一:php部分
1.用php打印前一天的时间,格式是2018-01-01 08:00:00?
答:$a=date("Y-m-d H:i:s",strtotime("-1 day"));print_r($a)
2.echo、print_r、print、var_dump、的区别?
答:echo、print是php语句,var_dump和print_r是函数
echo输出一个或多个字符串,中间以逗号隔开,没有返回值是语言结构而不是真正的函数,因此不能作为表达式的一部分使用
print也是php的一个关键字,有返回值 只能打印出简单类型变量的值(如int,string),如果字符串显示成功则返回true,
否则返回false
print_r 可以打印出复杂类型变量的值(如数组、对象)以列表的形式显示,并以array、object开头,但print_r输出布尔
值和NULL的结果没有意义,因为都是打印"\n",因此var_dump()函数更适合调试
var_dump() 判断一个变量的类型和长度,并输出变量的数值
3.include和require的区别是什么?
答:
require是无条件包含,也就是如果一个流程里加入require,无论条件成立与否都会先执行require,当文件不存在或者无法打开的时候,会提示错误,并且会终止程序执行
include有返回值,而require没有(可能因为如此require的速度比include快),如果被包含的文件不存在的化,那么会提示一个错误,但是程序会继续执行下去
注意:包含文件不存在或者语法错误的时候require是致命的,而include不是
require_once表示了只包含一次,避免了重复包含
4.请说说php中传值与传引用的区别,并说明传值什么时候传引用?
答:
变量默认总是传值赋值,那也就是说,当将一个表达式的值赋予一个变量时,整个表达式的值被赋值到目标变量,这意味着:当一个变量的赋予另外一个变量时,改变其中一个变量的值,将不会影响到另外一个变量
php也提供了另外一种方式给变量赋值:引用赋值。这意味着新的变量简单的__引用__(换言之,成为了其别名或者指向)了原始变量。改动的新的变量将影响到原始变量,反之亦然。使用引用赋值,简单地将一个&符号加到将要赋值的变量前(源变量)
对象默认是传引用
对于较大是的数据,传引用比较好,这样可以节省内存的开销
5.session和cookie有哪些区别?请从协议,产生原因与作用说明?
答:
1、http无状态协议,不能区分用户是否是从同一个网站上来的,同一个用户请求不同的页面不能看做是同一个用户。
2、SESSION存储在服务器端,COOKIE保存在客户端。Session比较安全,cookie用某些手段可以修改,不安全。Session依赖于cookie进行传递。
禁用cookie后,session不能正常使用。Session的缺点:保存在服务器端,每次读取都从服务器进行读取,对服务器有资源消耗。Session保存在服务器端的文件或数据库中,默认保存在文件中,文件路径由php配置文件的session.save_path指定。Session文件是公有的。
6.WEB开发中数据提交方式有几种?有什么区别?百度使用哪种方式?
Get与post两种方式
区别:
1. Get从服务器获取数据,post向服务器传送数据
2. Get传值在url中可见,post在url中不可见
3. Get传值一般在2KB以内,post传值大小可以在php.ini中进行设置
4. get安全性非低,post安全性较高,执行效率却比Post高
建议:
1、get式安全性较Post式要差些包含机密信息建议用Post数据提交式;
2、做数据查询建议用Get式;做数据添加、修改或删除建议用Post方式;
百度使用的get方式,因为可以从它的URL中看出
7、安全对一套程序来说至关重要,请说说在开发中应该注意哪些安全机制?
①防远程提交;②防SQL注入,对特殊代码进行过滤;③防止注册机灌水,使用验证码;
8、在程序的开发中,如何提高程序的运行效率?
①优化SQL语句,查询语句中尽量不使用select *,用哪个字段查哪个字段;少用子查询可用表连接代替;少用模糊查询;②数据表中创建索引;③对程序中经常用到的数据生成缓存;
9、现在编程中经常采取MVC三层结构,请问MVC分别指哪三层,有什么优点?
MVC三层分别指:业务模型、视图、控制器,由控制器层调用模型处理数据,然后将数据映射到视图层进行显示,优点是:①可以实现代码的重用性,避免产生代码冗余;②M和V的实现代码分离,从而使同一个程序可以使用不同的表现形式
10、PHP处理数组的常用函数?(重点看函数的‘参数’和‘返回值’)
①array()创建数组;②count()返回数组中元素的数目;③array_push()将一个或多个元素插入数组的末尾(入栈);④array_column()返回输入数组中某个单一列的值;⑤array_combine()通过合并两个数组来创建一个新数组;⑥array_reverse()以相反的顺序返回数组;⑦array_unique()删除数组中的重复值;⑧in_array()检查数组中是否存在指定的值;
11、PHP处理字符串的常用函数?(重点看函数的‘参数’和‘返回值’)
①trim()移除字符串两侧的空白字符和其他字符;
②substr_replace()把字符串的一部分替换为另一个字符串;
③substr_count()计算子串在字符串中出现的次数;
④substr()返回字符串的一部分;
⑤strtolower()把字符串转换为小写字母;
⑥strtoupper()把字符串转换为大写字母;
⑦strtr()转换字符串中特定的字符;
⑧strrchr()查找字符串在另一个字符串中最后一次出现;
⑨strstr()查找字符串在另一字符串中的第一次出现(对大小写敏感);strrev()反转字符串;strlen()返回字符串的长度;str_replace()替换字符串中的一些字符(对大小写敏感);print()输出一个或多个字符串;explode()把字符串打散为数组;is_string()检测变量是否是字符串;strip_tags()从一个字符串中去除HTML标签;mb_substr()用来截中文与英文的函数
12、PHP处理时间的常用函数?(重点看函数的‘参数’和‘返回值’)
date_default_timezone_get()返回默认时区。
date_default_timezone_set()设置默认时区。
date()格式化本地时间/日期。
getdate()返回日期/时间信息。
gettimeofday()返回当前时间信息。
microtime()返回当前时间的微秒数。
mktime()返回一个日期的 Unix时间戳。
strtotime()将任何英文文本的日期或时间描述解析为 Unix时间戳。
time()返回当前时间的 Unix时间戳。
13、PHP操作目录(文件夹)的常用函数?(重点看函数的‘参数’和‘返回值’)
①打开目录;②删除目录;③读取目录;④创建目录;⑤修改目录;⑥关闭目录等等,此项非常重要,在工作中经常用来创建或者删除上传文件的目录,创建或者删除缓存、静态页面的目录,请参照php手册,认真查看
14、什么是面向对象?(理解着回答)
答:面向对象OO = 面向对象的分析OOA + 面向对象的设计OOD + 面向对象的编程OOP;通俗的解释就是“万物皆对象”,把所有的事物都看作一个个可以独立的对象(单元),它们可以自己完成自己的功能,而不是像C那样分成一个个函数。
现在纯正的OO语言主要是Java和C#,PHP、C++也支持OO,C是面向过程的。
15、简述 private、 protected、 public修饰符的访问权限。
答:private : 私有成员, 在类的内部才可以访问。
protected : 保护成员,该类内部和继承类中可以访问。
public : 公共成员,完全公开,没有访问限制。
16、堆和栈的区别?
答:栈是编译期间就分配好的内存空间,因此你的代码中必须就栈的大小有明确的定义;
堆是程序运行期间动态分配的内存空间,你可以根据程序的运行情况确定要分配的堆内存的大小。
17、XML 与 HTML 的主要区别
答:(1) XML是区分大小写字母的,HTML不区分。
(2) 在HTML中,如果上下文清楚地显示出段落或者列表键在何处结尾,那么你可以省略
或者
之类的结束 标记。在XML中,绝对不能省略掉结束标记。
(3) 在XML中,拥有单个标记而没有匹配的结束标记的元素必须用一个 / 字符作为结尾。这样分析器就知道不用 查找结束标记了。
(4) 在XML中,属性值必须分装在引号中。在HTML中,引号是可用可不用的。
(5) 在HTML中,可以拥有不带值的属性名。在XML中,所有的属性都必须带有相应的值。
18、面向对象的特征有哪些方面?
答:主要有封装,继承,多态。如果是4个方面则加上:抽象。
下面的解释为理解:
封装:
封装是保证软件部件具有优良的模块性的基础,封装的目标就是要实现软件部件的高内聚,低耦合,防止程序相互依赖性而带来的变动影响.
继承:
在定义和实现一个类的时候,可以在一个已经存在的类的基础之上来进行,把这个已经存在的类所定义的内容作为自己的内容,并可以加入若干新的内容,或修改原来的方法使之更适合特殊的需要,这就是继承。继承是子类自动共享父类数据和方法的机制,这是类之间的一种关系,提高了软件的可重用性和可扩展性。
多态:
多态是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
抽象:
抽象就是找出一些事物的相似和共性之处,然后将这些事物归为一个类,这个类只考虑这些事物的相似和共性之处,并且会忽略与当前主题和目标无关的那些方面,将注意力集中在与当前目标有关的方面。例如,看到一只蚂蚁和大象,你能够想象出它们的相同之处,那就是抽象。
19、抽象类和接口的概念以及区别?
答:抽象类:它是一种特殊的,不能被实例化的类,只能作为其他类的父类使用。使用abstract关键字声明。
它是一种特殊的抽象类,也是一个特殊的类,使用interface声明。
(1)抽象类的操作通过继承关键字extends实现,而接口的使用是通过implements关键字来实现。
(2)抽象类中有数据成员,可以实现数据的封装,但是接口没有数据成员。
(3)抽象类中可以有构造方法,但是接口没有构造方法。
(4)抽象类的方法可以通过private、protected、public关键字修饰(抽象方法不能是private),而接口中的方法只能使用public关键字修饰。
(5)一个类只能继承于一个抽象类,而一个类可以同时实现多个接口。
(6)抽象类中可以有成员方法的实现代码,而接口中不可以有成员方法的实现代码。
20、什么是构造函数,什么是析构函数,作用是什么?
答:构造函数(方法)是对象创建完成后第一个被对象自动调用的方法。它存在于每个声明的类中,是一个特殊的成员方法。作用是执行一些初始化的任务。Php中使用__construct()声明构造方法,并且只能声明一个。
析构函数(方法)作用和构造方法正好相反,是对象被销毁之前最后一个被对象自动调用的方法。是PHP5中新添加的内容作用是用于实现在销毁一个对象之前执行一些特定的操作,诸如关闭文件和释放内存等。
21、如何重载父类的方法,举例说明
答:重载,即覆盖父类的方法,也就是使用子类中的方法替换从父类中继承的方法,也叫方法的重写。
覆盖父类方法的关键是在子类中创建于父类中相同的方法包括方法的名称、参数和返回值类型。PHP中只要求方法的名称相同即可。
22、常用的魔术方法有哪些?举例说明
答:php规定以两个下划线(__)开头的方法都保留为魔术方法,所以建议大家函数名最好不用__开头,除非是为了重载已有的魔术方法。
__construct() 实例化类时自动调用。
__destruct() 类对象使用结束时自动调用。
__set() 在给未定义的属性赋值的时候调用。
__get() 调用未定义的属性时候调用。
__isset() 使用isset()或empty()函数时候会调用。
__unset() 使用unset()时候会调用。
__sleep() 使用serialize序列化时候调用。
__wakeup() 使用unserialize反序列化的时候调用。
__call() 调用一个不存在的方法的时候调用。
__callStatic()调用一个不存在的静态方法是调用。
__toString() 把对象转换成字符串的时候会调用。比如 echo。
__invoke() 当尝试把对象当方法调用时调用。
__set_state() 当使用var_export()函数时候调用。接受一个数组参数。
__clone() 当使用clone复制一个对象时候调用。
23、$this和self、parent这三个关键词分别代表什么?在哪些场合下使用?
答:$this 当前对象
self 当前类
parent 当前类的父类
$this在当前类中使用,使用->调用属性和方法。
self也在当前类中使用,不过需要使用::调用。
parent在类中使用。
24、类中如何定义常量、如何类中调用常量、如何在类外调用常量。
答:类中的常量也就是成员常量,常量就是不会改变的量,是一个恒值。
定义常量使用关键字const.
例如:const PI = 3.1415326;
无论是类内还是类外,常量的访问和变量是不一样的,常量不需要实例化对象,
访问常量的格式都是类名加作用域操作符号(双冒号)来调用。
即:类名 :: 类常量名;
25、作用域操作符::如何使用?都在哪些场合下使用?
答:调用类常量
调用静态方法
26、__autoload()方法的工作原理是什么?
答:使用这个魔术函数的基本条件是类文件的文件名要和类的名字保持一致。
当程序执行到实例化某个类的时候,如果在实例化前没有引入这个类文件,那么就自动执行__autoload()函数。
这个函数会根据实例化的类的名称来查找这个类文件的路径,当判断这个类文件路径下确实存在这个类文件后
就执行include或者require来载入该类,然后程序继续执行,如果这个路径下不存在该文件时就提示错误。
使用自动载入的魔术函数可以不必要写很多个include或者require函数。
26、http协议常用状态码解释?
众所周知,做web开发,常见的几种状态码是必须要了解的,而且几个状态码在面试中也有可能要考。

