- 鉴于同步类容器的并效率和非同步类容器在处理并发问题需要手动加锁的繁琐操作,专门设计了并发类容器
- 使用coucurrentHashMap来代替传统的hashMap,以及使用CopyOnWriteArrayList代替Vector,并发copyOnWriteArraySet,以及并发的queue,如ConcurrentLinkQuue和LinkedBlockQueue。前者是高性能的队列,后者是阻塞队列。具体的queue还有很多:例如arrayBlockingQueue和PriorityBlockQueue和synchronizeQueue等
concurrentMap:concurrentMap有两个总要实现,concurrentHahMap和concurrentSkipListMap(支持并发排序功能,弥补concurrentHshMap),这两个容器类比于同步类容器的Vector和HashMap。
ConcurrentHashMap原理介绍:
concurrentHashMap之所以是并发容器,是因为他的内部使用段(sagment)来划分,每个段类似于一个小的hashMap。他们分别有自己的锁。只要修改操作不发生在同一端上,就可以并发进行。把一个整体分成16个段(sagement)。也就是最高支持16个线程的并发修改操作。这也是多线程场景时减小锁的粒度从而降低锁竞争的一种方案。并且代码中,大量的使用了volatitle关键字,目的是第一时间获取修改内容,性能非常好。
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
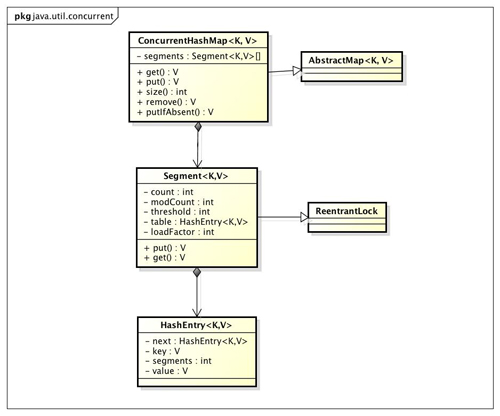
看下图中,将concurrentHashMap分成16个小段,每个小段类似于一个hashTable(同步类容器)。也就是说每个小段都是加锁的,并发类容器只是将锁的粒度变小了,这样可以有效缓解锁竞争问题,尽量减少多个线程争抢一把锁而导致cpu瞬间爆满的情况。
加入有5个线程要修改容器中的元素,1、 2、 3、 4 四个线程访问的是不同的段,那么他们各自拿到相对应的sagement段的锁,相互之间不受影响。但是如果几个线程访问的是用一段上的数据,那么就只有一个线程能进入修改,其他线程只能等待。也就是说并发类容器虽然支持并发类操作,但是如果并发量很大的话,也是需要耗时等待的,但是这相对于同步类容器,性能已经好太多了。

Copy-On-Write容器
种类:
Copy-On-Write容器容器简称COW容器,是一种用于优化程序的一种策略,JDK中分为两种,一种是CopyOnWriteArrayList和CopyOnWriteArraySet。
介绍:
copyOnWrite即写时复制容器。通俗的讲,就是当我像容器添加元素时,不直接添加,二是先将当前容器指向新的容器。这样做的好处就时我们可以对copyOnWrite容器进行并发的读,而不需要加锁,因为不会添加任何元素。所以copyOnwrite也是一种读写分离的思想。读和写在不同的容器。
我们看下面的图,当线程一想要修改容器内容的时候(写操作),CopyOnWrite容器会复制出来一个容器副本,然后让线程一去修改这个容器的副本,而不是修改原容器。这是指针依然指向原容器,在写的过程中,如果有其他线程向读容器的内容,这些线程就去原容器中获取数据。不需要加上任何锁,因为不对数据进行修改,不会出现数据问题。这样没有锁的读操作,性能当然是非常高的了。但是多个线程都需要修改容器的内容时,这就需要其他线程在容器外等待了,因为写操作是加锁的。

当写操作完成后,指针会指向容器的副本,原容器会被销毁,被垃圾回收器回收。后去再有线程读容器中的数据的话,就会读取副本这个容器中的内容了。
