这里重点说一下SHA1算法的实现步骤与代码,由于本人水平有限,不过多讨论SHA1的数学原理以及应用场景。
SHA1简介
In cryptography, SHA-1 (Secure Hash Algorithm 1) is a cryptographic hash function which takes an input and produces a 160-bit (20-byte) hash value known as a message digest - typically rendered as a hexadecimal number, 40 digits long. It was designed by the United States National Security Agency, and is a U.S. Federal Information Processing Standard.
对于长度小于 位的消息,SHA1会产生一个160位的消息摘要。当接收到消息的时候,这个消息摘要可以用来验证数据的完整性。在传输的过程中,数据很可能会发生变化,那么这时候就会产生不同的消息摘要.
以上是维基百科和百度百科对SHA1的解释,安全哈希算法,也就是说任意一段字节,用SHA1算法跑一下,都可以生成不一样的20个字节序列。但是会有 的机率产生相同的字节序列(消息摘要),这个一般可以忽略。
SHA1应用
- 文件指纹 :这个作用和MD5的作用类似,如果文件被篡改,那么对应的SHA1值就会变化
- Git中标识对象 :用过Git的应该都知道,Git中的对象没有名字,唯一标识就是对象的SHA1值
SHA1实现步骤
实现步骤就是下面四个,一一来说下。
- 分组
- 补位
- 转大端模式
- 散列
- 输出
分组
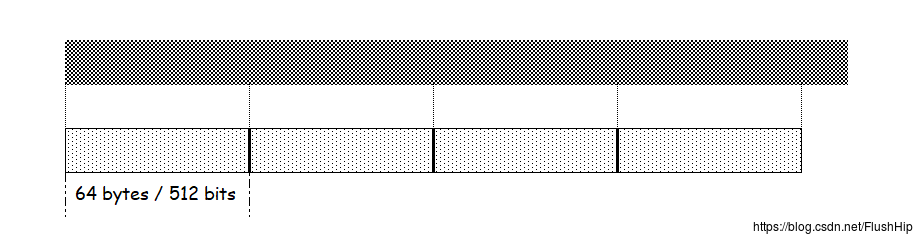
SHA1对一段字节序列进行散列,散列是分组进行的,512bits为一组,这是官方说法,实际上,计算机中最小的处理单元是按字节来处理的,即使你的消息只需要一个比特位就能表示,在计算机中也是存储为一个字节。
因此,这里我们以字节为单位,64个字节一组,我们做的散列操作就是以分组为单位进行的,把所有分组的散列结果累积起来就是SHA1的结果。
补位
64个字节一组,肯定有些字节序列的数量不是64的倍数,那么剩下的这些字节单独一组,余下的空位补一个比特位1,设下的比特位全部填0而且,最后要留八个字节表示字节序列总的比特位数。补位这个操作是一定进行的,如果补位后发现没有八个字节的位置来表示字节序列的比特位数,那么就要新加一个分组,继续补位。看下图就明白了。
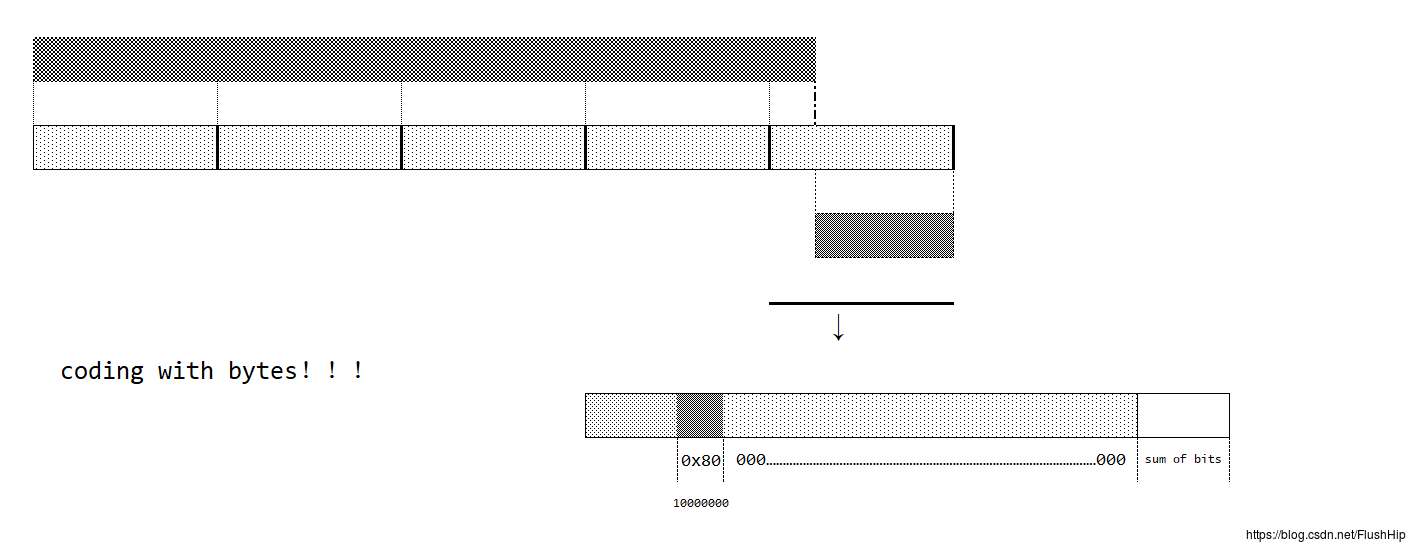
注意,在编程中,不会出现比特位的操作,都是以字节(补位以字节为单位来操作)或者四个字节(uint32_t)(散列是以uint32_t为单位)来操作的,因此补位第一个补一个0x80字节,后面的都补0x00。只有sum of bits是用来表示总共有多少比特位的。
转大端模式
补位完之后,每一个分组有64个字节,但是散列是以uint32_t为单位,因此又要4个字节为一组组成uint32_t,那么总共就有16个uint32_t,这些uint32_t要是大端模式。
散列
散列出来的结果为20个字节,也就是5个uint32_t,每一个分组的散列值用uint32_t h[]表示。初始时会赋值一些常量,这个代码中会有看到。分组的序列用uint32_t data[16]表示。
由于这里不牵扯到数学原理的说明,所以就直接说步骤了。
准备五个变量uint32_t A, B, C, D, E、一个数组uint32_t W[80];
A, B, C, D, E分别等于h[0 ~ 4];W[0 ~ 15]分别等于data[0 ~ 15],W[16 ~ 79]用一个公式Expand来计算;- 用
W[0 ~ 79]的值分别利用公式Round散列A, B, C, D, E,总共执行80次; - 最后
h[0 ~ 4]分别等于A, B, C, D, E。
至于这里面用的公式,以及为什么要这么做,我不知道,这肯定有一些数学的原因,对于编码实现SHA1来说不需要了解了。
输出
最后得到h[0 ~ 4]就是最终的结果,我们把uint32_t又转化成字节数组unsigned char digest[20],最后输出digest的16进制表示,也就是说最后会得到40个字符的字符串,你可以把这个字符串看成一个超大的整数。
C++编码实现SHA1
编码过程中还是有一些小技巧。
这是我在编码过程中的TaskList顺序图,也是按照上面实现步骤一步一步实现的。
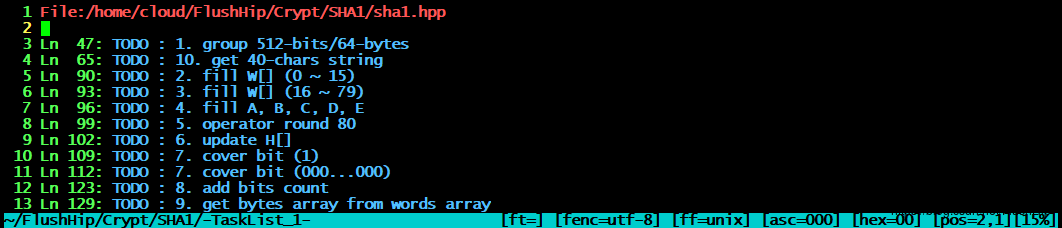
SHA1Digest
先来看看这个类的定义:
class SHA1Digest
{
public:
SHA1Digest();
SHA1Digest(const void *input, size_t length);
void Update(const void *input, size_t length);
const unsigned char *DigestText()
std::string GetString(bool isUpcase = true)
size_t GetSize()
void Reset()
private:
SHA1Digest(const SHA1Digest &) = delete;