在这其中,200,304,403,404,500,是必须要知道的,且在爬虫工程师这个职位,这些所有状态码都是必须要知道的。
26、对于大流量网站,采取什么方式来解决访问量的问题?
首先确认服务器硬件是否能够支持当前的流量数据库读写分离,优化数据表
程序功能规则,禁止外部的盗链
控制大文件的下载
使用不同主机分流主要流量
26、使用至少三种方法获取一个文件的扩展名?
答:方法1:使用strrchr()函数
<?php
function getExt($file) {
return strrchr($file, '.');
}
echo getExt('index.php');
?>注:strrchr() 函数查找字符串在另一个字符串中最后一次出现的位置,并返回从该位置到字符串结尾的所有字符。如果成失败,否则返回 false。
方法2:截取字符串
<?php
function getExt($file) {
return substr($file, strrpos($file, '.'));
}
echo getExt('index.php');
?>注:strrpos() 函数查找字符串在另一个字符串中最后一次出现的位置。如果成失败,否则返回 false。
方法3:使用数组
<?php
function getExt($file) {
//PHP 5.4开始,会发出警告,因此使用@屏蔽
return @array_pop(explode('.', $file));
}
echo getExt('index.php');
?>方法4:使用pathinfo()函数
<?php
function getExt($file) {
$temp = pathinfo($file);
return $temp['extension'];
}
echo getExt('index.php');
?>方法五:
return strrev(substr(strrev($file_name), 0, strpos(strrev($file_name), ‘.’)));
}
27、有一个数组array('23','34','56','78','54','63')请使用冒泡排序算法和快速排序算法进行排序,请详细写出过程?
答:1. 冒泡排序法
* 思路分析:法如其名,就是像冒泡一样,每次从数组当中 冒一个最大的数出来。
* 比如:2,4,1 // 第一次 冒出的泡是4
* 2,1,4 // 第二次 冒出的泡是 2
* 1,2,4 // 最后就变成这样
代码:
$arr=array('23','34','56','78','54','63')
function getpao($arr)
{
$len=count($arr);
//设置一个空数组 用来接收冒出来的泡
//该层循环控制 需要冒泡的轮数
for($i=1;$i<$len;$i++)
{ //该层循环用来控制每轮 冒出一个数 需要比较的次数
for($k=0;$k<$len-$i;$k++)
{
if($arr[$k]>$arr[$k+1])
{
$tmp=$arr[$k+1];
$arr[$k+1]=$arr[$k];
$arr[$k]=$tmp;
}
}
}
return $arr;
}
/*
快速排序
*/
function quickSort($array)
{
if(!isset($array[1]))
return $array;
$mid = $array[0]; //获取一个用于分割的关键字,一般是首个元素
$leftArray = array();
$rightArray = array();
foreach($array as $v)
{
if($v > $mid)
$rightArray[] = $v; //把比$mid大的数放到一个数组里
if($v < $mid)
$leftArray[] = $v; //把比$mid小的数放到另一个数组里
}
$leftArray = quickSort($leftArray); //把比较小的数组再一次进行分割
$leftArray[] = $mid; //把分割的元素加到小的数组后面,不能忘了它哦
$rightArray = quickSort($rightArray); //把比较大的数组再一次进行分割
return array_merge($leftArray,$rightArray); //组合两个结果
}
28、常见php与mysql中文乱码问题解决办法?
答:乱码问题1:用PHPmyAdmin操作MySQL数据库汉字显示正常,但用PHP网页显示MySQL数据时所有汉字都变成了?号。
症状:用PHPmyAdmin输入汉字正常,但当PHP网页显示MySQL数据时汉字就变成了?号,并且有多少个汉字就有多少个?号。
原因:没有在PHP网页中用代码告诉MySQL该以什么字符集输出汉字。
解决方法:
1.网页文件head设置编码<meta http-equiv=”Content-Type” content=”text/html; charset=utf-8″ />
2.PHP页面在保存的时候使用utf-8编码保存,可以用记事本或convertz802转换文件
3.在MYSQL中新建数据库的时候数据库 选择UTF-8编码既字符集 设定为 utf-8_unicode_ci(Unicode (多语言), 不区分大小写),
库里面 表table的 整理 设置为 utf-8_general_ci
表里面的每个字段的 整理 都设置为 utf-8_general_ci
4.在PHP连接数据库的时候,也就是mysql_connect()之后加入
|
1
2
3
4
|
//设置数据的字符集utf-8
mysql_query(
"set names 'utf8' "
);
mysql_query(
"set character_set_client=utf8"
);
mysql_query(
"set character_set_results=utf8"
);
|
注意是utf8,不是utf-8 。
如果你的网页编码是gb2312,那就是 SET NAMES GB2312。但编辑员强烈推荐网页编码、MySQL数据表字符集、PHPmyAdmin都统一使用UTF-8。
以上四点即可实现全站utf-8编码,而且在数据库中也不会有中文乱码。
乱码问题2:用PHPmyAdmin输入数据时发生错误,不让输入或出现乱码
解决方法:这是设置问题。请安装最新版PHPmyAdmin或Appserv,打开PHPmyAdmin,MySQL 字符集: UTF-8 Unicode (utf8); MySQL 连接校对应该为utf8_unicode_ci;创建新的数据库时整理一栏请也选成utf8_unicode_ci。网页字符集也最好选用utf-8。utf-8是国际标准编码,是趋势。
乱码问题3: 在本机开发好的MySQL数据表,在本机测试一切正常,但用网站空间商提供的PHPmyAdmin上传时却出现问题,上传失败。尤其是使用国外PHP空间。
解决方法:首先查看网站空间商提供的PHPmyAdmin字符集设定,确定自己所建数据表与服务商的是同一编码。在国外MySQL是不支持gb2312的,甚至最新版的Apache也不支持gb2312。如果是因为编码不统一,可以重建数据表,当然是用国际标准的UTF8。
29、什么是反向代理?什么时候需要用反向代理,nginx和Apache分别如何配置?
反向代理反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。
需要提高性能得时候
好处能用一个端口跑多个应用:比如nginx做前台服务器,监听80端口,所有请求都首先经过nginx,,然后nginx将请求转发给node服务器 node服务器可以有多个,比如9000一个,9001一个,等等黄金搭档Nodejs + forever + node-http-proxy
也可以直接用node做前台服务器,而不用Nginx做服务器。
前台服务器一个最小化配置的node服务器出错的可能性小,然后其它node服务跑在其他端口
node前台服务器+多后台服务器,可以很方便的做负载均衡load-balacing,但是意义不大。node单线程的并发能力非常好。
其它如果你想利用现有成熟的服务器的一些设施,比如caching, statistics, balancing,需要注意,Apache是阻塞的,最好也选择一个非阻塞的服务器吧,nginx就是非常好的选择moreadvantages-of-a-reverse-proxy-in-front-of-node-js
Author: tom
以下就是nginx和Apache分别如何配置
如果是一台普通vps或者是独立服务器 ,,,首先我们要干的就是装环境和配置防火墙了..
首先我们配置下防火墙吧,
[[email protected] ~]# vim /etc/sysconfig/iptables
:wq! 保存退出
大家肯定会问 88 89 端口是干嘛的,,不用问了,等会看就知道了...
-A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 88 -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 21 -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 80 -j ACCEPT
还有一件事需要做的就是selinux
可能大家会觉得我啰嗦.....错...这些 我主要是对新手来讲的,,,, 如果你是老手你跳到最下面看的我配置文件就行...
[[email protected] ~]# vim /etc/sysconfig/selinux 打开selinux 配置文件
在里面把所有的都注释掉新增一个
SELINUX=disabled
:wq! 保存退出
重启 服务器[[email protected] ~]# reboot
等服务器重启完毕之后 我们就开始安装环境了.. 注意,,我给大家介绍的全部是yum 源安装 .喜欢编译的安装的自己 在编译安装之前需安装编译需要的依赖包以及 gcc 等等那些工具...在此我提醒大家.很多人 的服务器环境是最小化安装版, 最小化安装版是不适合 编译安装环境的..如果是的话请手动用 yum 安装所需要的编译环境.. 不说了 咱们开始
首先安装nginx吧 这种方法是教大家安装nginx 最新版本的..
[[email protected] ~]# vim /etc/yum.repos.d/CentOS-Base.repo
在最后一行加上如下内容
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=0
enabled=1
:wq! 保存退出
下面开始安装nginx了
[[email protected] ~]# yum install nginx
提示按 y
安装 mysql
[[email protected] ~]# yum install mysql-server
提示按 y
安装php
[[email protected] ~]# yum install php -y
提示按 y
安装php的扩展插件
[[email protected] ~]# yum install php-mysql php-gd libjpeg* php-ldap php-odbc php-pear php-xml php-xmlrpc php-mbstring php-mcrypt php-bcmath php-mhash libmcrypt libmcrypt-devel
好了.以上就是 lnmp 环境的完整 安装了.
接下来我们需要把 /etc/nginx/ 目录下面的nginx.conf 这个里面的内容全部修改
最好是先把默认的nginx.conf 这个配置文件备份下吧.
[[email protected] ~]#cd /etc/nginx
备份重新命名为 nginx.confbak
接下来新建立一个nginx.conf 配置文件
输入一下内容:
user nginx nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
server_tokens off;
server_names_hash_bucket_size 128;
client_header_buffer_size 32k;
large_client_header_buffers 4 32k;
client_max_body_size 50m;
sendfile on;
tcp_nopush on;
keepalive_timeout 60;
tcp_nodelay on;
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 256k;
gzip on;
gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_http_version 1.0;
gzip_comp_level 2;
gzip_types text/plain application/x-javascript text/css application/xml;
gzip_vary on;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
server
{
listen 80;
server_name www.51buyhost.com 51buyhost.com;
index index.html index.htm index.php;
root /data/51buyhost;
location / {
try_files $uri @apache;
}
location @apache {
internal;
proxy_pass http://127.0.0.1:88;
#include proxy.conf;
}
location ~ .*.(php|php5)?$
{
proxy_pass http://127.0.0.1:88;
# include proxy.conf;
}
location /status {
stub_status on;
access_log off;
}
location ~ .*.(gif|jpg|jpeg|png|bmp|swf)$
{
access_log off;
expires 30d;
}
location ~ .*.(js|css)?$
{
access_log off;
expires 12h;
}
access_log /data/log/51buyhost/access.log;
}
include /etc/nginx/conf.d/*.conf;
以上是我服务器的主配置文件了..
只真对www.51buyhost.com 这个站的... 虚拟主机配置文件我就不亮出来了.
以上就是nginx 的整个配置文件了.还有一个虚拟主机在里面
下面我亮出我的apache配置文件
apache配置文件比较多 我只告诉大家我修改了哪些地方而已
[root@51buyhost ~]# vim /etc/httpd/conf/httpd.conf
在大概136行的样子增加以下内容
把默认的 80 端口注释
Listen 127.0.0.1:88
还有在最下面增加以下内容
Include /etc/httpd/conf/51buyhost.conf
我给大家最好都是默认的配置吧,因为 个人有个人的配置访问 ,,我测试的时候 只在apache配置文件里加了以上内容
接下来就设置51buyhost.conf 的内容
上面带了dz 伪静态的规则
<VirtualHost *:88>
DocumentRoot "/data/51buyhost"
ServerName www.51buyhost.com
ServerAlias 51buyhost.com
<Directory "/data/51buyhost">
allow from all
Options +Indexes
</Directory>
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/topic-(.+).html$ $1/portal.php?mod=topic&topic=$2&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/article-([0-9]+)-([0-9]+).html$ $1/portal.php?mod=view&aid=$2&page=$3&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/forum-(w+)-([0-9]+).html$ $1/forum.php?mod=forumdisplay&fid=$2&page=$3&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/thread-([0-9]+)-([0-9]+)-([0-9]+).html$ $1/forum.php?mod=viewthread&tid=$2&extra=page%3D$4&page=$3&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/group-([0-9]+)-([0-9]+).html$ $1/forum.php?mod=group&fid=$2&page=$3&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/space-(username|uid)-(.+).html$ $1/home.php?mod=space&$2=$3&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/blog-([0-9]+)-([0-9]+).html$ $1/home.php?mod=space&uid=$2&do=blog&id=$3&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/([a-z]+[a-z0-9_]*)-([a-z0-9_-]+).html$ $1/plugin.php?id=$2:$3&%1
RewriteCond %{http_host} ^51buyhost.com [NC]
RewriteRule ^(.*)$ http://www.51buyhost.com [L,R=301]
</IfModule>
<IfModule mod_mem_cache.c>
CacheEnable mem /
MCacheMaxObjectCount 20000
MCacheMaxObjectSize 1048576
MCacheMaxStreamingBuffer 65536
MCacheMinObjectSize 10
MCacheRemovalAlgorithm GDSF
MCacheSize 4096
CacheMaxExpire 864000
CacheDefaultExpire 86400
CacheDisable /php
</IfModule>
#</Directory>
ExpiresActive on
ExpiresBytype text/css "access plus 3 days
ExpiresByType application/x-javascript "access plus 3 days "
ExpiresByType image/jpeg "access plus 3 days "
Expiresbytype image/gif "access plus 3 days "
Expiresbytype image/png "access plus 3 days "
#</Directory>
</VirtualHost>
30.请写一段PHP代码,确保多个进程同时写入同一个文件成功
$file
=
fopen
(
"test.txt"
,
"w+"
);
// 排它性的锁定 先锁上,写完,打开。
if
(
flock
(
$file
,LOCK_EX))
{
fwrite(
$file
,
"Write something"
);
// release lock
flock
(
$file
,LOCK_UN);
}
else
{
echo
"Error locking file!"
;
}
fclose(
$file
);
