消息认证——安全散列算法SHA(Secure Hash Algorithm)
一. 消息认证
对要传递的消息进行加密有两个目的,其一是防止消息被消息发送者和消息接收者之外的第三者窃听(被动攻击),在之前文章中列举了一系列的对称加密算法(DES、AES、RC4等)都已经满足这一点目标;而加密的另一个目的就是防止消息被伪造(主动攻击)。
伪造消息的意思是指第三者已经获取到消息传递的规则,并假装自己是消息发送者,向消息接收者发送经过篡改或捏造的假消息,而消息接收者在不知情的情况下误以为这些假消息是来自合法的发送者。为了防止消息被伪造,我们就需要对被发送的消息进行“签名”认证。这种对消息的签名在密码学上称之为消息认证码MAC(Message Authentication Code)。
消息认证需要满足以下三点目标:
- 接收者能够确认消息没有被篡改;
- 接收者能够确保消息来自合法的发送者;
- 如果消息中包含序列号,那么攻击者不能修改序列号,接收者可以确认消息的正确序列。
二. 散列函数
2.1 散列函数介绍
散列函数的目的是为文件、消息或其他数据块产生“指纹”,为满足在消息认证中的应用,散列函数H必须具有下列性质:
- H可适用于任意长度的数据块(输入长度可变);
- H能产生固定长度的输出(输出长度固定);
- 对于任意给定的x,计算H(x)相对容易,且可以用软/硬件方式实现;
- 对于任意给定的输出h,找到满足 的输入x在计算上不可行。这一特性称为单向性,或抗原像攻击性;
- 对于任意给定的输入x,找到满足 的 在计算上是不可行的。这一特性称为抗第二原像攻击性,或抗若碰撞攻击性(weak collision resistant);
- 找到满足 的任意一对 在计算上是不可行的。这一特性称为抗碰撞性,或抗强碰撞性(strong collision resistant)。
前三个性质是使用散列函数进行消息认证的实际可行要求。第四个性质,抗原像攻击(单向性),使得给定消息容易产生它的散列码,但给定散列码几乎不可能恢复出消息。如果认证技术中使用了消息+密钥作为输入,那么单向性就变得非常重要了。假如散列函数不是单向的,而攻击者能够获得消息M以及对消息M+密钥K的散列码 ,攻击者对散列函数取逆得到 ,这时攻击者同时拥有消息M和消息+密钥(M+K),所以他可以轻而易举地恢复密钥K。
第五个性质,抗弱碰撞性,保证了对于给定的消息,不可能找到具有相同散列值的可替换消息,利用加密的散列码可防止消息被伪造。如果散列函数不具有该特性,那么接活消息及加密的消息散列码的攻击者,可以根据消息产生没被加密的散列码,然后生成具有相同散列码的伪造消息来替换原消息。