SHA1Digest & operator = (const SHA1Digest &) = delete;
void Transform()
void Final()
void InitH()
private:
uint32_t _h[SHA1_RESULT_UINT32];
uint32_t _data[SHA1_BLOB_UINT32];
uint32_t _countLow;
uint32_t _countHight;
uint32_t _byteCount;
unsigned char _digest[SHA1_RESULT_UINT8];
private:
static uint32_t H_INIT[SHA1_RESULT_UINT32];
static uint32_t K[SHA1_ROUND_CNT];
static std::function<uint32_t(uint32_t, uint32_t, uint32_t)> F[SHA1_ROUND_CNT];
static uint32_t S(uint32_t x, int n);
static uint32_t Expand(uint32_t W[], int i);
static void Round(uint32_t alpha[], uint32_t W[], int i);
public:
static std::string BytesToHex(const unsigned char *input, size_t length, bool isUpcase);
static void BytesReverse(uint32_t data[], size_t length);
};
接口的设计参考了Python的hashlib还有poco库。内部有一缓冲区,作用可以参见Base64编解码及其C++实现;
宏定义
#define SHA1_RESULT_BIT 160
#define SHA1_RESULT_UINT8 (SHA1_RESULT_BIT / 8) // 20
#define SHA1_RESULT_UINT32 (SHA1_RESULT_UINT8 / 4) // 5
#define SHA1_BLOB_BIT 512
#define SHA1_BLOB_UINT8 (SHA1_BLOB_BIT / 8) // 64
#define SHA1_BLOB_UINT32 (SHA1_BLOB_UINT8 / 4) // 16
#define SHA1_REST_BIT 448
#define SHA1_REST_UINT8 (SHA1_REST_BIT / 8) // 56
#define SHA1_REST_UINT32 (SHA1_REST_UINT8 / 4) // 14
#define SHA1_OPERATION_CNT 80
#define SHA1_ROUND_CNT 4
#define SHA1_ROUND_LEN (SHA1_OPERATION_CNT / SHA1_ROUND_CNT) // 20
这里要好好体会下每个宏,因为这些宏体现的是操作的基本单位。
公共的静态函数
std::string SHA1Digest::BytesToHex(const unsigned char *input, size_t length, bool isUpcase)
{
static const char *digitUpper = "0123456789ABCDEF";
static const char *digitLower = "0123456789abcdef";
const char *pstr = isUpcase ? digitUpper : digitLower;
std::string ret;
ret.reserve(length << 1);
for (unsigned int i = 0; i < length; ++i)
{
ret.push_back(pstr[(input[i] & 0xF0) >> 4]);
ret.push_back(pstr[input[i] & 0x0F]);
}
return ret;
}
void SHA1Digest::BytesReverse(uint32_t data[], size_t length)
{
static unsigned int bitsOfByte= 8;
for (unsigned int i = 0; i < length; ++i)
{
data[i] = ((data[i] >> (0 * bitsOfByte) & 0xFF) << (3 * bitsOfByte)) |
((data[i] >> (1 * bitsOfByte) & 0xFF) << (2 * bitsOfByte)) |
((data[i] >> (2 * bitsOfByte) & 0xFF) << (1 * bitsOfByte)) |
((data[i] >> (3 * bitsOfByte) & 0xFF) << (0 * bitsOfByte));
}
}
这两个函数分别用来把字节转成16进制字符串与大端模式的转化。
私有的静态成员
uint32_t SHA1Digest::H_INIT[SHA1_RESULT_UINT32] =
{
0x67452301,
0xEFCDAB89,
0x98BADCFE,
0x10325476,
0xC3D2E1F0
};