31.怎么解决php创建中文文件夹及中文名出现乱码问题?
function iconv_system($str){
global $config;
$result = iconv($config['app_charset'], $config['system_charset'], $str);
if (strlen($result)==0) {
$result = $str;
}
return $result;
}
$path = iconv_system($absolute_path .'home/'.$dir);
mk_dir($path);
32.常用的nosql有哪些?分别的应用场景如何?
特点:它们可以处理超大量的数据。
它们运行在便宜的PC服务器集群上。
PC集群扩充起来非常方便并且成本很低,避免了“sharding”操作的复杂性和成本。
它们击碎了性能瓶颈。
NoSQL的支持者称,通过NoSQL架构可以省去将Web或Java应用和数据转换成SQL友好格式的时间,执行速度变得更快。
“SQL并非适用于所有的程序代码,” 对于那些繁重的重复操作的数据,SQL值得花钱。但是当数据库结构非常简单时,SQL可能没有太大用处。
没有过多的操作。
虽然NoSQL的支持者也承认关系数据库提供了无可比拟的功能集合,而且在数据完整性上也发挥绝对稳定,他们同时也表示,企业的具体需求可能没有那么多。
Bootstrap支持
因为NoSQL项目都是开源的,因此它们缺乏供应商提供的正式支持。这一点它们与大多数开源项目一样,不得不从社区中寻求支持。
优点:
易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
大数据量,高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。一般MySQL使用 Query Cache,每次表的更新Cache就失效,是一种大粒度的Cache,在针对web2.0的交互频繁的应用,Cache性能不高。而NoSQL的 Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多了。
灵活的数据模型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。这点在大数据量的web2.0时代尤其明显。
高可用
NoSQL在不太影响性能的情况,就可以方便的实现高可用的架构。比如Cassandra,HBase模型,通过复制模型也能实现高可用。
主要应用:
Apache HBase
这个大数据管理平台建立在谷歌强大的BigTable管理引擎基础上。作为具有开源、Java编码、分布式多个优势的数据库,Hbase最初被设计应用于Hadoop平台,而这一强大的数据管理工具,也被Facebook采用,用于管理消息平台的庞大数据。
Apache Storm
用于处理高速、大型数据流的分布式实时计算系统。Storm为Apache Hadoop添加了可靠的实时数据处理功能,同时还增加了低延迟的仪表板、安全警报,改进了原有的操作方式,帮助企业更有效率地捕获商业机会、发展新业务。
Apache Spark
该技术采用内存计算,从多迭代批量处理出发,允许将数据载入内存做反复查询,此外还融合数据仓库、流处理和图计算等多种计算范式,Spark用Scala语言实现,构建在HDFS上,能与Hadoop很好的结合,而且运行速度比MapReduce快100倍。
Apache Hadoop
该技术迅速成为了大数据管理标准之一。当它被用来管理大型数据集时,对于复杂的分布式应用,Hadoop体现出了非常好的性能,平台的灵活性使它可以运行在商用硬件系统,它还可以轻松地集成结构化、半结构化和甚至非结构化数据集。
Apache Drill
你有多大的数据集?其实无论你有多大的数据集,Drill都能轻松应对。通过支持HBase、Cassandra和MongoDB,Drill建立了交互式分析平台,允许大规模数据吞吐,而且能很快得出结果。
Apache Sqoop
也许你的数据现在还被锁定于旧系统中,Sqoop可以帮你解决这个问题。这一平台采用并发连接,可以将数据从关系数据库系统方便地转移到Hadoop中,可以自定义数据类型以及元数据传播的映射。事实上,你还可以将数据(如新的数据)导入到HDFS、Hive和Hbase中。
Apache Giraph
这是功能强大的图形处理平台,具有很好可扩展性和可用性。该技术已经被Facebook采用,Giraph可以运行在Hadoop环境中,可以将它直接部署到现有的Hadoop系统中。通过这种方式,你可以得到强大的分布式作图能力,同时还能利用上现有的大数据处理引擎。
Cloudera Impala
Impala模型也可以部署在你现有的Hadoop群集上,监视所有的查询。该技术和MapReduce一样,具有强大的批处理能力,而且Impala对于实时的SQL查询也有很好的效果,通过高效的SQL查询,你可以很快的了解到大数据平台上的数据。
Gephi
它可以用来对信息进行关联和量化处理,通过为数据创建功能强大的可视化效果,你可以从数据中得到不一样的洞察力。Gephi已经支持多个图表类型,而且可以在具有上百万个节点的大型网络上运行。Gephi具有活跃的用户社区,Gephi还提供了大量的插件,可以和现有系统完美的集成到一起,它还可以对复杂的IT连接、分布式系统中各个节点、数据流等信息进行可视化分析。
MongoDB
这个坚实的平台一直被很多组织推崇,它在大数据管理上有极好的性能。MongoDB最初是由DoubleClick公司的员工创建,现在该技术已经被广泛的应用于大数据管理。MongoDB是一个应用开源技术开发的NoSQL数据库,可以用于在JSON这样的平台上存储和处理数据。目前,纽约时报、Craigslist以及众多企业都采用了MongoDB,帮助他们管理大型数据集。(Couchbase服务器也作为一个参考)。
十大顶尖公司:
Amazon Web Services
Forrester将AWS称为“云霸主”,谈到云计算领域的大数据,那就不得不提到亚马逊。该公司的Hadoop产品被称为EMR(Elastic Map Reduce),AWS解释这款产品采用了Hadoop技术来提供大数据管理服务,但它不是纯开源Hadoop,经过修改后现在被专门用在AWS云上。
Forrester称EMR有很好的市场前景。很多公司基于EMR为客户提供服务,有一些公司将EMR应用于数据查询、建模、集成和管理。而且AWS还在创新,Forrester称未来EMR可以基于工作量的需要自动缩放调整大小。亚马逊计划为其产品和服务提供更强大的EMR支持,包括它的RedShift数据仓库、新公布的Kenesis实时处理引擎以及计划中的NoSQL数据库和商业智能工具。不过AWS还没有自己的Hadoop发行版。
Cloudera
Cloudera有开源Hadoop的发行版,这个发行版采用了Apache Hadoop开源项目的很多技术,不过基于这些技术的发行版也有很大的进步。Cloudera为它的Hadoop发行版开发了很多功能,包括Cloudera管理器,用于管理和监控,以及名为Impala的SQL引擎等。Cloudera的Hadoop发行版基于开源Hadoop,但也不是纯开源的产品。当Cloudera的客户需要Hadoop不具备的某些功能时,Cloudera的工程师们就会实现这些功能,或者找一个拥有这项技术的合作伙伴。Forrester表示:“Cloudera的创新方法忠于核心Hadoop,但因为其可实现快速创新并积极满足客户需求,这一点使它不同于其他那些供应商。”目前,Cloudera的平台已经拥有200多个付费客户,一些客户在Cloudera的技术支持下已经可以跨1000多个节点实现对PB级数据的有效管理。
Hortonworks
和Cloudera一样,Hortonworks是一个纯粹的Hadoop技术公司。与Cloudera不同的是,Hortonworks坚信开源Hadoop比任何其他供应商的Hadoop发行版都要强大。Hortonworks的目标是建立Hadoop生态圈和Hadoop用户社区,推进开源项目的发展。Hortonworks平台和开源Hadoop联系紧密,公司管理人员表示这会给用户带来好处,因为它可以防止被供应商套牢(如果Hortonworks的客户想要离开这个平台,他们可以轻松转向其他开源平台)。这并不是说Hortonworks完全依赖开源Hadoop技术,而是因为该公司将其所有开发的成果回报给了开源社区,比如Ambari,这个工具就是由Hortonworks开发而成,用来填充集群管理项目漏洞。Hortonworks的方案已经得到了Teradata、Microsoft、Red Hat和SAP这些供应商的支持。
IBM
当企业考虑一些大的IT项目时,很多人首先会想到IBM。IBM是Hadoop项目的主要参与者之一,Forrester称IBM已有100多个Hadoop部署,它的很多客户都有PB级的数据。IBM在网格计算、全球数据中心和企业大数据项目实施等众多领域有着丰富的经验。“IBM计划继续整合SPSS分析、高性能计算、BI工具、数据管理和建模、应对高性能计算的工作负载管理等众多技术。”
Intel
和AWS类似,英特尔不断改进和优化Hadoop使其运行在自己的硬件上,具体来说,就是让Hadoop运行在其至强芯片上,帮助用户打破Hadoop系统的一些限制,使软件和硬件结合的更好,英特尔的Hadoop发行版在上述方面做得比较好。Forrester指出英特尔在最近才推出这个产品,所以公司在未来还有很多改进的可能,英特尔和微软都被认为是Hadoop市场上的潜力股。
MapR Technologies
MapR的Hadoop发行版目前为止也许是最好的了,不过很多人可能都没有听说过。Forrester对Hadoop用户的调查显示,MapR的评级最高,其发行版在架构和数据处理能力上都获得了最高分。MapR已将一套特殊功能融入其Hadoop发行版中。例如网络文件系统(NFS)、灾难恢复以及高可用性功能。Forrester说MapR在Hadoop市场上没有Cloudera和Hortonworks那样的知名度,MapR要成为一个真正的大企业,还需要加强伙伴关系和市场营销。
Microsoft
微软在开源软件问题上一直很低调,但在大数据形势下,它不得不考虑让Windows也兼容Hadoop,它还积极投入到开源项目中,以更广泛地推动Hadoop生态圈的发展。我们可以在微软的公共云Windows Azure HDInsight产品中看到其成果。微软的Hadoop服务基于Hortonworks的发行版,而且是为Azure量身定制的。
微软也有一些其他的项目,包括名为Polybase的项目,让Hadoop查询实现了SQLServer查询的一些功能。Forrester说:“微软在数据库、数据仓库、云、OLAP、BI、电子表格(包括PowerPivot)、协作和开发工具市场上有很大优势,而且微软拥有庞大的用户群,但要在Hadoop这个领域成为行业领导者还有很远的路要走。”
Pivotal Software
EMC和Vmware部分大数据业务分拆组合产生了Pivotal。Pivotal一直努力构建一个性能优越的Hadoop发行版,为此,Pivotal在开源Hadoop的基础上又添加了一些新的工具,包括一个名为HAWQ的SQL引擎以及一个专门解决大数据问题的Hadoop应用。Forrester称Pivotal Hadoop平台的优势在于它整合了Pivotal、EMC、Vmware的众多技术,Pivotal的真正优势实际上等于EMC和Vmware两大公司为其撑腰。到目前为止,Pivotal的用户还不到100个,而且大多是中小型客户。
Teradata
对于Teradata来说,Hadoop既是一种威胁也是一种机遇。数据管理,特别是关于SQL和关系数据库这一领域是Teradata的专长。所以像Hadoop这样的NoSQL平台崛起可能会威胁到Teradata。相反,Teradata接受了Hadoop,通过与Hortonworks合作,Teradata在Hadoop平台集成了SQL技术,这使Teradata的客户可以在Hadoop平台上方便地使用存储在Teradata数据仓库中的数据。
AMPLab
通过将数据转变为信息,我们才可以理解世界,而这也正是AMPLab所做的。AMPLab致力于机器学习、数据挖掘、数据库、信息检索、自然语言处理和语音识别等多个领域,努力改进对信息包括不透明数据集内信息的甄别技术。除了Spark,开源分布式SQL查询引擎Shark也源于AMPLab,Shark具有极高的查询效率,具有良好的兼容性和可扩展性。近几年的发展使计算机科学进入到全新的时代,而AMPLab为我们设想一个运用大数据、云计算、通信等各种资源和技术灵活解决难题的方案,以应对越来越复杂的各种难题。
33.常用的缓存有哪些?分别的应用场景如何?
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
本篇文章,主要介绍利用PHP使用Redis,主要的应用场景。
简单字符串缓存实战
$redis->connect('127.0.0.1', 6379);
$strCacheKey = 'Test_bihu';
//SET 应用
$arrCacheData = [
'name' => 'job',
'sex' => '男',
'age' => '30'
];
$redis->set($strCacheKey, json_encode($arrCacheData));
$redis->expire($strCacheKey, 30); # 设置30秒后过期
$json_data = $redis->get($strCacheKey);
$data = json_decode($json_data);
print_r($data->age); //输出数据
//HSET 应用
$arrWebSite = [
'google' => [
'google.com',
'google.com.hk'
],
];
$redis->hSet($strCacheKey, 'google', json_encode($arrWebSite['google']));
$json_data = $redis->hGet($strCacheKey, 'google');
$data = json_decode($json_data);
print_r($data); //输出数据
简单队列实战
$redis->connect('127.0.0.1', 6379);
$strQueueName = 'Test_bihu_queue';
//进队列
$redis->rpush($strQueueName, json_encode(['uid' => 1,'name' => 'Job']));
$redis->rpush($strQueueName, json_encode(['uid' => 2,'name' => 'Tom']));
$redis->rpush($strQueueName, json_encode(['uid' => 3,'name' => 'John']));
echo "---- 进队列成功 ---- <br /><br />";
//查看队列
$strCount = $redis->lrange($strQueueName, 0, -1);
echo "当前队列数据为: <br />";
print_r($strCount);
//出队列
$redis->lpop($strQueueName);
echo "<br /><br /> ---- 出队列成功 ---- <br /><br />";
//查看队列
$strCount = $redis->lrange($strQueueName, 0, -1);
echo "当前队列数据为: <br />";
print_r($strCount);
简单发布订阅实战
//以下是 pub.php 文件的内容 cli下运行
ini_set('default_socket_timeout', -1);
$redis->connect('127.0.0.1', 6379);
$strChannel = 'Test_bihu_channel';
//发布
$redis->publish($strChannel, "来自{$strChannel}频道的推送");
echo "---- {$strChannel} ---- 频道消息推送成功~ <br/>";
$redis->close();
//以下是 sub.php 文件内容 cli下运行
ini_set('default_socket_timeout', -1);
$redis->connect('127.0.0.1', 6379);
$strChannel = 'Test_bihu_channel';
//订阅
echo "---- 订阅{$strChannel}这个频道,等待消息推送...---- <br/><br/>";
$redis->subscribe([$strChannel], 'callBackFun');
function callBackFun($redis, $channel, $msg)
{
print_r([
'redis' => $redis,
'channel' => $channel,
'msg' => $msg
]);
}
简单计数器实战
$redis->connect('127.0.0.1', 6379);
$strKey = 'Test_bihu_comments';
//设置初始值
$redis->set($strKey, 0);
$redis->INCR($strKey); //+1
$redis->INCR($strKey); //+1
$redis->INCR($strKey); //+1
$strNowCount = $redis->get($strKey);
echo "---- 当前数量为{$strNowCount}。 ---- ";
排行榜实战
$redis->connect('127.0.0.1', 6379);
$strKey = 'Test_bihu_score';
//存储数据
$redis->zadd($strKey, '50', json_encode(['name' => 'Tom']));
$redis->zadd($strKey, '70', json_encode(['name' => 'John']));
$redis->zadd($strKey, '90', json_encode(['name' => 'Jerry']));
$redis->zadd($strKey, '30', json_encode(['name' => 'Job']));
$redis->zadd($strKey, '100', json_encode(['name' => 'LiMing']));
$dataOne = $redis->ZREVRANGE($strKey, 0, -1, true);
echo "---- {$strKey}由大到小的排序 ---- <br /><br />";
print_r($dataOne);
$dataTwo = $redis->ZRANGE($strKey, 0, -1, true);
echo "<br /><br />---- {$strKey}由小到大的排序 ---- <br /><br />";
print_r($dataTwo);
简单字符串悲观锁实战
解释:悲观锁(Pessimistic Lock), 顾名思义,就是很悲观。
每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁。
场景:如果项目中使用了缓存且对缓存设置了超时时间。
当并发量比较大的时候,如果没有锁机制,那么缓存过期的瞬间,
大量并发请求会穿透缓存直接查询数据库,造成雪崩效应。
/**
* 获取锁
* @param String $key 锁标识
* @param Int $expire 锁过期时间
* @return Boolean
*/
public function lock($key = '', $expire = 5) {
$is_lock = $this->_redis->setnx($key, time()+$expire);
//不能获取锁
if(!$is_lock){
//判断锁是否过期
$lock_time = $this->_redis->get($key);
//锁已过期,删除锁,重新获取
if (time() > $lock_time) {
