)
print('state transition probability matrix A:\n', A)
print('observation probability matrix B:\n', B)
print('initial state probability vector pi:\n', pi)测试结果如下:

由于此算法是无监督学习算法,在实际项目使用中应该不断使用交叉验证方法使得模型验证误差最小。由于这里缺乏充足数据,所以就不演示此过程了。
六、预测算法
这个问题比较有趣。在很多情况下,我们对隐藏状态更有兴趣,因为其中包含了一些不能被直接观察到的有价值的信息。比如说在海藻和天气的例子中,一个隐居的人只能看到海藻的状态,但是他想知道天气的状态。这时候我们就可以使用Viterbi算法来根据可观察序列预测最优可能的隐藏状态的序列,当然前提是已知一个HMM模型。
Viterbi算法实际上是用动态规划求解预测问题,即求解概率最大路径(最优路径),实际上任何一个HMM模型都可以用图(graph)表示。
根据动态规划原理,我们需要提取一个最优子结构:如果最优路径在时刻
1.首先定义两个变量:
(1)定义在时刻
由定义可得变量
(2)定义在时刻
下面给出算法步骤:
输入:模型参数
输出:最优路径
(1)初始化
(2)递推。对
(3)终止
(4)最优路径回溯。对
最后得到最优路径即最优隐藏状态序列
2.代码实现
from numpy import *
observation = ['red','write']
class HMM:
def __init__(self, pi, A, B):
self.pi = pi
self.A = A
self.B = B
self.M = B.shape[1]
self.N = A.shape[0]
def viterbi(hmm, obs):
T = len(obs)
N = hmm.N
psi = zeros((N,T)) # reverse pointer
delta = zeros((N,T))
q = zeros(T)
temp = zeros(N)
delta[:,0] = hmm.pi[:] * hmm.B[:,observation.index(obs[0])] # 初始化
# 动态规划过程
for t in range(1,T):
for n in range(0,N):
temp = delta[:,t-1] * hmm.A[:,n]
max_ind = argmax(temp)
psi[n,t] = max_ind
delta[n,t] = hmm.B[n,observation.index(obs[t])] * temp[max_ind]
# 最优路径回溯
max_ind = argmax(delta[:,T-1])
q[T-1] = max_ind
prob = delta[:,T-1][max_ind]
for t in reversed(range(0,T-1)):
q[t] = psi[int(q[t+1]),t+1]
return prob, q, delta
测试程序如下:
if __name__ == "__main__":
A = array([[0.5,0.2,0.3],
[0.3,0.5,0.2],
[0.2,0.3,0.5]])
B = array([[0.5,0.5],
[0.4,0.6],
[0.7,0.3]])
pi = array([0.2,0.4,0.4])
hmm = HMM(pi, A, B)
observed = ['red', 'write', 'red']
prob, q, delta = viterbi(hmm, observed)
print('The maximum probability of every single path is:\n', delta)
print('The probability of optimal path is %f.' % prob)
print('The optimal sequence of state is:\n', q)测试结果如下:

结果可用概率图表示如下:
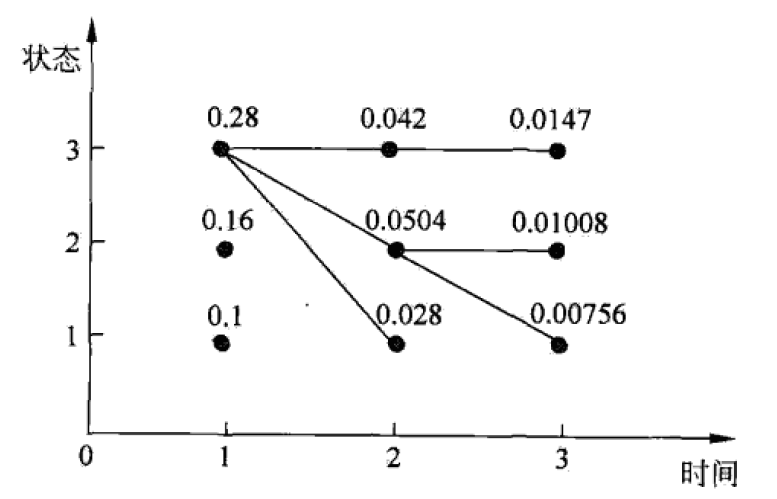
可见最优隐藏状态序列应为
七、参考论文
1.Lawrence R. Rabiner, A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the IEEE, 77 (2), p. 257–286, February 1989(下载链接:http://download.csdn.net/detail/herosofearth/9605209)
