概述
beanstalk是多年前使用过的一个分布式任务队列,通过C实现,十分高效。和Redis(默认)的事件驱动框架一样,都是通过异步的epoll来实现,所以,能够高效的处理大量请求。
但不知什么原因,作者几年前已经不再维护其代码了。但我发现国内还是有一些人在使用该软件,为了能够更好的理解其运行机制,几年前对其代码进行了一些研究。先把分析的几篇发出来。
另外,我对其代码进行了fork,若有问题可以一起探讨解决之道。
beanstalk数据结构概览
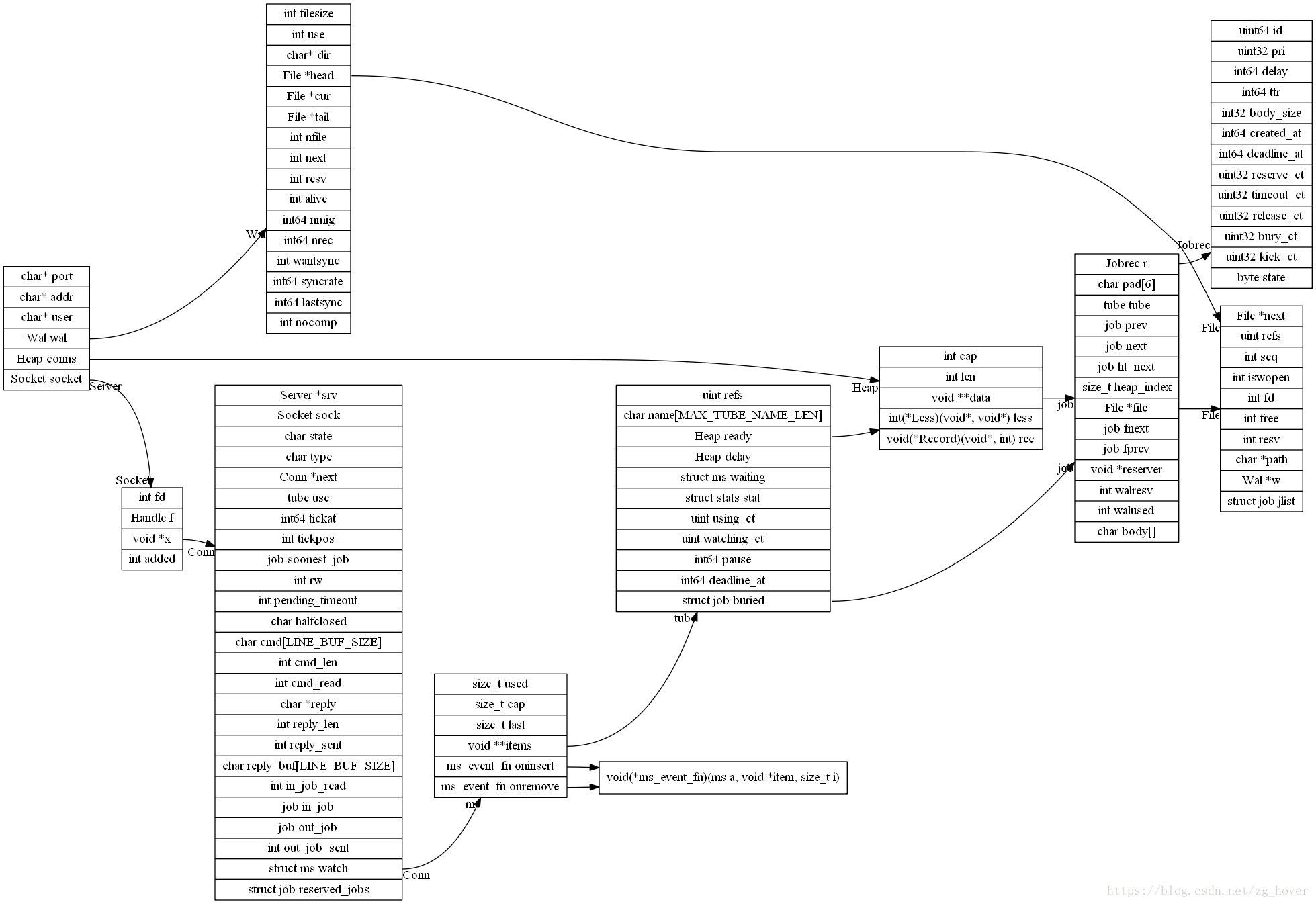
基本数据结构解析
socket结构
beanstalk 对底层socket做了一层封装,通过面向对象的思想把操作封装在一起。
struct Socket {
int fd; //监听socket fd
Handle f;
void *x;
int added;
};Handle是一个函数指针,参数是void* 和一个整数(这里是以完成三次握手的socket的fd)
typedef void(*Handle)(void*, int rw);tube结构
该结构定义一个有名的任务队列,用来存储统一类型的job,是producer和consumer操作的对象。
struct tube {
uint refs;
char name[MAX_TUBE_NAME_LEN]; //队列名字,最大长度为201个字节
Heap ready;
Heap delay;
struct ms waiting; /* set of conns */
struct stats stat;
uint using_ct;
uint watching_ct;
int64 pause;
int64 deadline_at;
struct job buried;
};// 队列名的最大长度为201个字符?作者为什么要限制到201?