unlock($key);
$is_lock = $this->_redis->setnx($key, time() + $expire);
}
}
return $is_lock? true : false;
}
/**
* 释放锁
* @param String $key 锁标识
* @return Boolean
*/
public function unlock($key = ''){
return $this->_redis->del($key);
}
// 定义锁标识
$key = 'Test_bihu_lock';
// 获取锁
$is_lock = lock($key, 10);
if ($is_lock) {
echo 'get lock success<br>';
echo 'do sth..<br>';
sleep(5);
echo 'success<br>';
unlock($key);
} else { //获取锁失败
echo 'request too frequently<br>';
}
简单事务的乐观锁实战
解释:乐观锁(Optimistic Lock), 顾名思义,就是很乐观。
每次去拿数据的时候都认为别人不会修改,所以不会上锁。
watch命令会监视给定的key,当exec时候如果监视的key从调用watch后发生过变化,则整个事务会失败。
也可以调用watch多次监视多个key。这样就可以对指定的key加乐观锁了。
注意watch的key是对整个连接有效的,事务也一样。
如果连接断开,监视和事务都会被自动清除。
当然了exec,discard,unwatch命令都会清除连接中的所有监视。
$strKey = 'Test_bihu_age';
$redis->set($strKey,10);
$age = $redis->get($strKey);
echo "---- Current Age:{$age} ---- <br/><br/>";
$redis->watch($strKey);
// 开启事务
$redis->multi();
//在这个时候新开了一个新会话执行
$redis->set($strKey,30); //新会话
echo "---- Current Age:{$age} ---- <br/><br/>"; //30
$redis->set($strKey,20);
$redis->exec();
$age = $redis->get($strKey);
echo "---- Current Age:{$age} ---- <br/><br/>"; //30
//当exec时候如果监视的key从调用watch后发生过变化,则整个事务会失败【memcache缓存专题(1)】memcache的介绍与应用场景
简介
Memcached是一个高性能的分布式的内存对象缓存系统,目前全世界不少人使用这个缓存项目来构建自己大负载的网站,来分担数据库的压力,通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。简单的说就是将数据调用到内存中,然后从内存中读取,从而大大提高读取速度。
MemCache的工作流程如下:先检查客户端的请求数据是否在memcached中,如有,直接把请求数据返回,不再对数据库进行任何操作;如果请求的数据不在memcached中,就去查数据库,把从数据库中获取的数据返回给客户端,同时把数据缓存一份到memcached中(memcached客户端不负责,需要程序明确实现);每次更新数据库的同时更新memcached中的数据,保证一致性;当分配给memcached内存空间用完之后,会使用LRU(Least Recently Used,最近最少使用)策略加上到期失效策略,失效数据首先被替换,然后再替换掉最近未使用的数据。
Memcached是以守护程序(监听)方式运行于一个或多个服务器中,随时会接收客户端的连接和操作。默认监听端口为11211。
在 Memcached中可以保存的item数据量是没有限制的,只要内存足够 。
Memcached单进程在32位系统中最大使用内存为2G,若在64位系统则没有限制,这是由于32位系统限制单进程最多可使用2G内存,要使用更多内存,可以分多个端口开启多个Memcached进程,最大30天的数据过期时间,设置为永久的也会在这个时间过期,常量REALTIME_MAXDELTA 60*60*24*30控制。
最大键长为250字节,大于该长度无法存储,常量KEY_MAX_LENGTH 250控制.
单个item最大数据是1MB,超过1MB数据不予存储,常量POWER_BLOCK 1048576进行控制.但一般都是存储一些文本,如新闻列表等等,这个值足够了
memcached 用 slab allocator 机制来管理内存(在本专题的后续文章中会专门说这个内存机制的).它是默认的slab大小最大同时连接数是200,通过 conn_init()中的freetotal进行控制,最大软连接数是1024,通过settings.maxconns=1024 进行控制跟空间占用相关的参数:settings.factor=1.25, settings.chunk_size=48, 影响slab的数据占用和步进方式。
memcached是一种无阻塞的socket通信方式服务,基于libevent库,由于无阻塞通信,对内存读写速度非常之快。
memcached分服务器端和客户端,可以配置多个服务器端和客户端,应用于分布式的服务非常广泛。
memcached作为小规模的数据分布式平台是十分有效果的。
memcached是键值一一对应,key默认最大不能超过128个字节,value默认大小是1M,也就是一个slabs,如果要存2M的值(连续的),不能用两个slabs,因为两个slabs不是连续的,无法在内存中 存储,故需要修改slabs的大小,多个key和value进行存储时,即使这个slabs没有利用完,那么也不会存放别的数据。
memcached已经可以支持C/C++、Perl、PHP、Python、Ruby、Java、C#、Postgres、Chicken Scheme、Lua、MySQL和Protocol等语言客户端。
应用场景
使用Memcache的网站一般流量都是比较大的,为了缓解数据库的压力,让Memcache作为一个缓存区域,把部分信息保存在内存中,在前端能够迅速的进行存取。并且通过memcache的时效expire特性,还可以更简单的完成一些功能,我总结如下:
应用场景一: 缓解数据库压力,提高交互速度。
在开发中不管是基于框架的面向对象开发,还是面向过程开发,数据模型一定是要经过封装后再使用的,这样我们就可以对程序做统一处理,比如在程序开发初期,我们没用memcache或者redis来做缓存,我们把从数据库里面取数据统统使用query($sql)方法来读数据;
/**
* 数据库查询伪代码,仅仅是提供一个思路
* @param string $sql sql语句,比如select * form sc_users;
* @param int $expire 缓存失效时间
* @param int $type 1直接从数据库里面读取,0先走缓存,再走数据库
* @return {[type]} [description]
*/
public function query($sql,$expire=300,$type=0){
if($type == 1){
return '直接从数据库里面取出来';
}
$key = md5($sql); //以md5后的sql作为key
$result = $this -> mem -> get($key);
//如果缓存里面没有
if(empty($result)){
$data = '从数据库里面取到数据';
//放入缓存
$this -> mem -> add($key,$data,MEMCACHE_COMPRESSED,$expire); //$data是个数组,所以要序列化压缩一下
return $data;
}
//如果有的话就直接返回;
return $result;
}它的一个总原则是将经常需要从数据库读取的数据缓存在memcached中。这些数据也分为几类:
一、经常被读取并且实时性要求不强可以等到自动过期的数据。例如网站首页最新文章列表、某某排行等数据。也就是虽然新数据产生了,但对用户体验不会产生任何影响的场景。
这类数据就使用典型的缓存策略,设置一过合理的过期时间,当数据过期以后再从数据库中读取。当然你得制定一个缓存清除策略,便于编辑或者其它人员能马上看到效果。
二、经常被读取并且实时性要求强的数据。比如用户的好友列表,用户文章列表,用户阅读记录等。
这类数据首先被载入到memcached中,当发生更改(添加、修改、删除)时就清除缓存。在缓存的时候,我将查询的SQL语句md5()得到它的 hash值作为key,结果数组作为值写入memcached,并且将该SQL涉及的table_name以及hash值配对存入memcached中。 当更改了这个表时,我就将与此表相配对的key的缓存全部删除。
三、统计类缓存,比如文章浏览数、网站PV等
此类缓存是将在数据库的中来累加的数据放在memcached来累加。获取也通过memcached来获取。但这样就产生了一个问题,如果memcached服务器down 掉的话这些数据就有可能丢失,所以一般使用memcached的永固性存储,这方面新浪使用memcachedb。
四、活跃用户的基本信息或者某篇热门文章。
此类数据的一个特点就是数据都是一行,也就是一个一维数组,当数据被update时(比如修改昵称、文章的评论数),在更改数据库数据的同时,使用Memcache::replace替换掉缓存里的数据。这样就有效了避免了再次查询数据库。
五、session数据
使用memcached来存储session的效率是最高的。memcached本身也是非常稳定的,不太用担心它会突然down掉引起session数据的丢失,即使丢失就重新登录了,也没啥。
六、冷热数据交互
在做高访问量的sns应用,比如贴吧和论坛,由于其数据量大,往往采用了分表分库的策略,但真正的热数据仅仅是前两三页的100条数据,这时,我们就可以把这100条数据,在写进数据库之后,同时作为memcache的缓存热数据来使用。
通过以上的策略数据库的压力将会被大大减轻。检验你使用memcached是否得当的方法是查看memcached的命中率。有些策略好的网站的命中率可以到达到90%以上。后续本专题也会讨论一下memcache的分布式算法,提高其命中率;
应用场景二: 秒杀功能。
其实,本场景严格的说应该也属于场景一,单独拎出来说是由于其广泛的应用性。
一个人下单,要牵涉数据库读取,写入订单,更改库存,及事务要求, 对于传统型数据库来说,压力是巨大的。
可以利用 memcached 的 incr/decr 功能, 在内存存储 count 库存量, 秒杀 1000 台每人抢单主要在内存操作,速度非常快,抢到 count < =1000 的号人,得一个订单号,这时再去另一个页面慢慢支付。
应用场景三:中继 MySQL 主从延迟数据
MySQL 在做 replication 时,主从复制之间必然要经历一个复制过程,即主从延迟的时间.
尤其是主从服务器处于异地机房时,这种情况更加明显.
比如facebook 官方的一篇技术文章,其加州的主数据中心到弗吉尼亚州的主从同步延期达到70ms;
考虑如下场景:
①: 用户 U 购买电子书 B, insert into Master (U,B);
②: 用户 U 观看电子书 B, select 购买记录[user=’A’,book=’B’] from Slave.
③: 由于主从延迟,第②步中无记录,用户无权观看该书.
这时,可以利用 memached 在 master 与 slave 之间做过渡(如下图):
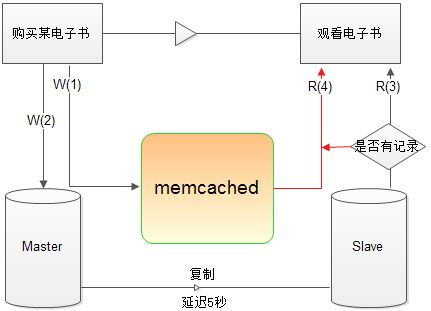
①: 用户 U 购买电子书 B, memcached->add(‘U:B’,true)
②: 主数据库 insert into Master (U,B);
③: 用户 U 观看电子书 B, select 购买记录[user=’U’,book=’B’] from Slave.
如果没查询到,则 memcached->get(‘U:B’),查到则说明已购买但 Slave 延迟.
④: 由于主从延迟,第②步中无记录,用户无权观看该书.
不适用memcached的业务场景
- 缓存对象的大小大于1MB
Memcached本身就不是为了处理庞大的多媒体(large media)和巨大的二进制块(streaming huge blobs)而设计的。 - key的长度大于250字符(所以我们把一些key先md5再存储)。
- 应用运行在不安全的环境中Memcached为提供任何安全策略,仅仅通过telnet就可以访问到memcached。如果应用运行在共享的系统上,需要着重考虑安全问题。
- 业务本身需要的是持久化数据。
Memcache的安全
只说一下思路:
把memcached的端口给禁止掉(这时只能本ip访问),让其他ip的使用者只能通过对外开放的80端口访问PHP脚本文件,再通过PHP的脚本文件去访问memcache;
iptables -a input -p 协议 -s 可以访问ip -dport 端口 -j ACCEPT34. 请解释php中的垃圾回收机制?
PHP垃圾回收机制是php5之后才有的这个东西,下面我来给大家介绍一下关于PHP垃圾回收机制一些理解,希望对各位同学有所帮助。 php 5 3之前使用的垃圾回收机制是单纯的引用计数,也就是每个内存对象都分配一个计数PHP垃圾回收机制是php5之后才有的这个东西,下面我来给大家介绍一下关于PHP垃圾回收机制一些理解,希望对各位同学有所帮助。
php 5.3之前使用的垃圾回收机制是单纯的“引用计数”,也就是每个内存对象都分配一个计数器,当内存对象被变量引用时,计数器 1;当变量引用撤掉后,计数器-1;当计数器=0时,表明内存对象没有被使用,该内存对象则进行销毁,垃圾回收完成。
“引用计数”存在问题,就是当两个或多个对象互相引用形成环状后,内存对象的计数器则不会消减为0;这时候,这一组内存对象已经没用了,但是不能回收,从而导致内存泄露;
php5.3开始,使用了新的垃圾回收机制,在引用计数基础上,实现了一种复杂的算法,来检测内存对象中引用环的存在,以避免内存泄露。
35. php常用的设计模式有哪些?设计模式的6大原则是什么?
一.6大原则
1.单一职责原则(Single Responsibility Principle)
定义:就一个类而言,应该仅有一个引起它变化的原因;
如果一个类承担的职责过多,就等于把这些职责耦合在一起,一个职责变化可能会消弱或者抑制这个类完成其他职责的能力。这种耦合会导致脆弱的设计,当变化发生时,设计会遭受到意想不到的破坏;
T负责两个不同的职责:职责P1,职责P2。当由于职责P1需求发生改变而需要修改类T时,有可能会导致原本运行正常的职责P2功能发生故障。也就是说职责P1和P2被耦合在了一起。
单一职责比较容易理解,但是在实际设计过程中容易发生职责扩散:因为某种原因,某一职责被分化为颗粒度更细的多个职责了。
解决办法:遵守单一职责原则,将不同的职责封装到不同的类或模块中。
2.里氏替换原则(LiskovSubstitution Principle)
定义:子类型必须能够替换掉它们的父类型;
一个软件实体如果使用的是一个父类的话,那么一定适用于其子类,而且它察觉不出父类对象和子类对象的区别。也就是说,在软件里面,把父类都替换成它的子类,程序的行为没有变化;
只有子类可以替换父类,软件单位功能不受到影响时,父类才能真正被复用,而子类也能够在父类的基础上增加新的行为;里氏代换原则是对“开-闭”原则的补充。实现“开-闭”原则的关键步骤就是抽象化。而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。
在进行设计的时候,我们尽量从抽象类继承,而不是从具体类继承。如果从继承等级树来看,所有叶子节点应当是具体类,而所有的树枝节点应当是抽象类或者接口。
3.依赖倒置原则(DependenceInversion Principle)
定义:
A.高层模块不应该依赖低层模块。两个都应该依赖抽象;
B.抽象不应该依赖细节,细节应该依赖抽象;(针对接口编程,而不是针对实现;)
面向过程的开发,上层调用下层,上层依赖于下层,当下层剧烈变动时上层也要跟着变动,这就会导致模块的复用性降低而且大大提高了开发的成本。依赖倒转很好的解决了这个问题;
4.合成/聚合原则(Composite/Aggregate Reuse Principle)
定义:尽量使用合成/聚合,尽量不要使用类继承;
优先使用对象的合成/聚合将有助于你保持每个类被封装,并被集中在单个任务上。这样类和类继承层次会保持较小规模,并且不太可能增长为不可控制的庞然大物;
为什么尽量不要使用类继承而使用合成/聚合?
对象的继承关系在编译时就定义好了,所以无法在运行时改变从父类继承的子类的实现。
子类的实现和它的父类有非常紧密的依赖关系,以至于父类实现中的任何变化必然会导致子类发生变化。
当你复用子类的时候,如果继承下来的实现不适合解决新的问题,则父类必须重写或者被其它更适合的类所替换。
这种依赖关系限制了灵活性,并最终限制了复用性。
5.迪米特法则(Law Of Demeter)
定义:如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用,如果其中一个类需要调用另一个类的某一个方法的话,可以通过第三者转发这个调用;
迪米特根本思想是:类之间的松耦合;
类之间的耦合越弱,越有利于复用,一个处于弱耦合的类被修改,不会对有关系的类造成波及。信息的隐藏促进了软件的复用;
广义的迪米特法则在类的设计上的体现:
优先考虑将一个类设置成不变类。
尽量降低一个类的访问权限。
谨慎使用Serializable。
尽量降低成员的访问权限。
6.开放-封闭原则(Open Closed Principle)
定义:软件实体(类,模块,函数等等)应该可以扩展,但是不可以修改;
对扩展开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况。
对修改封闭,意味着类一旦设计完成,就可以独立完成其工作,而不要对类进行任何修改。
这样的设计,能够面对需求改变却可以保持相对稳定,从而使系统在第一个版本以后不断推出新的版本;面对需求,对程序的改动是通过增加新的代码进行的,而不是更改现有的代码;
开放封闭原则,是最为重要的设计原则,Liskov替换原则和合成/聚合复用原则为开放封闭原则的实现提供保证。
二.3种类型
设计模式分为那几类,它们是怎么区分的,每一种模式类型的特点,包含具体模式呢?
设计模式按照目的来分,可以分为创建型模式、结构型模式和行为型模式。
1.创建型
创建型模式用来处理对象的创建过程,主要包含以下5种设计模式:
工厂方法模式(Factory Method Pattern)
抽象工厂模式(Abstract Factory Pattern)
建造者模式(Builder Pattern)
原型模式(Prototype Pattern)
单例模式(Singleton Pattern)
2.结构型
结构型模式用来处理类或者对象的组合,主要包含以下7种设计模式:
适配器模式(Adapter Pattern)
桥接模式(Bridge Pattern)
组合模式(Composite Pattern)
装饰者模式(Decorator Pattern)
外观模式(Facade Pattern)
享元模式(Flyweight Pattern)
代理模式(Proxy Pattern)
3.行为型
行为型模式用来对类或对象怎样交互和怎样分配职责进行描述,主要包含以下11种设计模式:
责任链模式(Chain of Responsibility Pattern)
命令模式(Command Pattern)
解释器模式(Interpreter Pattern)
迭代器模式(Iterator Pattern)
中介者模式(Mediator Pattern)
备忘录模式(Memento Pattern)
观察者模式(Observer Pattern)
状态模式(State Pattern)
策略模式(Strategy Pattern)
模板方法模式(Template Method Pattern)
访问者模式(Visitor Pattern)
三.总结
36. 常用的linux命令有哪些?
1、显示日期的指令: date

