
==overview==
随着硬件的发展,我们可以看到GPU的计算能力远远的把CPU抛在后面,所以把更多的CPU端的计算放在GPU端,可以说是一个行业一直努力的方向。
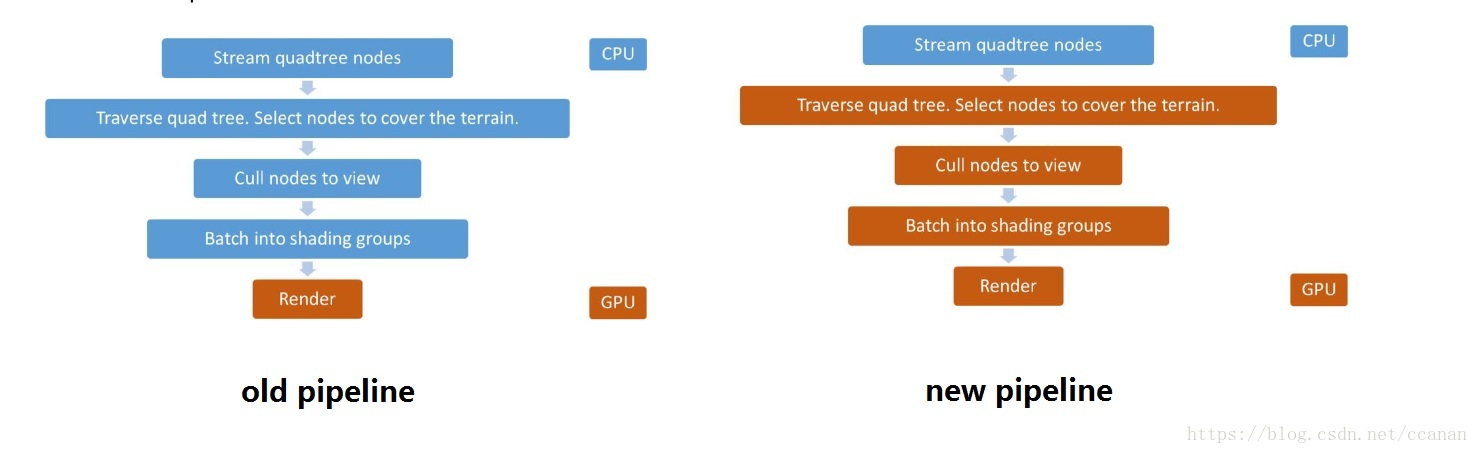
渲染端cpu上面,一直以来,剔除和提交drawcall都是cpu做的,这部分一方面cpu可怜的计算力只能做的很粗糙,一方面消耗颇高,导致国内游戏行业谈性能必谈drawcall数量。
这部分离GPU很近,所以当然要先下手了。
其实早在PS3时代,强劲的spu,一定程度上我们可以理解为是一个更通用的GPGPU,就承担了这个任务,更激进的剔除和替代cpu进行drawcall提交,都让性能在cpu有质的飞跃,gpu也同时受益。
从dx11开始,都支持渲染的对象的部分参数由GPU来生成,可以说GPGPU来做这个事情的条件就也成熟了。
整体上在性能上的收获是非常大的。
从15年的siggraph开始,ubi和EA都相继做了不少的分享:
- siggraph15, < GPU-Driven Rendering Pipelines> @ ubisoft
- gdc16, < Optimizing the Graphics Pipeline With Compute> @ EA
- gdc18, TerrainRenderingFarCry5 @ ubisoft
- …
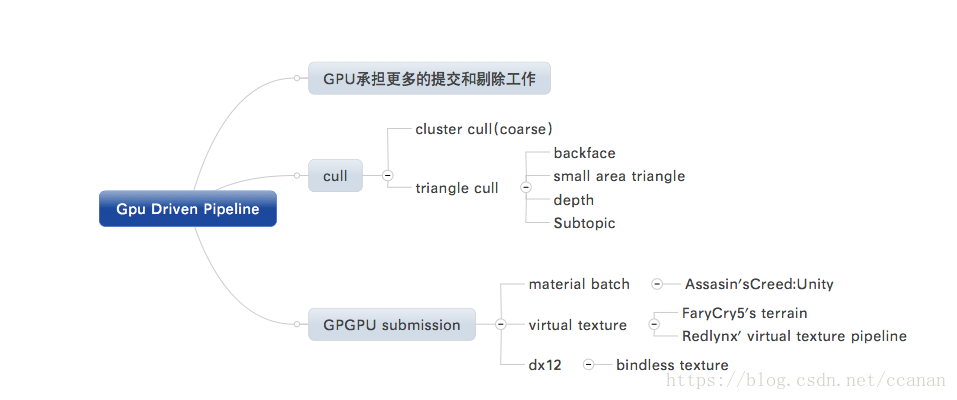
总的看来,GPU driven pipeline是有两个部分:
- 剔除–不只是offload了cpu的工作,进一步在gpu上做更aggressive的cull
- 提交–目标是一个drawcall结束战斗,根据实际情况进行折中了
==剔除==
这部分是通过gpgpu来先对要渲染的object进行剔除,这里ubi和ea都分成两个level来做,cluster和triangle
=cluster level cull=

把mesh分成固定的一些cluster,比如6400 vertices就分成100个cluster,每个cluster 64vertices,然后进行bound和orientation的cull。
=triangle level cull=
这里的backface,small area triangle都是老生常谈。
depth buffer这个,可以
- 在pc上使用cpu software rasterizer
- depth prepass, 然后downsample
- 使用上一帧的depth buffer做一个reprojection
使用其中的1个或几个组合。
==提交==
这里普遍的遇到项目老代码的问题,如果是dx12或者基于virtual texture的项目会简单些。
简单讲,就是要绑定的资源如果非常不同,还是难以硬放在一起来渲染。
这里< assassin’s creed:unity >就是没法改的彻底,所以还是依据material来batch,那么可以说gpu driven的就相当不彻底。
而redlynx,pipeline是有比较重的virtual texture,farcry5的地形有virtual texture,那么资源就不需要改变绑定,那么就可以一个drawcall搞定一切,达到一个更彻底的gpu driven的程度。
dx12对此有更好的支持,可以更彻底的gpu driven了。
==效率对比==
- 刺客信条,应该说几个paper里面受益最少的,但也非常的可观
- cpu 比前一座,10x的obj,但是cpu却快了25%
- gpu也少渲染了20%到80%的triangle
farcry5
- gpu把quadtree traverse到lod map以及各种cull,0.1ms搞定。。。比cpu真是绝对优势