uint32_t SHA1Digest::K[SHA1_ROUND_CNT] =
{
0x5A827999,
0x6ED9EBA1,
0x8F1BBCDC,
0xCA62C1D6
};
std::function<uint32_t(uint32_t, uint32_t, uint32_t)> SHA1Digest::F[SHA1_ROUND_CNT] =
{
[] (uint32_t x, uint32_t y, uint32_t z) -> uint32_t
{
return (x & y) | (~x & z);
},
[] (uint32_t x, uint32_t y, uint32_t z) -> uint32_t
{
return x ^ y ^ z;
},
[] (uint32_t x, uint32_t y, uint32_t z) -> uint32_t
{
return (x & y) | (x & z) | (y & z);
},
[] (uint32_t x, uint32_t y, uint32_t z) -> uint32_t
{
return x ^ y ^ z;
},
};
uint32_t SHA1Digest::S(uint32_t x, int n)
{
return (x << n) | (x >> (32 - n));
}
uint32_t SHA1Digest::Expand(uint32_t W[], int i)
{
return S((W[i - 3] ^ W[i - 8] ^ W[i - 14] ^ W[i - 16]), 1);
}
void SHA1Digest::Round(uint32_t alpha[], uint32_t W[], int i)
{
uint32_t & A = alpha[0];
uint32_t & B = alpha[1];
uint32_t & C = alpha[2];
uint32_t & D = alpha[3];
uint32_t & E = alpha[4];
uint32_t tmp = S(A, 5) + F[i / SHA1_ROUND_LEN](B, C, D) + E + W[i] + K[i / SHA1_ROUND_LEN];
E = D;
D = C;
C = S(B, 30);
B = A;
A = tmp;
}
这是算法的常量和公式,如果以后改成SHA2算法时,只需要把这些常量和公式换掉。
Update成员函数
这是散列的开始,分组也在这里进行;
可以把一段字节序列分开多次调用Update函数,效果和对这一段字符序列单独调用Update结果是一样的。
void Update(const void *input, size_t length)
{
const unsigned char *buff = reinterpret_cast<const unsigned char *>(input);
if (_countLow + (length << 3) < _countLow)
{
++_countHight;
}
_countLow += length << 3;
_countHight += length >> 29;
while (length--)
{
reinterpret_cast<unsigned char *>(&_data[0])[_byteCount++] = *buff++;
if (_byteCount == SHA1_BLOB_UINT8)
{
// TODO : 1. group 512-bits/64-bytes
BytesReverse(_data, SHA1_BLOB_UINT32);
Transform();
_byteCount = 0;
}
}
}
用_countLow和_countHight一起来表示一个uint64_t的数据。这里的处理单位是bit,而length是字节长度,转化成bit就是lenth << 3;
处理进位if (_countLow + (length << 3) < _countLow) { ++_countHight; },这个判断在数学上等于(length << 3) < 0,但是在计算机中,这样写可以判断是否溢出,由于处理的都是无符号的int,溢出了就相当于对
取模,如果一个数加上正数x反而这个数还小了,如果没溢出,这是不可能的;那么有没有可能计算的结果溢出了,而_countLow + (length << 3) >= _countLow,这是不可能的,除非
,而uint32_t的最大值为
;
_countHight += length >> 29;这里移位29是因为,length << 3来表示总共有多少位,然后(length << 3) >> 32表示进位是多少,对于无符号正数来说,先左移3位再右移32位相当于直接右移29位。
Final成员函数
对应着补位操作。
void Final()
{
static unsigned int bitsOfByte = 8;
// TODO : 7. cover bit (1)
reinterpret_cast<unsigned char *>(&_data[0])[_byteCount++] = 0x80;
// TODO : 7. cover bit (000...000)
std::memset(reinterpret_cast<unsigned char *>(&_data[0]) + _byteCount, 0, SHA1_BLOB_UINT8 - _byteCount);