2、显示日历的指令:cal



3、简单好用的计算器:bc


怎么10/100会变成0呢?这是因为bc预设仅输出整数,如果要输出小数点下位数,那么就必须要执行 scale=number ,那个number就是小数点位数,例如:

4、重要的几个热键[Tab],[ctrl]-c, [ctrl]-d
[Tab]按键---具有『命令补全』不『档案补齐』的功能
[Ctrl]-c按键---让当前的程序『停掉』
[Ctrl]-d按键---通常代表着:『键盘输入结束(End Of File, EOF 戒 End OfInput)』的意思;另外,他也可以用来取代exit
5、man
退出用q,
man -f man

6、数据同步写入磁盘: sync
输入sync,那举在内存中尚未被更新的数据,就会被写入硬盘中;所以,这个挃令在系统关机戒重新启劢乀前, 径重要喔!最好多执行几次!

7、惯用的关机指令:shutdown

此外,需要注意的是,时间参数请务必加入指令中,否则shutdown会自动跳到 run-level 1 (就是单人维护的登入情况),这样就伤脑筋了!底下提供几个时间参数的例子吧:

重启,关机: reboot, halt,poweroff

8、切换执行等级: init
Linux共有七种执行等级:
--run level 0 :关机
--run level 3 :纯文本模式
--run level 5 :含有图形接口模式
--run level 6 :重新启动
使用init这个指令来切换各模式:
如果你想要关机的话,除了上述的shutdown -h now以及poweroff之外,你也可以使用如下的指令来关机:

9、改变文件的所属群组:chgrp

10、改变文件拥有者:chown
他还可以顸便直接修改群组的名称

11、改变文件的权限:chmod
权限的设定方法有两种, 分别可以使用数字或者是符号来进行权限的变更。 |
--数字类型改变档案权限:

--符号类型改变档案权限:

12、查看版本信息等

13、变换目录:cd

14、显示当前所在目录:pwd

15、建立新目录:mkdir


不建议常用-p这个选项,因为担心如果你打错字,那么目录名称就回变得乱七八糟的
16、删除『空』的目录:rmdir

17、档案与目录的显示:ls


18、复制档案或目录:cp







19、移除档案或目录:rm



20、移动档案与目录,或更名:mv


21、取得路径的文件名与目录名:basename,dirname


22、由第一行开始显示档案内容:cat


23、从最后一行开始显示:tac(可以看出 tac 是 cat 的倒着写)

24、显示的时候,顺道输出行号:nl



25、一页一页的显示档案内容:more

26、与 more 类似,但是比 more 更好的是,他可以往前翻页:less

27、只看头几行:head

28、只看尾几行:tail

29、以二进制的放置读取档案内容:od


30、修改档案时间或新建档案:touch



31、档案预设权限:umask

32、配置文件档案隐藏属性:chattr



33、显示档案隐藏属性:lsattr

34、观察文件类型:file

35、寻找【执行挡】:which


36、寻找特定档案:whereis

37、寻找特定档案:locate

38、寻找特定档案:find


39、压缩文件和读取压缩文件:gzip,zcat


40、压缩文件和读取压缩文件:bzip2,bzcat


41、压缩文件和读取压缩文件:tar






ps:IP.GZIP.TAR有啥区别?那个压缩的程度大?
tar是打包,不是压缩,只是把一堆文件打成一个文件而已GZIP用在HTTP协议上是一种用来改进WEB应用程序性能的技术,将网页内容压缩后再传输。
zip就不用说了,主流的压缩格式。
zip最新的压缩算法还是很好的,建议还是用zip格式化,全平台通用。
tar没有怎样压缩,压缩率100%,主要是永远打包,
zip压缩率看文件类型,jpg就没怎么压缩率,但bmp很高
gzip一般比zip高
37.echo intval(0.58*100)等于58为什么?
如果你仔细看过在PHP手册中,对于浮点数据类型的说明,就会看到其中有专门的一个警告提示,就谈到这个问题:
关于浮点数精度的警告
显然简单的十进制分数如同 0.1 或 0.7不能在不丢失一点点精度的情况下转换为内部二进制的格式。这就会造成混乱的结果:
例如,floor((0.1+0.7)*10)通常会返回 7 而不是预期中的 8,因为该结果内部的表示其实是类似 7.9。
这和一个事实有关,那就是不可能精确的用有限位数表达某些十进制分数。例如,十进制的 1/3 变成了 0.3。
所以永远不要相信浮点数结果精确到了最后一位,也永远不要比较两个浮点数是否相等。如果确实需要更高的精度,应该使用任意精度数学函数或者 gmp 函数。
实际上,并不是php会有这种现象,对于其他计算机语言,类似的浮点数问题也是差不多的
38.php使用swoole的应用场景,你知道的有哪些?
与硬件设备连接通讯(定位设备)
IM系统(用于直播页面的聊天通讯)
场景1 - 实时收集定位数据实时输出(例 滴滴司机行驶轨迹)
说明:
需要将所有的定位设备实时的接收,将实时的轨迹记录显示在地图上
注意点:
第一点:
web1服务器 连接的用户1,2,3,web1广播信息时只能广播用户1,2,3,不能广播web2连接的用户4,5,6,假设场景是聊天,用户1发送一消息,只有web1 服务器的用户能看到,web2的用户全部不能收到

第二点:消息的频率控制,例:100个设备,100个用户, 100个设备每秒上传一条数据,需要实时广播给每个用户,就是每秒要100*100 = 1W次,所以可以汇总每秒数据广播给所有用户等等方法
数据传输的流程图:
不包含业务逻辑,将web1,web2,接收的消息汇总然后再广播给web1,web2,再广播给用户

