版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_21727627/article/details/79063355
其他方法很简单,最核心的方法是trimToSize():
init(...):
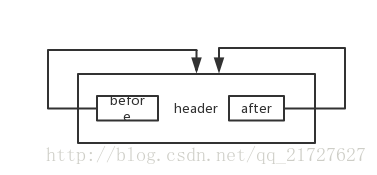
put(...)因为使用的是HashMap 发现最后一个一行addEntry(...)而且LinkedHashMap也实现了这个方法:
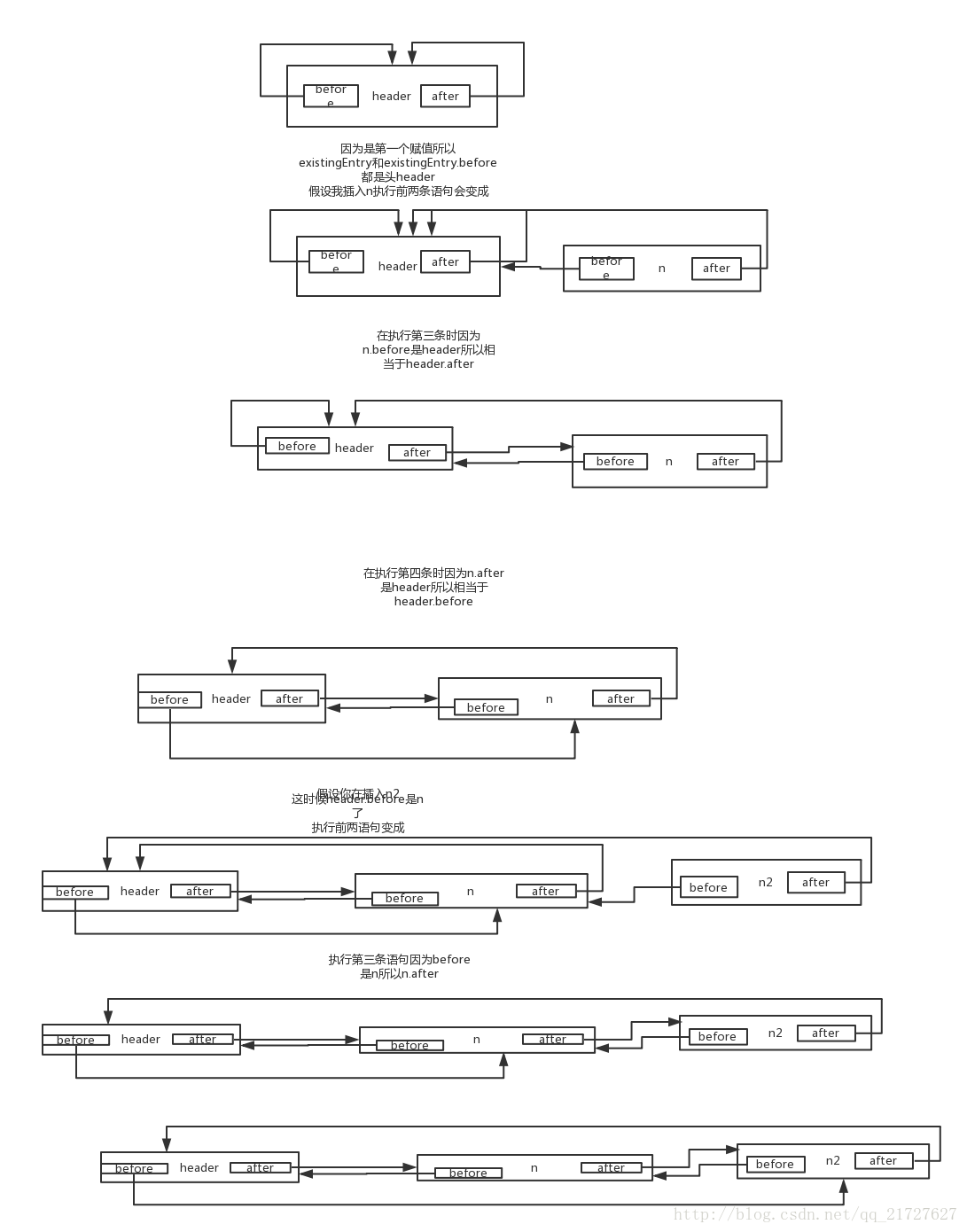
已经晕哭在厕所了...........