if (_byteCount > SHA1_REST_UINT8)
{
BytesReverse(_data, SHA1_BLOB_UINT32);
Transform();
std::memset(_data, 0, sizeof(_data));
}
BytesReverse(_data, SHA1_BLOB_UINT32);
// TODO : 8. add bits count
_data[14] = _countHight;
_data[15] = _countLow;
Transform();
// TODO : 9. get bytes array from words array
for (int i = 0; i < SHA1_RESULT_UINT8; ++i)
{
_digest[i] = _h[i >> 2] >> (bitsOfByte * (3 - (i & 0x03))) & 0xFF;
}
}
用位运算来替代取模运算。
Transform成员函数
这个函数是这个算法的核心,基本上,散列算法都是分组来搞的,它们的步骤都是一样的,都要分组,补位,唯一不一样的就是这个Transform。
void Transform()
{
uint32_t alpha[SHA1_RESULT_UINT32];
uint32_t W[SHA1_OPERATION_CNT];
// TODO : 2. fill W[] (0 ~ 15)
for (int i = 0; i < SHA1_BLOB_UINT32; W[i] = _data[i], ++i) {}
// TODO : 3. fill W[] (16 ~ 79)
for (int i = SHA1_BLOB_UINT32; i < SHA1_OPERATION_CNT; W[i] = Expand(W, i), ++i) {}
// TODO : 4. fill A, B, C, D, E
for (int i = 0; i < SHA1_RESULT_UINT32; alpha[i] = _h[i], ++i) {}
// TODO : 5. operator round 80
for (int i = 0; i < SHA1_OPERATION_CNT; Round(alpha, W, i++)) {}
// TODO : 6. update H[]
for (int i = 0; i < SHA1_RESULT_UINT32; _h[i] += alpha[i], ++i) {}
}
完整代码
#include <iostream>
#include <string>
#include <cstring>
#include <functional>
#define SHA1_RESULT_BIT 160
#define SHA1_RESULT_UINT8 (SHA1_RESULT_BIT / 8) // 20
#define SHA1_RESULT_UINT32 (SHA1_RESULT_UINT8 / 4) // 5
#define SHA1_BLOB_BIT 512
#define SHA1_BLOB_UINT8 (SHA1_BLOB_BIT / 8) // 64
#define SHA1_BLOB_UINT32 (SHA1_BLOB_UINT8 / 4) // 16
#define SHA1_REST_BIT 448
#define SHA1_REST_UINT8 (SHA1_REST_BIT / 8) // 56
#define SHA1_REST_UINT32 (SHA1_REST_UINT8 / 4) // 14
#define SHA1_OPERATION_CNT 80
#define SHA1_ROUND_CNT 4
#define SHA1_ROUND_LEN (SHA1_OPERATION_CNT / SHA1_ROUND_CNT) // 20
class SHA1Digest
{
public:
SHA1Digest() : _byteCount(0)
{
Reset();
}
SHA1Digest(const void *input, size_t length) : SHA1Digest() {}
void Update(const void *input, size_t length)
{
const unsigned char *buff = reinterpret_cast<const unsigned char *>(input);
if (_countLow + (length << 3) < _countLow)
{
++_countHight;
}
_countLow += length << 3;
_countHight += length >> 29;
while (length--)
{
reinterpret_cast<unsigned char *>(&_data[0])[_byteCount++] = *buff++;
if (_byteCount == SHA1_BLOB_UINT8)
{
// TODO : 1. group 512-bits/64-bytes
BytesReverse(_data, SHA1_BLOB_UINT32);
Transform();
_byteCount = 0;
}
}
}