场景2 - 只收集定位设备入库
说明:需要把所有的定位设备上传的数据入库,设备7个,每秒一条数据,个人使用swoole 的task 函数(投递一个异步的任务到 task_worker池中,此函数是非阻塞的, worker进程数同样可以配置) 后调用接口方式入库
服务器内存报警问题
原因: 在于swoole_server->task 函数
官方介绍task底层使用Unix Socket管道通信,是全内存的,没有IO消耗。单进程读写性能可达100万/s,不同的进程使用不同的管道通信,可以最大化利用多核。
但这任务如果是调用程序接口时,由于网络的延迟,增加的任务大于消费的任务时,内存占用会不断的增加,导致服务器的内存被占满。
解决方法:消息针对入任务的频率控制,可以根据自己的业务场景定义这个时间与是否可延迟等情况,汇总1秒内的所有数据再调用程序接口(汇总时个人使用redis),最好能直接入库,不必调用接口
简单代码片段,不全(供初学者了解,官方网站demo相似)
function __construct($config)
{
$this->config = $config;
$this->serv = new Swoole\Server($config['server']['host'], $config['server']['port']);
// 连接redis
$this->redis = new Predis\Client($config['redis']);
$this->storage = new Storage($this->config);
$this->serv->set([
'worker_num' => $this->config['server']['workerNum'], //工作进程数量
'daemonize' => $this->config['server']['daemonize'], //是否作为守护进程
'task_worker_num' => $this->config['server']['taskWorkerNum'],
]);
$this->serv->on('connect', function ($serv, $fd){
$this->onConnect($fd, $serv);
});
$this->serv->on('receive', function ($serv, $fd, $from_id, $data) {
$this->onReceive($fd, $serv, $data);
});
$this->serv->on('Close', function($server, $fd) {
$this->onClose($fd, $server);
});
$this->serv->on('Task', function($server, $task_id, $from_id, $data) {
$this->onTask($server, $task_id, $from_id, $data);
});
$this->serv->on('Finish', function($server, $task_id, $data) {
$this->onFinish($server, $task_id, $data);
});
$this->serv->start();
}
public function onTask($serv, $task_id, $from_id, $data){
// insert 方法是通过接口入库
$this->storage->insert($data);
}
public function onReceive($fd, $serv, $data)
{
$this->storage->writeLog('message:'.$data);
$data = $this->formatData($data, $fd);
$serv->task($data);
}
public function onClose($fd, $serv)
{
// writeLog 方法是写入log
$this->storage->writeLog('close fd:'.$fd);
}
public function onFinish($serv, $task_id, $data)
{
return '';
}场景-IM系统
参考官方github: webim系统.
官方wiki: swoole 框架wiki
好处
封装了数据库的model类,数据库的ORM接口
redis的封装,可以实现多实例访问
框架有一些常用的方法,像log 等等(我只用到了log)
webim 官方有demon,可以参考
坏处:
文档特别不全,一个简单的实现会折腾半天
39. 协程、进程、线程分别是什么?
进程、线程和协程是三个在多任务处理中常听到的概念,三者各有区别又相互联系。
进程
进程是一个程序在一个数据集中的一次动态执行过程,可以简单理解为“正在执行的程序”,它是CPU资源分配和调度的独立单位。
进程一般由程序、数据集、进程控制块三部分组成。我们编写的程序用来描述进程要完成哪些功能以及如何完成;数据集则是程序在执行过程中所需要使用的资源;进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。
进程的局限是创建、撤销和切换的开销比较大。
线程
线程是在进程之后发展出来的概念。 线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,由线程ID、程序计数器、寄存器集合和堆栈共同组成。一个进程可以包含多个线程。
线程的优点是减小了程序并发执行时的开销,提高了操作系统的并发性能,缺点是线程没有自己的系统资源,只拥有在运行时必不可少的资源,但同一进程的各线程可以共享进程所拥有的系统资源,如果把进程比作一个车间,那么线程就好比是车间里面的工人。不过对于某些独占性资源存在锁机制,处理不当可能会产生“死锁”。
协程
协程是一种用户态的轻量级线程,又称微线程,英文名Coroutine,协程的调度完全由用户控制。人们通常将协程和子程序(函数)比较着理解。
子程序调用总是一个入口,一次返回,一旦退出即完成了子程序的执行。
协程的起始处是第一个入口点,在协程里,返回点之后是接下来的入口点。在python中,协程可以通过yield来调用其它协程。通过yield方式转移执行权的协程之间不是调用者与被调用者的关系,而是彼此对称、平等的,通过相互协作共同完成任务。其运行的大致流程如下:
第一步,协程A开始执行。
第二步,协程A执行到一半,进入暂停,通过yield命令将执行权转移到协程B。
第三步,(一段时间后)协程B交还执行权。
第四步,协程A恢复执行。- 1
- 2
- 3
- 4
协程的特点在于是一个线程执行,与多线程相比,其优势体现在:
- 协程的执行效率非常高。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
- 协程不需要多线程的锁机制。在协程中控制共享资源不加锁,只需要判断状态就好了。
Tips:利用多核CPU最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
参考:
1.进程、线程和协程的区别
2.协程-廖雪峰的官方网站
3.阮一峰的网络日志
40. 你如何运用docker搭建php环境?
在Docker流行之前,要搭建开发环境通常有两种选择:一种是使用wamp、xampp、mamp等集成开发环境安装包,另外一种就是使用普通虚拟机来安装linux服务器,然后通过下载一键安装包(如:lnmp)或者逐个安装做需要的软件。前者虽然简单,但太不灵活,想要安装额外的软件或者版本会很麻烦或者干脆不知道如何下手;后者除了费时费力,占用本机资源过多,可能会导致系统运行缓慢,而且如果你忘了及时生成快照,一旦失误,追悔莫及。
幸好,Docker来了!它简单易用,灵活多变,方便迅捷,扫除了以上种种弊端。如果你想稍微详细的认识下这位虚拟化界的明星,传送门( 快速理解Docker )。
安装Docker
平时开发的环境一般都是Mac或者windows,Linux暂时没有研究,所以接下来只针对前两者写下步骤,这两个平台,官方都推荐了两种安装方式:app和工具包(toolbox)。注:app方式对系统版本和配置会有一定要求,而且Windows需要你安装微软虚拟化产品Hyper-V,具体见app链接页面。
APP
https://docs.docker.com/docke...
https://docs.docker.com/docke...
工具包
https://www.docker.com/produc...
以上方式本质上都会在你的系统中安装docker-engine、docker-machine、docker-compose和VirtualBox(除了Windows的app方式)。因为docker高度依赖linux内核提供的cgroup,namespace 等特性和接口,所以mac和windows平台需要使用docker-machine和虚拟机在后台创建运行一个linux内核。
而我的安装方式就是直接在 Mac 上使用brew,如果你未曾安装brew,则在终端执行以下代码:
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
安装docker所需要的包:
brew install docker docker-machine docker-compose virtualbox
创建一个docker-machine:
docker-machine create -d virtualbox default
注:-d 指定使用virtualbox来创建default 为machine名称
告诉主机如何找到docker-machine:
echo $(docker-machine env ) >> .zshrc
注:这里的.zshrc是我的用户配置文件,如果你用bash,可以改为.bash_profile。
启动docker-machine:
docker-machine start default Compose你的应用
docker-compose是用于定义和运行复杂Docker应用的工具。你可以在docker-compose.yml文件中定义一个多容器的应用,然后使用一条命令来启动,然后所有预先定义好的操作都会被自动完成。
为了不重复造轮子,直接使用github上的第三方包。当然你也可以亲自构建每一个你所需要的容器镜像,然后用docker-compose.yml将所有容器组织起来运行,但这需要你具备一定的linux基础和docker的运行机制和相关语法。
本人正在学习 laradock 这个基于Docker的开发环境包,然后根据自己的需要删除了一些我认为不常用的部分、修改了部分配置以及增加了Elasticsearch容器,最终新开了自己的仓库 DevDock 。当然,也推荐使用laradock。
我的仓库目前支持的容器组合:
nginx , php-fpm , mysql , redis , mongo , apache2 , memcached , elasticsearch , workspace .
注:workspace和php-fpm一般会被其他容器所依赖,所以会自动运行,启动时不必指定。
进入到你的应用的上级目录:
git clone https://github.com/RystLee/DevDock.git
修改hosts
如果直接安装启动,是可以通过Docker IP : 192.168.99.100,就能直接访问nginx的,但一般而言为了方便记忆,我们会去修改hosts文件,增加一条:
192.168.99.100 laravel.dev
修改你的nginx中的站点配置文件:
在DevDock目录下找到nginx,修改sites目录下的站点配置文件,通过修改本地的hosts来自定义域名,并在nginx容器中的sites文件夹下,修改相应的域名映射。
server_name laravel.dev
安装启动应用
cd DevDock docker-compose up -d nginx mysql ... # 后面跟上你想使用的容器即可
然后,耐心地等待开发环境自动搭建完成即可,如果中途出现错误,一般是因为GFW,网络会不太通畅,重新执行一两次就好,完成之后,打开浏览器,访问: http://laravel.dev 即可。
41. 你如何运用docker搭建区块链环境?
预读先知
区块链(Blockchain)是一种安全的在线交易方式。区块链是一种分布式数字账目,在全球数以千计的计算机上记录交易,使得注册的交易不能被追溯改变。他们通过集体自利的大规模协作进行认证。结果是产生一个以参与者的数据安全的不确定性为边际的健壮的工作流。区块链的使用消除了来自数字资产的无限再现性的特性。它确认每个单位的数字现金只花了一次,解决了长期存在的双重支出问题。区块链被描述为价值交换协议。这种价值交换可以更快,更安全,更便宜地通过区块链完成。区块链可以分配所有权,因为它提供了强制提供和接受的记录。
以太坊(Ethereum)是一个运行智能合约的分布式平台:保证应用程序完全按照程序运行,没有任何宕机,审查,欺诈或第三方干扰的可能性。
这些应用程序运行在一个定制的区块链上。这使开发者能够创建市场,存储债务或承诺的记录,根据很久以前给出的指令转移资金(如遗嘱或期货合约)以及很多尚未出现的未来应用场景,所有的这些都没有中间人或者交易对手风险。
在传统的服务器体系结构上,每个应用程序都必须设置自己的服务器,在独立的孤岛中运行自己的代码,使数据共享变得困难。如果单个应用遭到入侵或离线,许多用户和其他应用都会受到影响。
在区块链上,任何人都可以设置一个节点,复制所有节点的必要数据以达成协议,并由用户和应用程序开发人员进行补偿。这允许用户数据保持私有和应用程序分散像互联网应该工作。
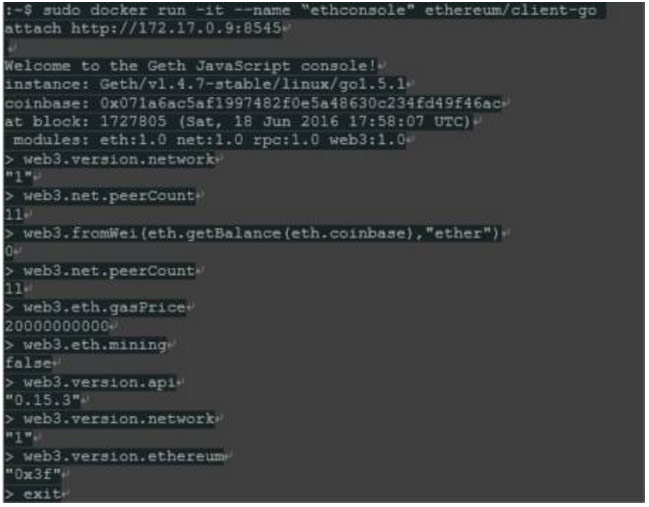
以太坊Go(语言)团队构建一个“geth”节点的Docker镜像作为其持续构建链的一部分。 我们可以使用这些镜像在我们的本地环境中快速运行以太坊节点。本文中我们将利用Docker构建一个以太坊工作和开发环境。
一个完整的以太坊节点
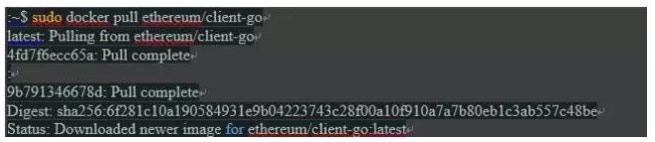
第一个测试是下载当前Ethereum go-client(“geth”)映像,并启动连接到以太坊生产网络的客户端节点。
现在,我们启动一个简单的节点,如在Ethereum文档中所描述的。一旦区块同步开始,请使用CTRL + C停止节点。我们不打算使用这个容器,所以现在不需要下载整个链数据。
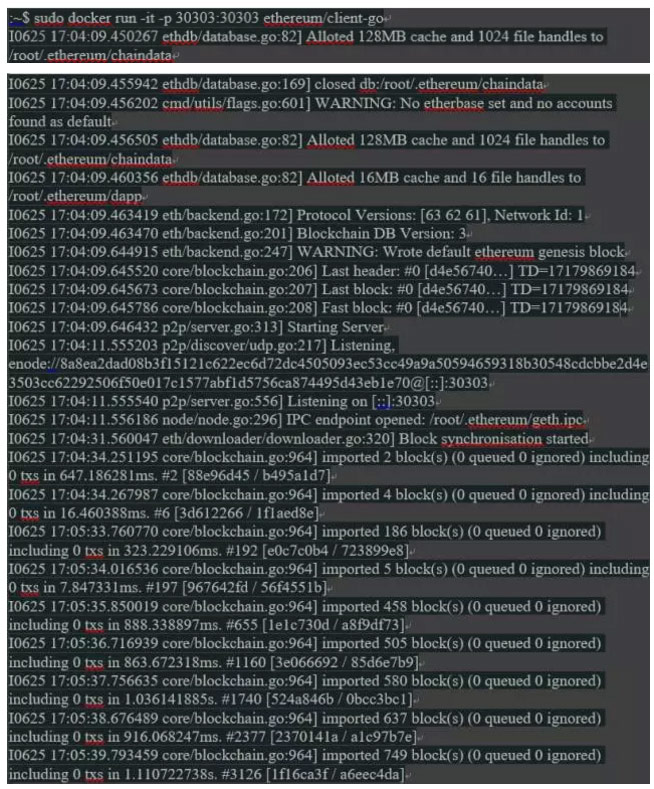
上面,我们使用RUN命令启动了Docker容器。 RUN拿一个叫做“ethereum / client-go”的镜像创建了一个新容器,并启动这个镜像定义的入口点(entry point)“/ usr / bin / geth”。
以下部分需要重点理解:
1 RUN总是创建一个新容器。这意味着,每次通过使用RUN来启动一个容器,我们最终将产生很多无用的容器。一旦创建了容器,重新启动它的正确方法是用START命令。
2 Docker RUN命令后的命令行参数 -it -p 30303:30303。等价于“-i -t”的“-it”代表“交互式”和“终端设备(tty)”。没有这些说明,容器将在后台运行,不会给我们的终端反馈。 “-p 30303:30303”指示Docker将端口30303从容器内部暴露给主机和其他容器,端口号为30303。容器是一个隔离的环境,并且不会隐含的暴露这个端口,以太坊客户端在容器内部将不能够接触外部世界和区块链。 30303是默认的以太坊点对点网络端口。镜像名称后面的其他参数用于镜像定义为启动时的起点的命令。本例中未设置。
3 另一个比较重要的是这个测试中存储区块链数据的地方。默认情况下,“geth”使用“$ userhome / .etherum”作为默认数据目录。容器内部运行时,如果没有指定,则为“root”:“/root/.ethereum”。然而,这个地方在其“虚拟盘”上的容器的“内部”。使数据位于容器内保持它与主机和其他容器隔离,这不一定是我们想要的。
在这个例子中,节点需要下载整个区块链数据。这需要大量的时间,带宽和存储空间,并且在各种容器和主机之间共享这些文件可能变得非常困难。
共享数据库在运行较大的应用程序时显然是一个典型的问题,Docker在这方面提供了多种选择。在以前的Docker版本中,人们经常使用所谓的“数据容器”。这些是经典和专用容器,独立于专用于存储数据的应用程序运行时实例。当前的Docker版本通过所谓的VOLUMES取代了这个想法。在本文中,我们将使用不同的解决方案:我们将区块链和帐户数据存储在主机的磁盘上,并将目录挂载到容器中。这对于以太坊有一些优势,我们将在后面介绍。
在继续之前,让我们看看我们目前在我们的安装中有什么镜像:

接下来,让我们列出我们的容器实例是否在运行。必须通过添加“-a”命令指定活动容器:
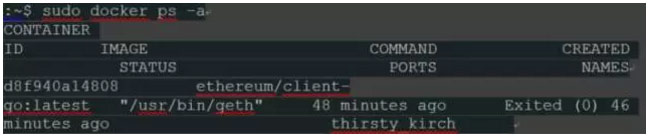
INSPECT命令非常方便,它显示容器的整个配置和情况。

我们当前的容器以前是使用RUN命令创建的,现在我们将使用START命令重新启动实例:
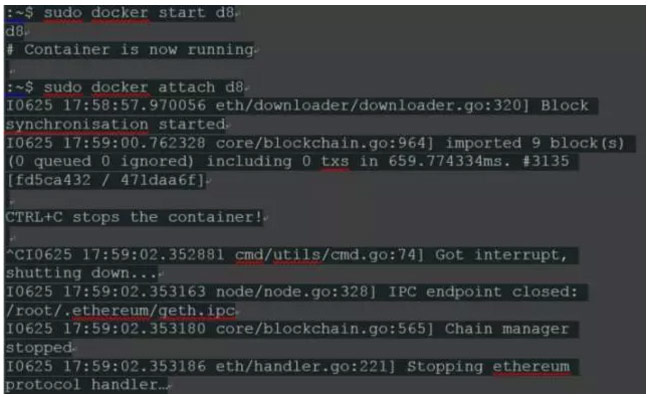
![]()
“-i”代表将容器输出到我们的终端,“d8”表示容器ID,它也可以是镜像名称,不需要输入完整的ID,只要它是唯一的。
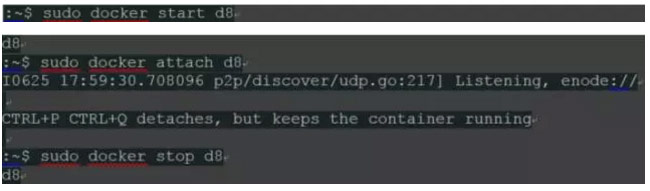
或者,我们可以在后台启动容器,并稍后连接终端。
或者:
完成这个测试,并了解了上面介绍的基本知识。下面我们将开始区域链之旅了!
我们要做的第一件事是将“geth”节点连接到以太坊生产网络,从而保证我们的本地区块链同步,并为其他工具打开服务端口 – 当然也是在容器中运行。