#define MAX_TUBE_NAME_LEN 201- 状态信息结构
struct stats {
uint urgent_ct;
uint waiting_ct;
uint buried_ct;
uint reserved_ct;
uint pause_ct;
uint64 total_delete_ct;
uint64 total_jobs_ct;
};- ms结构定义
struct ms {
size_t used, cap, last;
void **items;
ms_event_fn oninsert, onremove;
};
typedef void(*ms_event_fn)(ms a, void *item, size_t i);- Heap(堆)结构定义
struct Heap {
int cap;
int len;
void **data;
Less less; // 函数指针,用来操作data
Record rec; // 函数指针,对data进行操作
};
typedef int(*Less)(void*, void*);
typedef void(*Record)(void*, int);job结构
该结构定义一个需要异步处理的任务,是Beanstalkd中的基本单元,需要放在一个tube中。
struct job {
Jobrec r; // persistent fields; these get written to the wal
/* bookeeping fields; these are in-memory only */
char pad[6]; // 该字段不保存任何数据,为内存对齐而使用的填充位
tube tube; //定义一个tube指针,指向该job属于的队列
job prev, next; /* linked list of jobs */ // 每个job都被保存到一个双向链表中
job ht_next; /* Next job in a hash table list */ //job还被添加到hash表中
size_t heap_index; /* where is this job in its current heap */ //该job属于哪个heap(堆)
File *file;
job fnext; //?
job fprev; //?
void *reserver;
int walresv;
int walused;
char body[]; // written separately to the wal
};- job描述结构
// if you modify this struct, you must increment Walver above
struct Jobrec {
uint64 id;
uint32 pri;
int64 delay;
int64 ttr;
int32 body_size;
int64 created_at;
int64 deadline_at;
uint32 reserve_ct;
uint32 timeout_ct;
uint32 release_ct;
uint32 bury_ct;
uint32 kick_ct;
byte state;
};- ms结构
struct ms {
size_t used, cap, last;
void **items;
ms_event_fn oninsert, onremove;
};Server结构
该结构保存服务器的一些配置信息。
struct Server {
char *port; // 服务的端口
char *addr; // 服务的绑定地址
char *user; // 服务的启动用户
Wal wal;
Socket sock; //服务的socket信息
Heap conns;
};Wal结构
struct Wal {
int filesize;
int use;
char *dir;
File *head;
File *cur;
File *tail;
int nfile;
int next;
int resv; // bytes reserved
int alive; // bytes in use
int64 nmig; // migrations
int64 nrec; // records written ever
int wantsync;
int64 syncrate;
int64 lastsync;
int nocomp; // disable binlog compaction?
};File结构
该结构维护了打开的文件和job的关系。
struct File {
File *next;
uint refs;
int seq;
int iswopen; // is open for writing
int fd;
int free;
int resv;
char *path;
Wal *w;
struct job jlist; // jobs written in this file
};连接结构Conn
struct Conn {
Server *srv; // 该Conn结构对应的Server实体指针
Socket sock;
char state;
char type;
Conn *next; // 下一个Conn的指针
tube use;
int64 tickat; // time at which to do more work
int tickpos; // position in srv->conns
job soonest_job; // memoization of the soonest job
int rw; // currently want: 'r', 'w', or 'h'
int pending_timeout;
char halfclosed;
char cmd[LINE_BUF_SIZE]; // this string is NOT NUL-terminated
int cmd_len;
int cmd_read;
char *reply;
int reply_len;
int reply_sent;
char reply_buf[LINE_BUF_SIZE]; // this string IS NUL-terminated
// How many bytes of in_job->body have been read so far. If in_job is NULL
// while in_job_read is nonzero, we are in bit bucket mode and
// in_job_read's meaning is inverted -- then it counts the bytes that
// remain to be thrown away.
int in_job_read;
job in_job; // a job to be read from the client
job out_job;
int out_job_sent;
struct ms watch;
struct job reserved_jobs; // linked list header
};总结
本文描述了beanstalk的基本数据结构,要理解系统的设计原理,首先要理解其数据结构的设计。