一、进制
我们知道程序在计算机内部是以二进制的方式进行存储的,我们要想知道程序在计算机内部的存储,首先要明白二进制。这是程序存储最基本的形式,首先我们需要理解一下几个问题:
1、进制的概念?
2、计算机中为什么要用二进制?
3、为什么又会出现八进制、十六进制?
4、所有进制之间的转换?
进制的概念?
进制也就是进位制,是人们规定的一种进位方法。 对于任何一种进制—X进制,就表示某一位置上的数运算时是逢X进一位。 十进制是逢十进一,十六进制是逢十六进一,二进制就是逢二进一,以此类推,x进制就是逢x进位。进制数可以通过位置计数法来表示,通过位置计数法,每个数都有基数,位权和权值。
基数:X进制则基数为:0~X-1,如二进制的基数为0和1。
位权:对于n进制数,其位权是n的整数次幂。如十进制中123,1这个数的位权为:10^2=100,2这个数的位权为:10^1=10,3这个数的位权为:10^0=1。
权值:等于该数值乘以它所在位置的位权。如十进制中的123,1的权值为:1*10^2=100,2这个数的位权为:2*10^1=20,3这个数的权值为:3*10^0=3。计算机中为什么要用二进制?
计算机使用二进制是由它的内部物理结构所决定的,由于计算机内部都是由一个个门电路所构成,当计算机工作的时候,电路通电工作,于是每个输出端就有了电压。电压的高低通过模数转换即转换成了二进制:高电平是由1表示,低电平由0表示。也就是说将模拟电路转换成为数字电路。这里的高电平与低电平可以人为确定,一般地,2.5伏以下即为低电平,3.2伏以上为高电平。数据在计算机中以器件的物理状态表示,采用二进制数字系统,计算机处理所有的字符或符号也要用二进制编码来表示。为什么又会出现八进制、十六进制?
符合人类思维的是十进制,为什么计算机会出现八进制、十六进制?由于计算机只能存储二进制,但是大量的二进制不便于人们的阅读,所以需要用一种更简单的方式来表示。而2^3=8,2^4=16,3个二进制位就可以表示一个八进制,4个二进制可以转换成一个十六进制。所以出现了便于人们使用的八进制、十六进制。所有进制之间的转换?
(1)、八进制、十六进制、二进制————–>十进制
都是按权展开的多项式相加得到十进制的结果。
(2)、十进制————–>八进制、十六进制、二进制
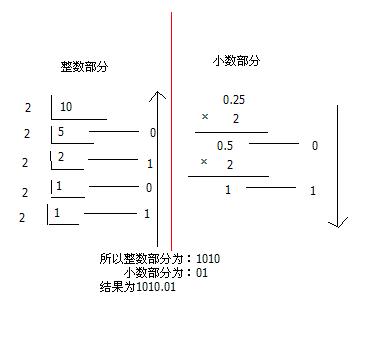
按照整数部分除以基数(r)取余,则它的r进制为余数结果的逆序,小数部分乘以基数(r)取整。如:十进制10.25 到二进制:整数部分除2,一步步取余。小数部分乘2,一步步取整。
(3)、二进制<————->八进制、十六进制
二进制到八进制可以每三位一组,小数点前面的不够三位的前面加0,小数点后面的不够三位的后面加0,然后写出每一组的对应的十进制数,顺序排列起来就得到所要求的八进制数了。
二进制到十六进制同样的道理每四位一组。
二、二进制能表达的含义
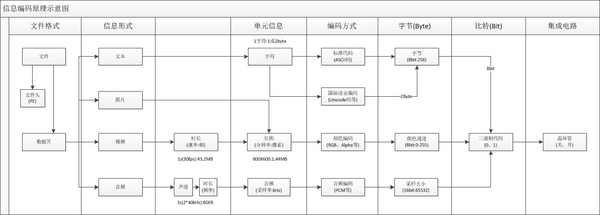
三、基本数据类型在计算机中的存储方式
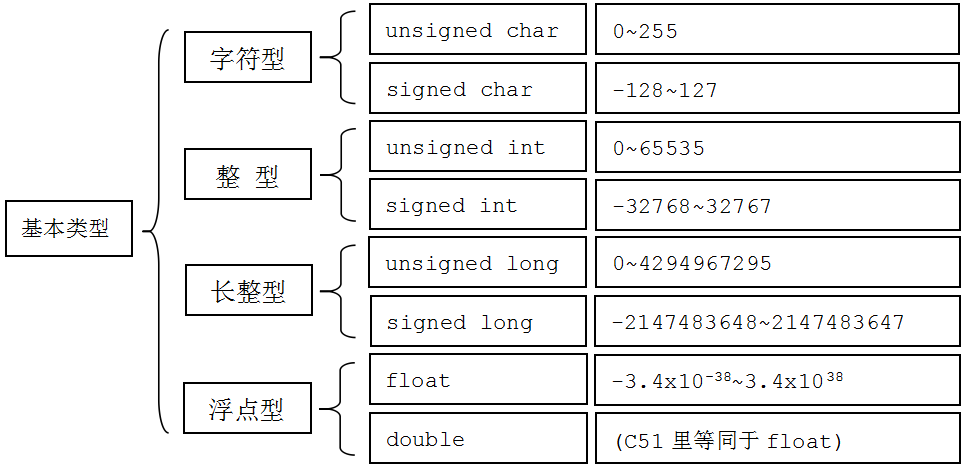
(1)、字符型
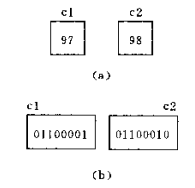
字符型是将相应的ASCII代码放到存储单元中。 例如字符’a’的ASCII代码为97,’b’为98,在内存中变量c1、c2的值如下图(a)所示,但数据在计算机内部是以二进制进行存储的,如(b)所示。
(2)、整形
- 补码
12的二进制表示为:0000 0000 0000 0000 0000 0000 0000 1100
-12的二进制表示为:1000 0000 0000 0000 0000 0000 0000 1100
