一丧“为了情人节和你出去,我有了好几十万自行车的使用权”
我们先来说我们为什么使用这个进程池。
目的:可以节约大量的时间。
既然这么重要,那我们都应该使用什么方法去调用方法呢?
我们来看一下
Pool方法
pool是什么?pool就是我们的进程池了,让我们来看一下怎么用这个方法
import multiprocessing#导入进程包
import os,time#这两个包的作用皆为更好的体现出我们的进程
def copy(index):
print("当前进程编号",os.getpid())
print(index)
time.sleep(1)#打一个时间差,更容易看出其效果
if __name__ == '__main__':
pool = multiprocessing.Pool(3)#导入进程池,括号内为最大进程数
for i in range(10):
pool.apply_async(copy,(i,))
pool.close()
pool.join()Pool的括号内为进程池的容量,就是子进程的最大开启数量。
我们来看一下输出吧
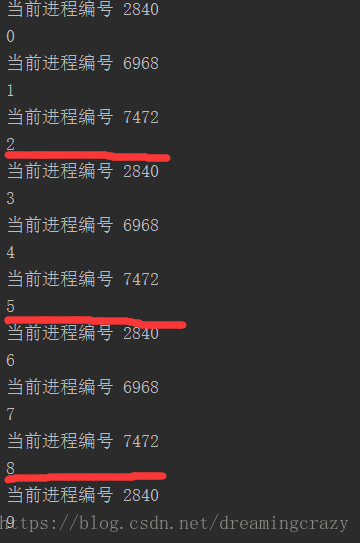
怎么样,是不是一目了然,我的池容量为3,所以进程就是三个为一组的运行
不过笔者认为进程池中比较难懂的地方在于apply_async,所以我们就来好好地探讨一下
apply_async
先看官方是怎么描述的。
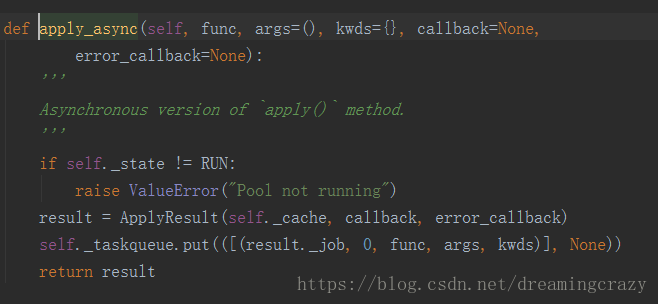
我们可以看到,官方定义为这是一个异步非阻塞式的方法。
在笔者的理解就是简单的将函数放入进程池。
那么它与阻塞式的差别在哪里呢?
apply(阻塞式):首先主进程开始运行,碰到子进程,操作系统切换到子进程,等待子进程运行结束后,在切换到另外一个子进程,直到所有子进程运行完毕。然后在切换到主进程,运行剩余的部分。
apply_async(异步非阻塞式):首先主进程开始运行,碰到子进程后,主进程说:让我先运行个够,等到操作系统进行进程切换的时候,在交给子进程运行。
因为我们的主进程过短,所以,我们子进程还没有完成程序就因主程序结束而结束,所以我们要使用join,提醒主进程在子进程结束后结束。
因为异步非阻塞是主进程和进程池中的子进程同时运行,所以耗时较短
而apply_async的()中都写什么呢?在上图您应该注意到了:
“func” = 函数名
“args = ()” = 数组
“kwds = {}” = 字典
“callback = None” = 返回值
“error_callback = None” = 返回错误信息