满足上述五个性质的散列函数称为弱散列函数,散列码长度为 n 的散列函数强度为 。如果还满足第六个性质则称为强散列函数。第六个性质可以防止像生日攻击这种类型的复杂攻击。这种攻击把散列码长度为 n 的散列函数强度降为 。
| 特性 | 攻击代价 |
|---|---|
| 抗原像 | |
| 抗弱碰撞 | |
| 抗强碰撞 |
表 2.1 散列值长度为n的散列函数强度
2.2 简单散列函数
所有散列函数都按照这种普通原理操作:将输入(消息、文件等)看成长度为n比特的数据块序列,对输入用迭代方式每次处理一块,最终生成n比特长度的散列码。
一种最简单的散列函数就是将输入的每一个数据块都按比特异或。表达式如下:
其中i为最终散列码的第i比特,1…m表示第几个数据块。
这种操作为输入的每一比特位置产生简单的奇偶校验,这种校验对于随机数据相当有效,数据查错却不改变散列值的几率为 。但如果数据是可预测格式化的,那么校验有效性将变差。比如普通的文本中,每个字节(8比特)的最高阶总是0,因此如果采用128比特的散列值,该散列值的校验有效概率变为 ,而不是 。
对上面的方案进行改进的一种简单方法是在每个数据块处理后,对散列循环移位或旋转固定比特位数,来消除输入数据的可预测格式。
虽然上述方案提供了一个数据完整性方法,但别忘了,这种简单的异或操作完全不具有上一节所述的散列函数第五个特性——抗弱碰撞性。对于一个消息x的异或散列值, ,总是能轻而易举地找到一个在原消息上追加、混淆、甚至与原消息毫无相干的伪造消息y,来使得 。那么这样产生的散列值,对于消息的签名认证就毫无意义。
三. 安全散列函数SHA算法族
3.1 SHA介绍
近些年,应用最为广泛的散列函数是安全散列算法(SHA)。有意思的是,由于其他每一种被广泛应用的散列函数都已被证实存在着密码分析学上的缺陷,截止到目前,SHA或许是最后仅存的标准散列算法。
SHA由美国国家标准与技术研究所(NIST)开发,生成160比特长度的散列值,并于1993年公布成为美国联邦信息处理标准。2002年,NIST公布了三种新版本的SHA:SHA-256、SHA-384、SHA-512,散列长度分别为256、384和512,三者并称SHA-2。