则:12+(-12)为:1000 0000 0000 0000 0000 0000 0001 1000 十进制为:-24
为了防止出现这种错误,所以出现了补码。
因为:1111 1111 1111 1111 1111 1111 1111 1111+1=0;
所以:将负数转换成1111 1111 1111 1111 1111 1111 1111 1111 -负数的绝对值-1;
则:负数的补码计算方式是取绝对值的二进制,按位取反再加1
比如:-5这个数
先取绝对值,即5,即 00000000 00000000 00000000 00000101
然后按位取反:11111111 11111111 11111111 11111010
再加1:即 11111111 11111111 11111111 11111011
整数在计算机内部是以补码的形式来进行存储的,正整数的补码为它本身,负整数的补码最高位符号位保持不变,其他位取反再加一。
(3)、浮点型
首先我们看一个简单的程序:
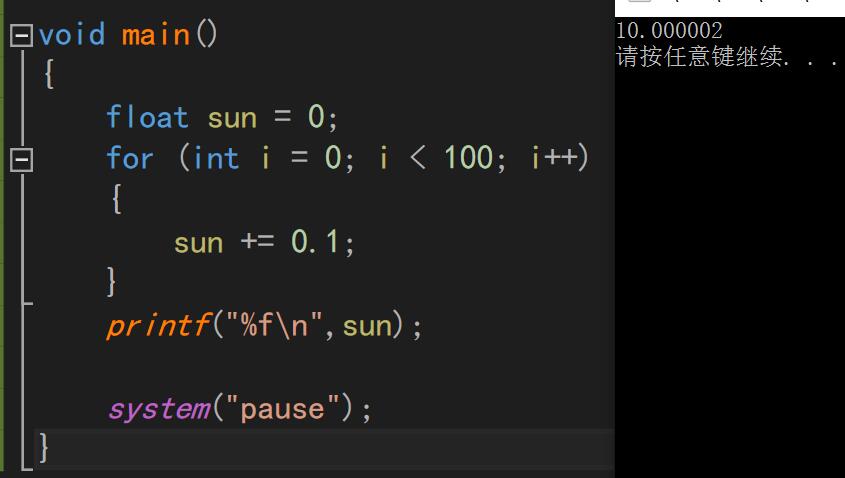
为什么结果会出现误差,这是由于浮点型的存储方式所影响的。
- 在 IEEE 标准中,浮点数是将特定长度的连续字节的所有二进制位分割为特定宽度的符号域,指数域和尾数域三个域,其中保存的值分别用于表示给定二进制浮点数中的符 号,指数和尾数。这样,通过尾数和可以调节的指数(所以称为”浮点”)就可以表达给定的数值了。浮点型中有两种,一种是4Byte的float型,一种是8Byte的double型,这两种计算方式相同,只是表示的精度不同而已。

float型是遵循IEEE R32.24规范,即1位符号位、8位阶码、23位尾数
- 计算方式:
- 符号位:先用科学计数法表示出该数的二进制,最高位一位表示符号,0为正,1为负。
- 阶码:这里阶码采用移码表示,对于float型数据其规定偏置量为127,阶码有正有负,对于8位二进制,则其表示范围为-128到127,double型规定为1023,其表示范围为-1024到1023。比如对于float型数据,若阶码的真实值为2,则加上127后为129,其阶码表示形式为10000010。偏差的引入使得对于单精度数,实际可以表达的指数值的范围就变成 -127 到 128 之间(包含两端)。我们不久还将看到,实际的指数值 -127(保存为 全 0)以及 +128(保存为全 1)保留用作特殊值的处理。这样,实际可以表达的有效指数范围就在 -127 和 127 之间。
- 尾数:有效数字位,即部分二进制位(小数点后面的二进制位),因为规定M的整数部分恒为1,所以这个1就不进行存储了。
比如:125.5这个数
先看整数部分,125表示成二进制是1111101,(整数转换二进制是除二取余)
再看小数部分,0.5表示成二进制是0.1,(小数转换二进制是乘二取整)
所以125.5用二进制表示就是1111101.1,转换成科学计数法就是1.1111011 x 2^6(阶数为6)
但是这里的阶码是用移码的形式表示,float型的偏置量是127,于是6+127=133,即10000101
这里前面的9位就出来了,因为是正数,所以符号位为0,阶码为10000101
后面的尾数就是1111011,在后面补0,凑齐23位,即 1111011 00000000 00000000(因为科学计数法的整数部分总是为1,所以,这个1不用存储)
所以125.5的存储方式为 0 10000101 11110110000000000000000
即: 01000010 11111011 00000000 00000000
*double型跟float型计算方式类似,不过区别在于double型遵循IEEE R64.53规范
a、double的符号位是1位,阶码为11位,尾数为52位
b、double的偏置量是1023,而float是127*