const unsigned char *DigestText()
{
Final();
return _digest;
}
std::string GetString(bool isUpcase = true)
{
const unsigned char *pstr = DigestText();
size_t length = GetSize();
// TODO : 10. get 40-chars string
return BytesToHex(pstr, length, isUpcase);
}
size_t GetSize()
{
return SHA1_RESULT_UINT8;
}
void Reset()
{
InitH();
_countLow = _countHight = 0;
_byteCount = 0;
std::memset(_data, 0, sizeof(_data));
std::memset(_digest, 0, sizeof(_digest));
}
private:
SHA1Digest(const SHA1Digest &) = delete;
SHA1Digest & operator = (const SHA1Digest &) = delete;
void Transform()
{
uint32_t alpha[SHA1_RESULT_UINT32];
uint32_t W[SHA1_OPERATION_CNT];
// TODO : 2. fill W[] (0 ~ 15)
for (int i = 0; i < SHA1_BLOB_UINT32; W[i] = _data[i], ++i) {}
// TODO : 3. fill W[] (16 ~ 79)
for (int i = SHA1_BLOB_UINT32; i < SHA1_OPERATION_CNT; W[i] = Expand(W, i), ++i) {}
// TODO : 4. fill A, B, C, D, E
for (int i = 0; i < SHA1_RESULT_UINT32; alpha[i] = _h[i], ++i) {}
// TODO : 5. operator round 80
for (int i = 0; i < SHA1_OPERATION_CNT; Round(alpha, W, i++)) {}
// TODO : 6. update H[]
for (int i = 0; i < SHA1_RESULT_UINT32; _h[i] += alpha[i], ++i) {}
}
void Final()
{
static unsigned int bitsOfByte = 8;
// TODO : 7. cover bit (1)
reinterpret_cast<unsigned char *>(&_data[0])[_byteCount++] = 0x80;
// TODO : 7. cover bit (000...000)
std::memset(reinterpret_cast<unsigned char *>(&_data[0]) + _byteCount, 0, SHA1_BLOB_UINT8 - _byteCount);
if (_byteCount > SHA1_REST_UINT8)
{
BytesReverse(_data, SHA1_BLOB_UINT32);
Transform();
std::memset(_data, 0, sizeof(_data));
}
BytesReverse(_data, SHA1_BLOB_UINT32);
// TODO : 8. add bits count
_data[14] = _countHight;
_data[15] = _countLow;
Transform();
// TODO : 9. get bytes array from words array
for (int i = 0; i < SHA1_RESULT_UINT8; ++i)
{
_digest[i] = _h[i >> 2] >> (bitsOfByte * (3 - (i & 0x03))) & 0xFF;
}
}
void InitH()
{
for (int i = 0; i < SHA1_RESULT_UINT32; _h[i] = H_INIT[i], ++i) {}
}
private:
uint32_t _h[SHA1_RESULT_UINT32];
uint32_t _data[SHA1_BLOB_UINT32];
uint32_t _countLow;
uint32_t _countHight;
uint32_t _byteCount;
unsigned char _digest[SHA1_RESULT_UINT8];
private:
static uint32_t H_INIT[SHA1_RESULT_UINT32];
static uint32_t K[SHA1_ROUND_CNT];
static std::function<uint32_t(uint32_t, uint32_t, uint32_t)> F[SHA1_ROUND_CNT];
static uint32_t S(uint32_t x, int n);
static uint32_t Expand(uint32_t W[], int i);