2005年,NIST宣布计划到2010年不再认可SHA-1,转为信任SHA-2。此后不久,有研究团队描述了一种攻击方法,该方法可以只用 次操作找到产生相同的SHA-1散列值的两条独立消息,远少于SHA-1碰撞理论所需的 次。之后,我国的王小云教授等人又提出一种新的攻击,是的碰撞复杂度再次降到 ,这些结果迫使NIST在2006年宣布2010年后不再推荐使用SHA-1。而Google于2017年公布并开源了在当前计算能力下对SHA-1的碰撞攻击算法,并在自家实验室完成了真实世界中的第一次碰撞攻击,他们通过GPU加速碰撞,创造了两个SHA-1完全相同的PDF文件,彻底将SHA-1逼入死胡同,当然,这些都是题外话。
| 算法 | SHA-1 | SHA-256 | SHA-384 | SHA-512 |
|---|---|---|---|---|
| 消息摘要大小 | 160 | 256 | 384 | 512 |
| 消息大小 | ||||
| 消息块大小 | 512 | 512 | 1024 | 1024 |
| 字大小 | 32 | 32 | 64 | 64 |
| 步骤数 | 80 | 64 | 80 | 80 |
| 安全强度(理论值) |
表 3.1 SHA各算法参数比较
3.2 SHA-512
这一节将对SHA-512进行详细介绍,该算法以最大长度不超过 位的消息作为输入,将输入以1024位的数据块进行处理,生成512位的消息摘要散列值。处理过程包括以下步骤。
3.2.1 SHA-512 算法步骤
第1步:追加填充比特。填充消息使其长度模1024余896 [ ]。即使消息已经是期望的长度,也总是要填充,因此填充比特的范围是1~1024,填充部分是由单个比特1后接所需个数的比特0构成。
第2步:追加长度。将128比特的含有原始消息长度信息的无符号整数追加在消息后面。这一步后,消息长度为1024比特的整数倍。
第3步:初始化散列缓冲区。用512比特的缓冲区保存散列函数中间和最终结果。缓冲区可以是8个64比特的寄存器(a、b、c、d、e、f、g、h),这些寄存器初始化为64比特的整数,这些值取自前8个质数的平方根小数部分的前64比特。

图 3.1 缓冲区寄存器初始值
第4步: 处理1024比特的数据块消息。算法的核心是80轮迭代构成的模块。每一轮都以512比特的换冲区值 abcdefgh 作为输入,并且更新缓冲区内容。处理第 i 个消息块 时,初始轮的输入端,缓存中间散列值为 ,任意第 t 轮,从1024比特的消息块 中获取64比特的轮子消息 ,每一轮嗨使用外加常数 ,这些常数来自于前80个质数立方根小数部分的前64比特,用来随机化消息,消除输入数据中的任何规则性。第80轮输出加到初始轮输入 上,生成 。