通过“docker run”命令,启动镜像“ethereum / client-go”。 RUN命令具有以下参数:
“-it”以交互模式启动容器,并将容器的标准输出发送到我们的终端。当以后重新启动容器时,我们可以选择在后台运行该进程,但是现在我们要看看发生了什么。
“ – -name”给容器以逻辑名“ethereum”,我们稍后可以使用它来访问这个实例。
“-p 30303:30303 -p 8545:8545 -p 8546:8546”公开并且将三个端口从容器内部映射到外部。
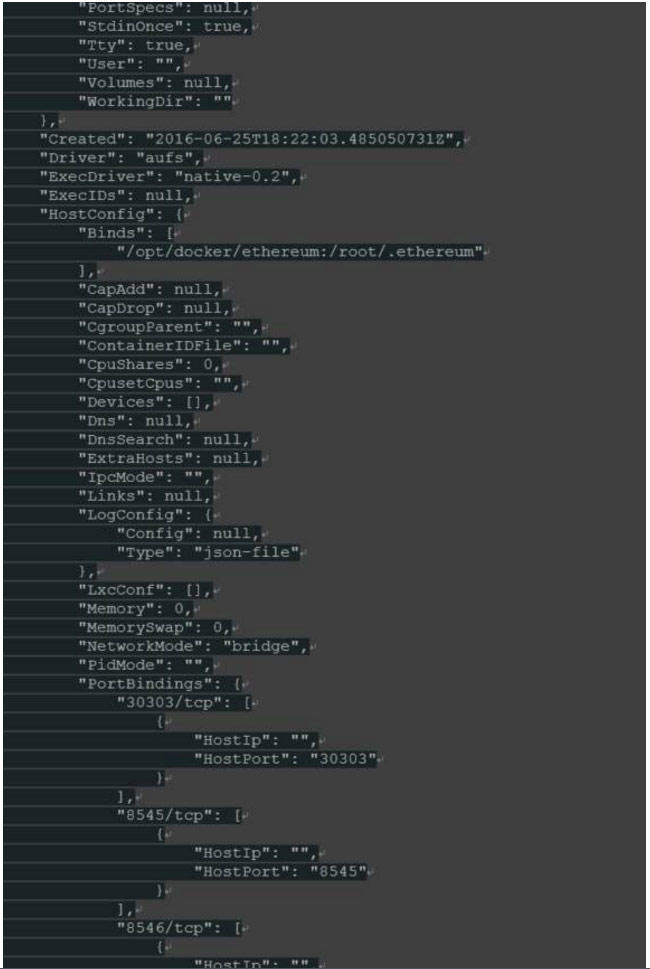
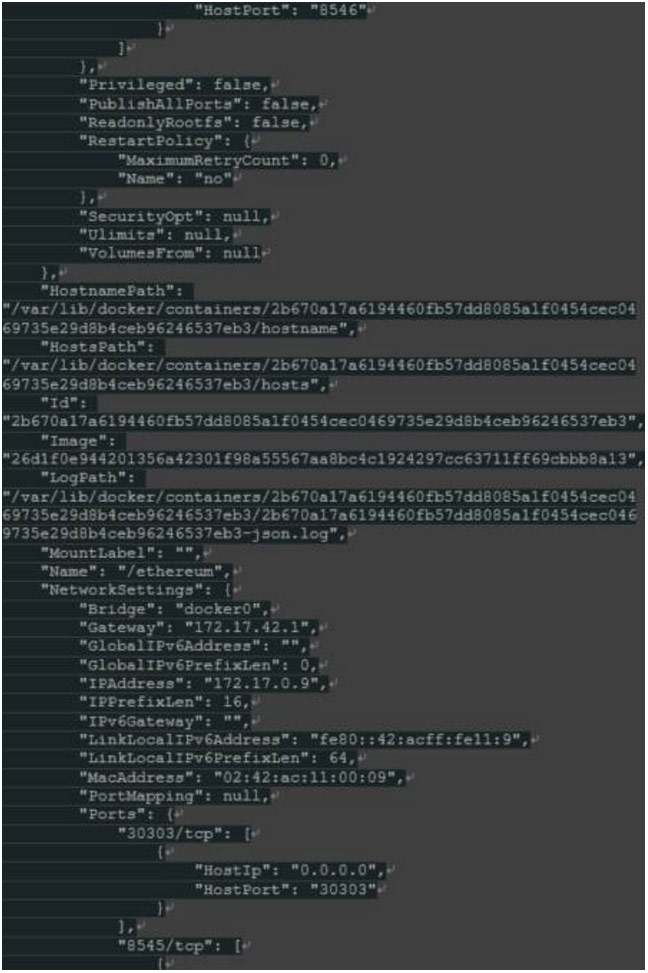
“-v /opt/docker/ethereum:/root/.ethereum”将主机目录“/ opt / docker / ethereum”(我们要存储区块链数据的位置)挂载到位置“/ root / .ethereum“。后者是“geth”在使用root用户帐户启动时存储所有信息的默认位置。
这个镜像的ENTRYPOINT命令“geth”可以通过INSPECTing可视化来调用,就像我们在主机上直接运行时使用该工具一样。请注意,容器命令行参数不能(容易)过后更改,如果需要不同的命令行,我们将需要创建一个新容器。然而从Docker的角度“容器很便宜”,所以这个约束不是真正的问题,特别是数据不在容器中,不需要重新下载。有一件事要记住:同一时间只有一个“geth”节点可以访问blockchain数据,所以不可能同时运行多个主“geth”节点。
“ – -ws – -rpc”分别激活“geth”的Web接口和HTTP RPC接口。“ – -rpcaddr”0.0.0.0“ – -wsaddr”0.0.0.0“向网络上的所有地址开放这些接口。这样做通常会有点危险,但我们不是在主机的物理网络上运行。这个部分后面会介绍更多。执行上面的命令应该启动一个新的容器,调用“geth”工具,然后开始下载blockchain数据。 (注意:您可以使用“-fast”选项)。
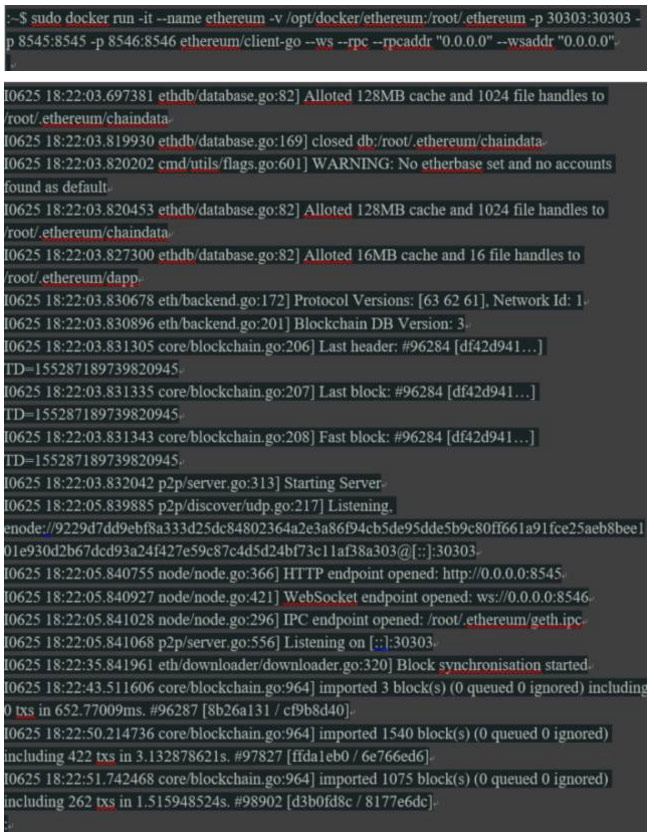
以下行值得重点关注:
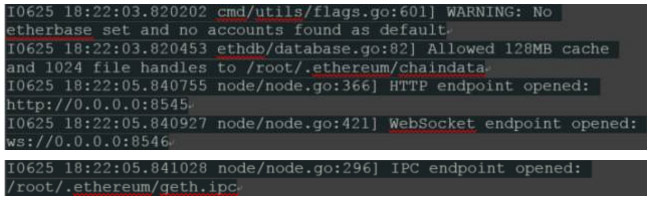
1 首先,告警提示“geth”抱怨没有定义“etherbase”。 “etherbase”是成功挖掘区块,执行智能合约并在区块链内返回结果之后用来接收以太奖励的“默认以太坊地址”。这个帐户,在开发合同时也很方便。
2 接下来,我们看到blockchain数据被写入“/root/.ethereum/chaindata”,因为我们已经从我们的主机挂载了这个目录,我们应该可以在本地磁盘上看到出现的数据:
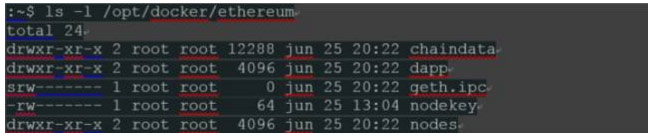
3 最后,HTTP和Web socket端点已经打开,并且创建了默认的IPC(进程间通信)文件句柄“/root/.ethereum/geth.ipc”。这通常会隐藏在容器中,但是我们已经挂载了外部目录,所以该文件可以用于与这个“geth”节点通信。
剩下的就是定义一个默认的以太坊帐户。使用Docker命令允许在正在运行的容器中执行命令,所以很容易。注意,这各操作不会打开另一个不同的容器,它连接到现在运行的容器。
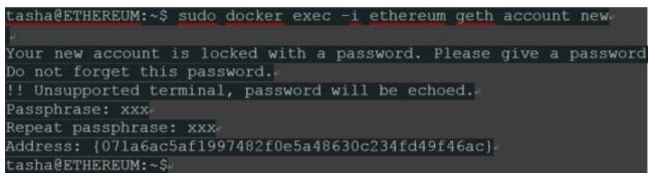
不要忘记记下以太坊地址和密码。为了被“geth”节点识别,容器必须重新启动。新帐户可以在我们挂载的数据目录中找到:

在交互式模式下,容器实例可以使用CTRL + C停止。否则,应该调用docker STOP命令。
关于这一点的最后说明:
为了能与以太坊网络同步,主机时间必须精确匹配以太网网络时间。因此,可能需要使用NTP协议与“世界时间”执行同步:
![]()
【容器相关知识】
在当前配置中,我们有一个可以挂载到我们的容器中的以太坊数据目录。这不是因为区块链数据只能在任何情况下由一个进程访问,而是访问可由Ethereum节点用于进程间通信的IPC文件描述符。因此,我们可以在这里继续,而不需要访问网络。
然而,为了充分利用我们的完整容器化以太坊节点,了解Docker如何与网络结合可以大大帮助我们为我们未来的用例找到最佳解决方案。众所周知,网络可以是相当复杂的,所以我们在这里只专注于文章内容相关的部分。
默认情况下,Docker容器无法访问主机的网络。如果这样的话,容器化有什么意义呢?作为替代,Docker创建一个单独的虚拟网络,所有容器和主机都可以访问:“docker0”。可以通过显示主机的网络配置查看:
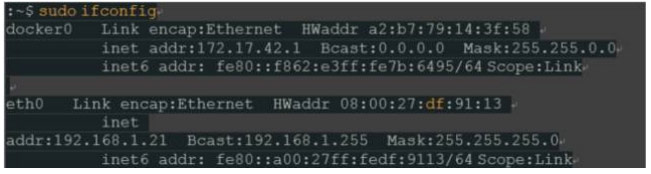
除了我们的本地网络“eth0”(或类似,NB。eth以太网,而不是以太坊),我们看到名为“docker0”的网络。它是一个不同的子网,172.17.42.1是这个网络上的主机IP地址。为了简单,我们将使用由所有容器共享的默认“docker0”网络。但是,知道Docker也允许创建单独的逻辑网络并将它们分配到特定的容器!
获取容器的IP地址不太直接。默认情况下,在轻量级Linux镜像中未安装“ifconfig”。我们可以使用命令“sudo docker exec apt-get -y install …..”安装一切,但是这个需要在每个容器中一次又一次地执行。有一个更容易的解决方案:

对于这个IP必须要清楚的事情是,它会在在容器重新启动时改变。这个对于将IP用于在创建另一个容器作为命令行参数传递时可能是一个问题,我们将在下面看到。
顺便提一句,INSPECT命令允许查看关于容器,系统和IO配置,启动命令行,文件路径和挂载等等的任何信息。
4 连接JavaScript控制台
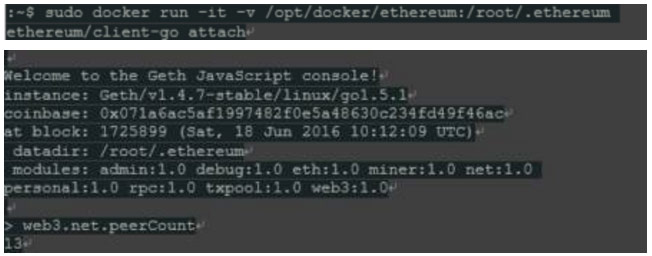
接下来,我们想让以太坊主节点与“geth”JavaScript控制台进行交互。这个十分简单…
而棘手的部分是两个容器化的“geth”节点之间的进程间通信。第一个选项是使用安装的数据目录中存在的IPC文件。这是当在同一主机上运行时“geth”节点通信的典型方式。我们需要的是将数据目录安装到第二个节点,在同一个地方,所以“geth”“看到”另一个节点,就好像它只运行一个控制台窗口。两个容器使用相同的IPC描述符进行互连:
替代方案是Web socket或HTTP接口。这需要知道主节点的IP地址,我们知道如何找出.
此方法有一个重要的障碍:我们必须指定主“geth”节点的IP地址作为第二个容器的命令行的一部分。一旦创建,此IP声明不能再更改(除了在配置文件上做手脚),所以这个容器只有在目标容器重新启动和其IP更改之前才有用。
最简单的解决方案是删除此容器,并在每次需要控制台时启动一个新容器。记住 – “容器很便宜”,我们可以用脚本自动化:
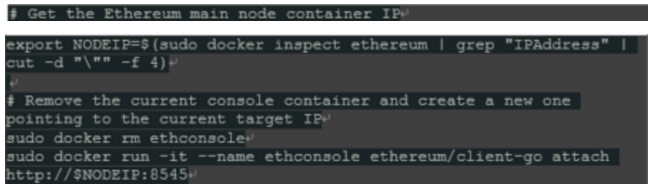
5 运行MIX IDE
现在它将要变得非常有趣。到目前为止,我们使用纯命令行“geth”实例在单独的容器中运行,我们使它们进行通信。运行Ethereum Mix IDE增加了一个新的挑战:使用图形用户界面。
Docker不是真正设计为在容器内运行UI,但是我们可以使用各种技巧来解决。目前有三种方式:
1)将整个X11服务器安装到容器中,并使用一些魔法:),如下所述。这个方式很重,但却是完全“Docker方式”让容器保持隔离。
2)简单地将VNC服务器安装到容器中并远程打开UI。很聪明,但由于性能问题用VNC工作却不是真的那么趣。
3)在正确的地方将Linux主机的X11 IPC(进程间通信)socket装入容器,这是相对优雅的,但却打破了容器之间的隔离,因此可能带来安全和稳定问题。
这个问题解决了,我们需要将Mix IDE转换为容器。由于以太坊团队尚未提供预定义的镜像,我们勇敢地使用“Dockerfile”构建自己的镜像。
第一步是创建一个目录来存储Dockerfile,让我们说“ethereum-mix-ide”。接下来,在内部创建名为“Dockerfile”的文件(文件名是必需的),其内容如下:
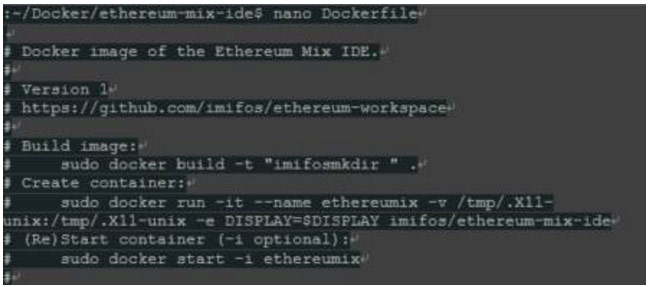
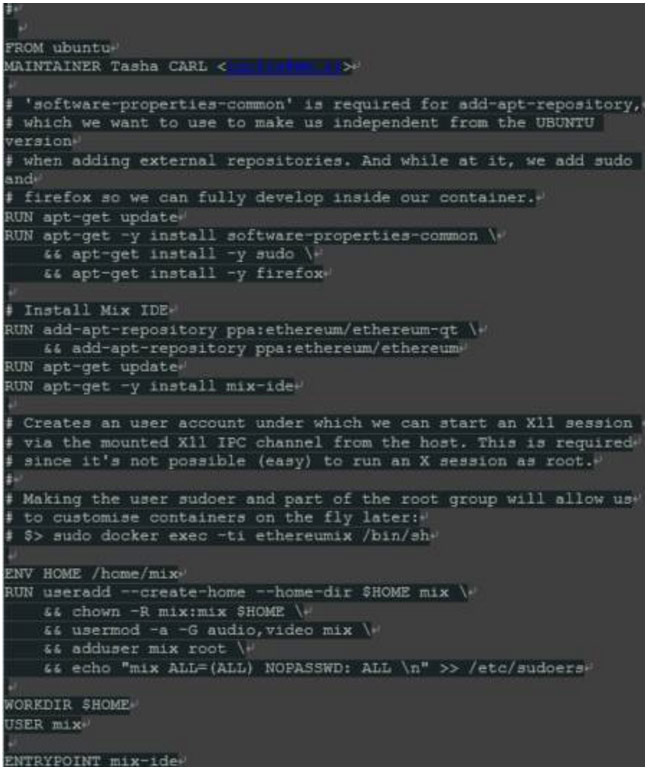
最后,在目录中,我们调用Docker命令,逐步执行此脚本,并将最终结果保存到我们的新镜像中。请不要忘记在末尾的“。”,因为它是命令行的一部分。