eldest():
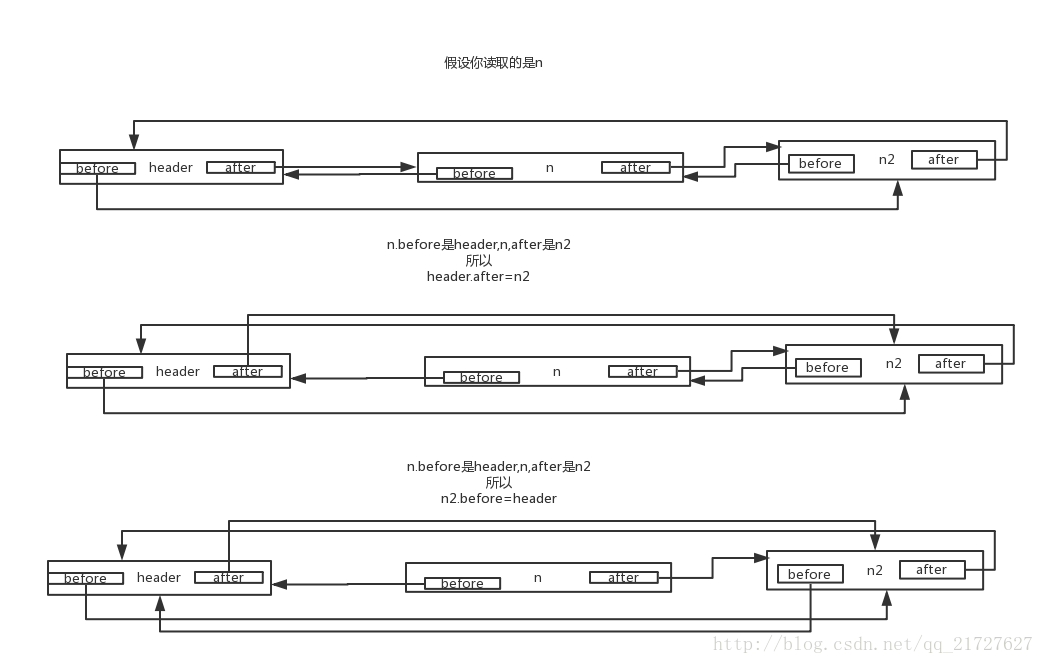 addBefore(...):
addBefore(...):

就这样吧,最少使用的header.after,最新使用的是header.before 尾部.
ps 源码是sdk25版本的,
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
//参数异常
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize) { //不需要删除最近最少使用的一个
break;
}
//使用空间已经超过你定义最大的值,删除最少使用的一个
Map.Entry<K, V> toEvict = map.eldest();
if (toEvict == null) { //这里为空 只有一个header头节点
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value); //调整使用的大小
evictionCount++;
}
entryRemoved(true, key, value, null); //默认空实现
}
}init(...):
@Override
void init() {
header = new LinkedHashMapEntry<>(-1, null, null, null);
header.before = header.after = header;
}put(...)因为使用的是HashMap 发现最后一个一行addEntry(...)而且LinkedHashMap也实现了这个方法:
/**
* This override alters behavior of superclass put method. It causes newly
* allocated entry to get inserted at the end of the linked list and
* removes the eldest entry if appropriate.
*/
//看注释就知道他是重写父类的,作用是:将新entry 插入双向链表中,和是否删除最少的一个也就是header.after指向的entry
void addEntry(int hash, K key, V value, int bucketIndex) {
// Previous Android releases called removeEldestEntry() before actually
// inserting a value but after increasing the size.
// The RI is documented to call it afterwards.
// **** THIS CHANGE WILL BE REVERTED IN A FUTURE ANDROID RELEASE ****
// Remove eldest entry if instructed
LinkedHashMapEntry<K,V> eldest = header.after;//最少使用的一个
if (eldest != header) { //不是只有头节点时
boolean removeEldest;
size++;
try {
removeEldest = removeEldestEntry(eldest); //默认是false
} finally {
size--;
}
if (removeEldest) {
removeEntryForKey(eldest.key); //默认不执行
}
}
super.addEntry(hash, key, value, bucketIndex); //在这里会调用createEntry(.....)
} /**
* This override differs from addEntry in that it doesn't resize the
* table or remove the eldest entry.
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMapEntry<K,V> old = table[bucketIndex];
LinkedHashMapEntry<K,V> e = new LinkedHashMapEntry<>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
} private void addBefore(LinkedHashMapEntry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}已经晕哭在厕所了...........
eldest():
public Map.Entry<K, V> eldest() {
Entry<K, V> eldest = header.after; //就是取离头最近的一个 例如 n
return eldest != header ? eldest : null; //只剩下头节点返回null
} void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) { //要想使用算法Lru能够用必须设置为true
lm.modCount++;
remove(); //用图
addBefore(lm.header);//用图
}
} /**
* Removes this entry from the linked list.
*/
private void remove() {
before.after = after;
after.before = before;
} /**
* Inserts this entry before the specified existing entry in the list.
*/
private void addBefore(LinkedHashMapEntry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}就这样吧,最少使用的header.after,最新使用的是header.before 尾部.
ps 源码是sdk25版本的,