第5步:输出。当所有N个1024比特数据块都处理完毕后,最终缓冲区寄存器中的值便是512比特的消息摘要散列值。
整个过程的步骤如图3.2 所示,其中最核心的第4步对单个数据块的轮处理步骤在图中标记为F。
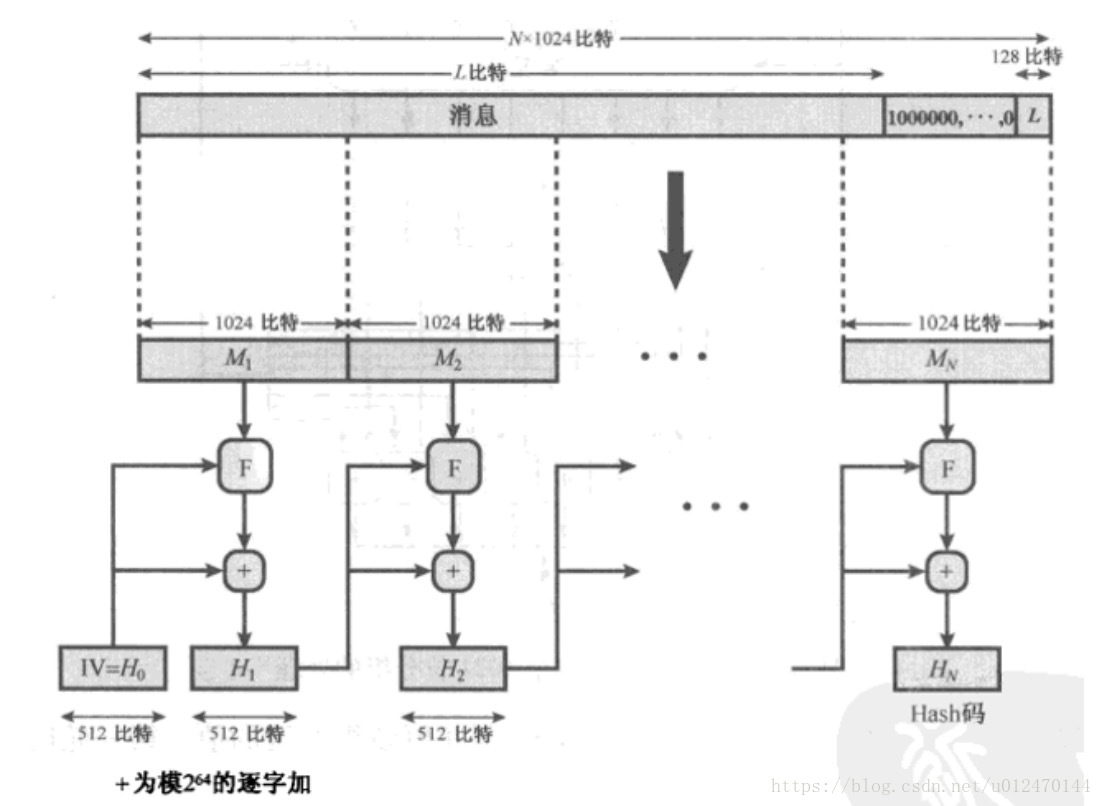
图 3.2 SHA-512 生成消息摘要过程图
3.2.2 SHA-512 数据块处理步骤详解
第4步对数据块的轮处理过程较为复杂,这一小节再单独详细描述一下。对于每个待处理的消息数据块 ,执行以下处理步骤。
- 用1024比特的数据块生成每轮处理所需的64比特的轮子数据分组,一共80个(
)。前16个数据分组
~
直接取自数据块(1024=64*16),剩余分组使用以下方式产生:
其中 为对64比特变量 x 做循环右移 n 位的操作,+ 为模 位加。
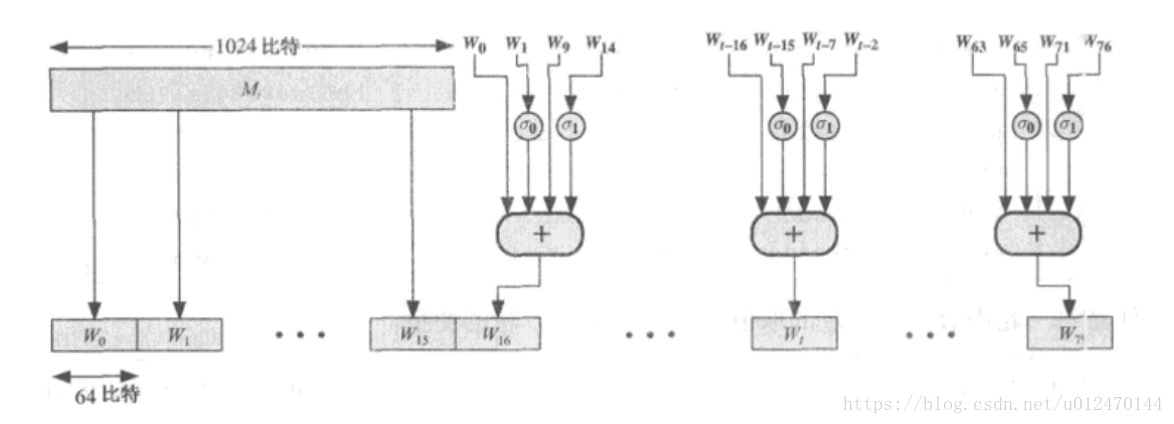
图 3.3 数据块轮处理分组的产生过程
获取每轮处理所需的64比特外加常数,一共80个( ),由上节所述方式获取,取自前80个质数的立方根小数部分的前64比特。
单轮处理,具体轮处理过程如图3.4所示。
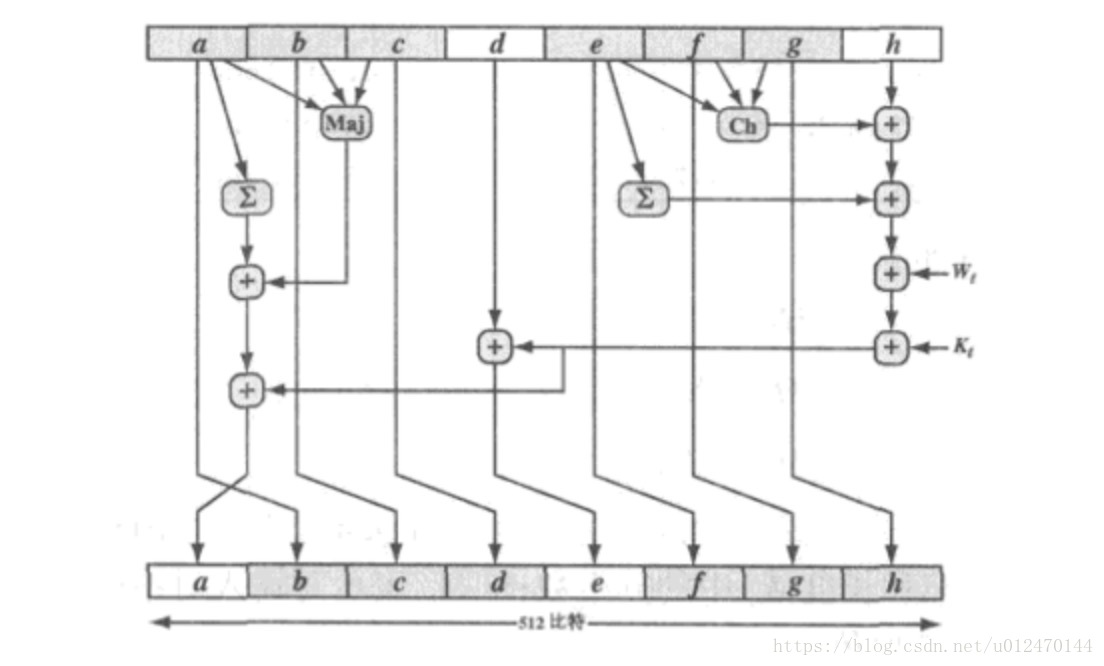
图 3.4 基本的SHA-512单轮处理过程
从图中可以看出,轮函数输出的8个字中,有6个是通过简单的轮置换获得的(图中阴影部分的 ),剩余的两个字 a 和 e 则通过替换操作产生。
字 e 是将输入变量
以及轮常数
和轮分组
作为输入的函数输出。字 a 则是将除 d 之外的输入变量以及轮常数
和轮分组
作为输入的函数输出。这两个字的产生方法解释如下:
其中,式3.5中的条件位运算函数意义为如果e,则f,否则g;式2、6中的条件位运算函数意义为当且仅当变量的多数(2个或者3个)为真时函数为真;+ 运算与上节一样,为模 位加。
- 循环单轮处理80次,最后的输出与初始轮输入做加运算即为本数据块处理后的输出。
3.2.4 SHA-512算法总结
SHA-512算法使得散列码的任意比特都受到输入端每1比特的影响,基本函数F的复杂迭代产生了非常好的混淆效果,即随机选取两组即使很相似的规则性消息也不可能产生相同的散列码。除非SHA-512中存在目前未公开的隐藏缺陷,找到两个具有相同摘要的消息的复杂度需要 次操作,给定摘要寻找消息的复杂度需要 次操作。这在当前软硬件计算能力水平,理论上是不可攻破的。