“Dockerfile”脚本是相当自我解释 。我们的镜像是基于最新的官方UBUNTU镜像。首先,它安装各种工具和Mix IDE。为了能够连接到X服务器,正在运行的进程不能是“root”。因此,脚本创建一个名为“mix”的用户并赋予他sudo权限。最后,“mix-ide”设置为自动启动点。
让我们来验证一下结果:

镜像准备好了,我们将创建一个新的容器,并自豪地命名为“ethereumix”
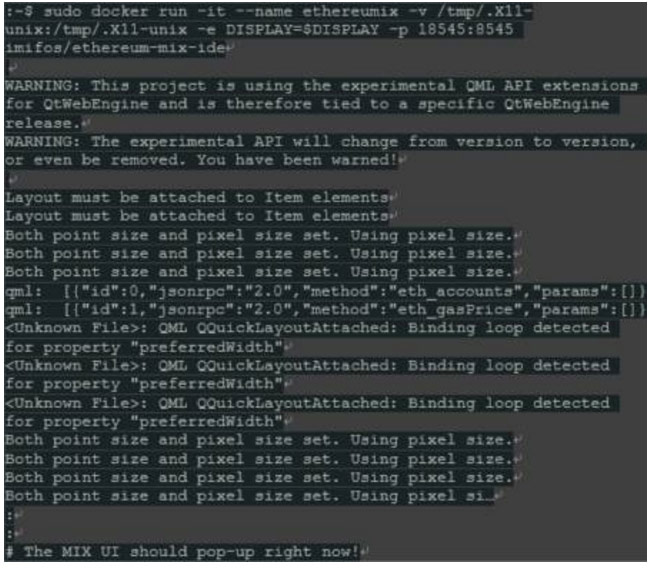
一旦构建,容器可以随时重新启动:
![]()
或者,在交互模式下查看所有Beta版的警告消息:
![]()
你可能已经注意到这个参数:“-p 18545:8545”。它确实是一个参数,没有typo :)“geth”主节点容器已经将它的端口8545绑定到主机端口8545,所以我们需要选择另一个地方绑定。由于Mix IDE容器启动到“geth”主节点的连接,因此绑定位置不重要。
“-v /tmp/.X11-unix:/tmp/.X11-unix”将我们的本地X11服务器socket挂载到容器,这次使用Docker的VOLUME功能,“-e DISPLAY = $ DISPLAY”设置$ DISPLAY环境变量在容器内的值与我们在主机上的值相同。此变量指定X客户端要显示的地址,这是必须设置的。
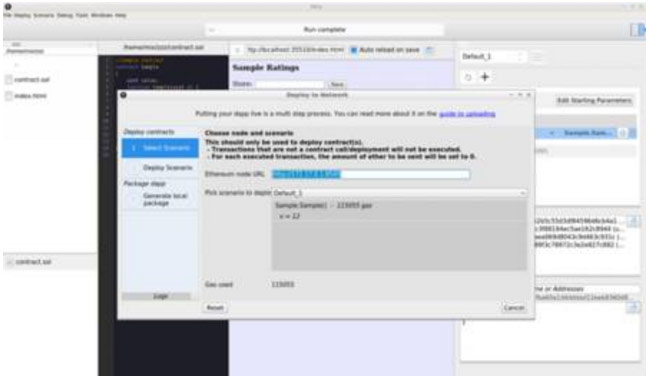
Mix IDE不需要访问Blockchain数据,但是我们需要在我们要在区块链上部署Smart Contract时联系主要的以太坊“geth”服务器节点。同样,我们需要服务器节点的IP地址:

然而,这一次,目标地址在UI中指定,并且当服务器IP更改时,容器可以重复使用而不用麻烦。
镜像创建脚本安装了使用Mix IDE所需的内容,但我们可能需要安装其他工具或稍后调整容器。正如我们上面已经看到的,我们可以在容器内执行命令,这甚至可以是一个交互式shell:
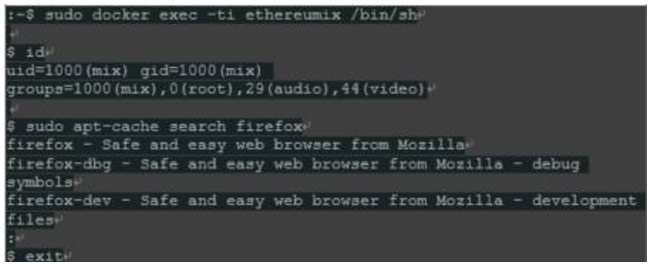
成功!
二:数据库部分
1. 常见的关系型数据库管理系统产品有?
答:Oracle、SQL Server、MySQL、Sybase、DB2、Access等。
2. SQL语言包括哪几部分?每部分都有哪些操作关键字?
答:SQL语言包括数据定义(DDL)、数据操纵(DML),数据控制(DCL)和数据查询(DQL)四个部分。
数据定义:Create Table,Alter Table,Drop Table, Craete/Drop Index等
数据操纵:Select ,insert,update,delete,
数据控制:grant,revoke
数据查询:select
3. 完整性约束包括哪些?
答:数据完整性(Data Integrity)是指数据的精确(Accuracy)和可靠性(Reliability)。
分为以下四类:
1) 实体完整性:规定表的每一行在表中是惟一的实体。
2) 域完整性:是指表中的列必须满足某种特定的数据类型约束,其中约束又包括取值范围、精度等规定。
3) 参照完整性:是指两个表的主关键字和外关键字的数据应一致,保证了表之间的数据的一致性,防止了数据丢失或无意义的数据在数据库中扩散。
4) 用户定义的完整性:不同的关系数据库系统根据其应用环境的不同,往往还需要一些特殊的约束条件。用户定义的完整性即是针对某个特定关系数据库的约束条件,它反映某一具体应用必须满足的语义要求。
与表有关的约束:包括列约束(NOT NULL(非空约束))和表约束(PRIMARY KEY、foreign key、check、UNIQUE) 。
4. 什么是事务?及其特性?
答:事务:是一系列的数据库操作,是数据库应用的基本逻辑单位。
事务特性:
(1)原子性:即不可分割性,事务要么全部被执行,要么就全部不被执行。
(2)一致性或可串性。事务的执行使得数据库从一种正确状态转换成另一种正确状态
(3)隔离性。在事务正确提交之前,不允许把该事务对数据的任何改变提供给任何其他事务,
(4) 持久性。事务正确提交后,其结果将永久保存在数据库中,即使在事务提交后有了其他故障,事务的处理结果也会得到保存。
或者这样理解:
事务就是被绑定在一起作为一个逻辑工作单元的SQL语句分组,如果任何一个语句操作失败那么整个操作就被失败,以后操作就会回滚到操作前状态,或者是上有个节点。为了确保要么执行,要么不执行,就可以使用事务。要将有组语句作为事务考虑,就需要通过ACID测试,即原子性,一致性,隔离性和持久性。
5. 什么是锁?
答:数据库是一个多用户使用的共享资源。当多个用户并发地存取数据时,在数据库中就会产生多个事务同时存取同一数据的情况。若对并发操作不加控制就可能会读取和存储不正确的数据,破坏数据库的一致性。
加锁是实现数据库并发控制的一个非常重要的技术。当事务在对某个数据对象进行操作前,先向系统发出请求,对其加锁。加锁后事务就对该数据对象有了一定的控制,在该事务释放锁之前,其他的事务不能对此数据对象进行更新操作。
基本锁类型:锁包括行级锁和表级锁
6. 什么叫视图?游标是什么?
答:视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,视图通常是有一个表或者多个表的行或列的子集。对视图的修改不影响基本表。它使得我们获取数据更容易,相比多表查询。
游标:是对查询出来的结果集作为一个单元来有效的处理。游标可以定在该单元中的特定行,从结果集的当前行检索一行或多行。可以对结果集当前行做修改。一般不使用游标,但是需要逐条处理数据的时候,游标显得十分重要。
7. 什么是存储过程?用什么来调用?
答:存储过程是一个预编译的SQL语句,优点是允许模块化的设计,就是说只需创建一次,以后在该程序中就可以调用多次。如果某次操作需要执行多次SQL,使用存储过程比单纯SQL语句执行要快。可以用一个命令对象来调用存储过程。
8. 索引的作用?和它的优点缺点是什么?
答:索引就一种特殊的查询表,数据库的搜索引擎可以利用它加速对数据的检索。它很类似与现实生活中书的目录,不需要查询整本书内容就可以找到想要的数据。索引可以是唯一的,创建索引允许指定单个列或者是多个列。缺点是它减慢了数据录入的速度,同时也增加了数据库的尺寸大小。
9. 如何通俗地理解三个范式?
答:第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解;
第二范式:2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性; 第三范式:3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。。
10. 什么是基本表?什么是视图?
答:基本表是本身独立存在的表,在 SQL 中一个关系就对应一个表。 视图是从一个或几个基本表导出的表。视图本身不独立存储在数据库中,是一个虚表
11. 试述视图的优点?
答:(1) 视图能够简化用户的操作 (2) 视图使用户能以多种角度看待同一数据; (3) 视图为数据库提供了一定程度的逻辑独立性; (4) 视图能够对机密数据提供安全保护。
12. NULL是什么意思
答:NULL这个值表示UNKNOWN(未知):它不表示“”(空字符串)。对NULL这个值的任何比较都会生产一个NULL值。您不能把任何值与一个 NULL值进行比较,并在逻辑上希望获得一个答案。
使用IS NULL来进行NULL判断
13. 主键、外键和索引的区别?
主键、外键和索引的区别
定义:
主键--唯一标识一条记录,不能有重复的,不允许为空
外键--表的外键是另一表的主键, 外键可以有重复的, 可以是空值
索引--该字段没有重复值,但可以有一个空值
作用:
主键--用来保证数据完整性
外键--用来和其他表建立联系用的
索引--是提高查询排序的速度
个数:
主键--主键只能有一个
外键--一个表可以有多个外键
索引--一个表可以有多个唯一索引
14. 你可以用什么来确保表格里的字段只接受特定范围里的值?
答:Check限制,它在数据库表格里被定义,用来限制输入该列的值。
触发器也可以被用来限制数据库表格里的字段能够接受的值,但是这种办法要求触发器在表格里被定义,这可能会在某些情况下影响到性能。
15. 说说对SQL语句优化有哪些方法?(选择几条)
(1)Where子句中:where表之间的连接必须写在其他Where条件之前,那些可以过滤掉最大数量记录的条件必须写在Where子句的末尾.HAVING最后。
(2)用EXISTS替代IN、用NOT EXISTS替代NOT IN。
(3) 避免在索引列上使用计算
(4)避免在索引列上使用IS NULL和IS NOT NULL
(5)对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
(6)应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
(7)应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描
16. SQL语句中‘相关子查询’与‘非相关子查询’有什么区别?
答:子查询:嵌套在其他查询中的查询称之。
子查询又称内部,而包含子查询的语句称之外部查询(又称主查询)。
所有的子查询可以分为两类,即相关子查询和非相关子查询
(1)非相关子查询是独立于外部查询的子查询,子查询总共执行一次,执行完毕后将值传递给外部查询。
(2)相关子查询的执行依赖于外部查询的数据,外部查询执行一行,子查询就执行一次。
故非相关子查询比相关子查询效率高
17. char和varchar的区别?
答:是一种固定长度的类型,varchar则是一种可变长度的类型,它们的区别是:
char(M)类型的数据列里,每个值都占用M个字节,如果某个长度小于M,MySQL就会在它的右边用空格字符补足.(在检索操作中那些填补出来的空格字符将被去掉)在varchar(M)类型的数据列里,每个值只占用刚好够用的字节再加上一个用来记录其长度的字节(即总长度为L+1字节).
18. Mysql 的存储引擎,myisam和innodb的区别。
答:简单的表达:
MyISAM 是非事务的存储引擎;适合用于频繁查询的应用;表锁,不会出现死锁;适合小数据,小并发
innodb是支持事务的存储引擎;合于插入和更新操作比较多的应用;设计合理的话是行锁(最大区别就在锁的级别上);适合大数据,大并发。
19. 数据表类型有哪些
答:MyISAM、InnoDB、HEAP、BOB,ARCHIVE,CSV等。
MyISAM:成熟、稳定、易于管理,快速读取。一些功能不支持(事务等),表级锁。
InnoDB:支持事务、外键等特性、数据行锁定。空间占用大,不支持全文索引等。
20. MySQL数据库作发布系统的存储,一天五万条以上的增量,预计运维三年,怎么优化?
a. 设计良好的数据库结构,允许部分数据冗余,尽量避免join查询,提高效率。
b. 选择合适的表字段数据类型和存储引擎,适当的添加索引。
c. mysql库主从读写分离。
d. 找规律分表,减少单表中的数据量提高查询速度。
e.添加缓存机制,比如memcached,apc等。
f. 不经常改动的页面,生成静态页面。
g. 书写高效率的SQL。比如 SELECT * FROM TABEL 改为 SELECT field_1, field_2, field_3 FROM TABLE.
21. 数据库的垂直拆分和水平拆分各代表什么意思?
答:
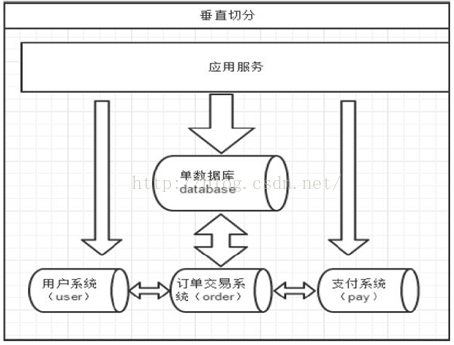
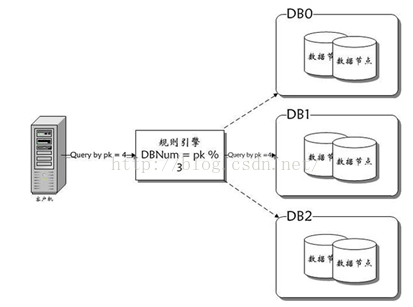
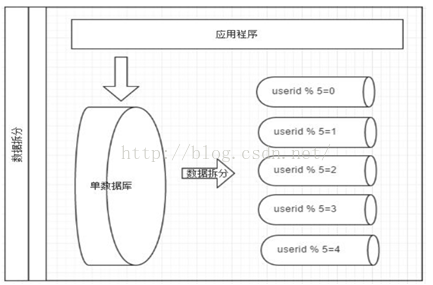
|
21. 假设给你5台服务器你如何搭建日pv300w访问的中型网站?请说说思路?
2、3台Web服务器可以结合Memcache缓存或者redis来减少负载!
3、2台mysql服务器采用Master/Slave同步的方式减轻数据库负载!
4、3台Web服务器内容一致,采用DNS进行负载均衡!