static void Round(uint32_t alpha[], uint32_t W[], int i);
public:
static std::string BytesToHex(const unsigned char *input, size_t length, bool isUpcase);
static void BytesReverse(uint32_t data[], size_t length);
};
uint32_t SHA1Digest::H_INIT[SHA1_RESULT_UINT32] =
{
0x67452301,
0xEFCDAB89,
0x98BADCFE,
0x10325476,
0xC3D2E1F0
};
uint32_t SHA1Digest::K[SHA1_ROUND_CNT] =
{
0x5A827999,
0x6ED9EBA1,
0x8F1BBCDC,
0xCA62C1D6
};
std::function<uint32_t(uint32_t, uint32_t, uint32_t)> SHA1Digest::F[SHA1_ROUND_CNT] =
{
[] (uint32_t x, uint32_t y, uint32_t z) -> uint32_t
{
return (x & y) | (~x & z);
},
[] (uint32_t x, uint32_t y, uint32_t z) -> uint32_t
{
return x ^ y ^ z;
},
[] (uint32_t x, uint32_t y, uint32_t z) -> uint32_t
{
return (x & y) | (x & z) | (y & z);
},
[] (uint32_t x, uint32_t y, uint32_t z) -> uint32_t
{
return x ^ y ^ z;
},
};
uint32_t SHA1Digest::S(uint32_t x, int n)
{
return (x << n) | (x >> (32 - n));
}
uint32_t SHA1Digest::Expand(uint32_t W[], int i)
{
return S((W[i - 3] ^ W[i - 8] ^ W[i - 14] ^ W[i - 16]), 1);
}
void SHA1Digest::Round(uint32_t alpha[], uint32_t W[], int i)
{
uint32_t & A = alpha[0];
uint32_t & B = alpha[1];
uint32_t & C = alpha[2];
uint32_t & D = alpha[3];
uint32_t & E = alpha[4];
uint32_t tmp = S(A, 5) + F[i / SHA1_ROUND_LEN](B, C, D) + E + W[i] + K[i / SHA1_ROUND_LEN];
E = D;
D = C;
C = S(B, 30);
B = A;
A = tmp;
}
std::string SHA1Digest::BytesToHex(const unsigned char *input, size_t length, bool isUpcase)
{
static const char *digitUpper = "0123456789ABCDEF";
static const char *digitLower = "0123456789abcdef";
const char *pstr = isUpcase ? digitUpper : digitLower;
std::string ret;
ret.reserve(length << 1);
for (unsigned int i = 0; i < length; ++i)
{
ret.push_back(pstr[(input[i] & 0xF0) >> 4]);
ret.push_back(pstr[input[i] & 0x0F]);
}
return ret;
}
void SHA1Digest::BytesReverse(uint32_t data[], size_t length)
{
static unsigned int bitsOfByte= 8;
for (unsigned int i = 0; i < length; ++i)
{
data[i] = ((data[i] >> (0 * bitsOfByte) & 0xFF) << (3 * bitsOfByte)) |
((data[i] >> (1 * bitsOfByte) & 0xFF) << (2 * bitsOfByte)) |
((data[i] >> (2 * bitsOfByte) & 0xFF) << (1 * bitsOfByte)) |
((data[i] >> (3 * bitsOfByte) & 0xFF) << (0 * bitsOfByte));
}
}
测试
测试可以用在线的网站散列一段字节序列,对应比较,我用的是Python中的hashlib库测试的。一定要测试非常长的字节序列。
总结
散列算法(MD5, SHA1, SHA2)的基本步骤都是一样的,参见前面;唯一不同的就是Transform。因此,这篇博客会长一些,以后再写类似的散列散发博客时,我就只会写不同的地方了。
参考: