区块数据同步分为被动同步和主动同步
被动同步是指本地节点收到其他节点的一些消息,然后请求区块信息。比如NewBlockHashesMsg
主动同步是指节点主动向其他节点请求区块数据,比如geth刚启动时的syning,以及运行时定时和相邻节点同步
被动同步
被动同步由fetcher完成,被动模式又分为两种
- 收到完整的block广播消息(NewBlockMsg)
- 收到blockhash广播消息(NewBlockHashesMsg)
NewBlockHashesMsg被动模式
由于NewBlockHashesMsg被动同步模式下和主动同步模式下都会请求其他节点并接收header和body,因此需要有相关逻辑区分是被动同步模式下请求的数据还是主动模式下请求的数据,这个区分是通过filterHeaders和filterBodies实现的。NewBlockHashesMsg这种模式下逻辑很复杂,我们一起来先看下这种模式下的流程源码
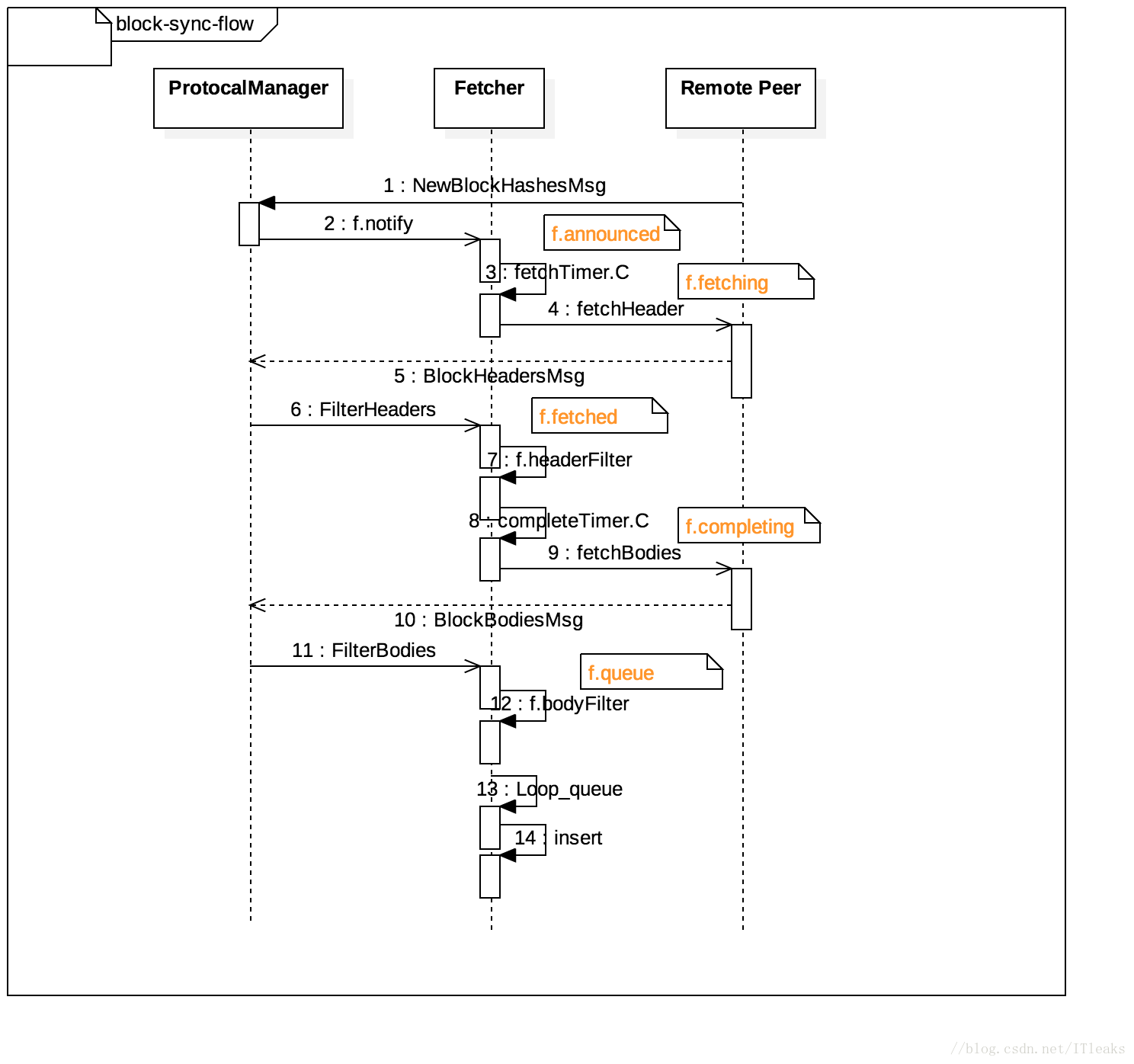
收到外部节点NewBlockHashesMsg消息,然后发送一个announce给fetcher
func (pm *ProtocolManager) handleMsg {
case msg.Code == NewBlockHashesMsg:
var announces newBlockHashesData
if err := msg.Decode(&announces); err != nil {
return errResp(ErrDecode, "%v: %v", msg, err)
}
// Mark the hashes as present at the remote node
for _, block := range announces {
p.MarkBlock(block.Hash)
}
// Schedule all the unknown hashes for retrieval
unknown := make(newBlockHashesData, 0, len(announces))
for _, block := range announces {
if !pm.blockchain.HasBlock(block.Hash, block.Number) {
unknown = append(unknown, block)
}
}
for _, block := range unknown {
pm.fetcher.Notify(p.id, block.Hash, block.Number, time.Now(), p.RequestOneHeader, p.RequestBodies)
}
}
func (f *Fetcher) Notify(peer string, hash common.Hash, number uint64, time time.Time,
headerFetcher headerRequesterFn, bodyFetcher bodyRequesterFn) error {
block := &announce{
hash: hash,
number: number,
time: time,
origin: peer,
fetchHeader: headerFetcher,
fetchBodies: bodyFetcher,
}
select {
//发送通知
case f.notify <- block:
return nil
case <-f.quit:
return errTerminated
}
}
fetcher收到announce会将其放置到announced[]数组
func (f *Fetcher) loop() {
case notification := <-f.notify:
// All is well, schedule the announce if block's not yet downloading
if _, ok := f.fetching[notification.hash]; ok {
break
}
if _, ok := f.completing[notification.hash]; ok {
break
}
f.announces[notification.origin] = count
f.announced[notification.hash] = append(f.announced[notification.hash], notification)
if f.announceChangeHook != nil && len(f.announced[notification.hash]) == 1 {
f.announceChangeHook(notification.hash, true)
}
if len(f.announced) == 1 {
f.rescheduleFetch(fetchTimer)
}
}
fetchTimer工作场景
-
f.announced的len=1,上面会调用f.rescheduleFetch,然后就会进入fetchTimer.C分支
- f.announced的len > 1,则它自身会不停的调用自己,知道将所有announce处理完毕
fetchTimer会将announce放置到f.fetching并调用fetchHeader请求其他节点获取header数据
func (f *Fetcher) loop() {
case <-fetchTimer.C:
// At least one block's timer ran out, check for needing retrieval
request := make(map[string][]common.Hash)
for hash, announces := range f.announced {
if time.Since(announces[0].time) > arriveTimeout-gatherSlack {
// Pick a random peer to retrieve from, reset all others
announce := announces[rand.Intn(len(announces))]
f.forgetHash(hash)
// If the block still didn't arrive, queue for fetching
if f.getBlock(hash) == nil {
request[announce.origin] = append(request[announce.origin], hash)
f.fetching[hash] = announce
}
}
}
// Send out all block header requests
for peer, hashes := range request {
// Create a closure of the fetch and schedule in on a new thread
fetchHeader, hashes := f.fetching[hashes[0]].fetchHeader, hashes
go func() {
if f.fetchingHook != nil {
f.fetchingHook(hashes)
}
for _, hash := range hashes {
headerFetchMeter.Mark(1)
fetchHeader(hash) // Suboptimal, but protocol doesn't allow batch header retrievals
}
}()
}
// Schedule the next fetch if blocks are still pending
//不停处理pending的fetch,直到announced的len=0
f.rescheduleFetch(fetchTimer)
}
func (f *Fetcher) rescheduleFetch(fetch *time.Timer) {
// Short circuit if no blocks are announced
if len(f.announced) == 0 {
return
}
// Otherwise find the earliest expiring announcement
earliest := time.Now()
for _, announces := range f.announced {
if earliest.After(announces[0].time) {
earliest = announces[0].time
}
}
fetch.Reset(arriveTimeout - time.Since(earliest))
}
其他节点返回header数据后,本地节点收到BlockHeadersMsg消息并处理
func (pm *ProtocolManager) handleMsg {
case msg.Code == BlockHeadersMsg:
// A batch of headers arrived to one of our previous requests
var headers []*types.Header
if err := msg.Decode(&headers); err != nil {
return errResp(ErrDecode, "msg %v: %v", msg, err)
}
// Filter out any explicitly requested headers, deliver the rest to the downloader
//被动请求情况下就是请求一条,所以这里filter=True
filter := len(headers) == 1
if filter {
// Irrelevant of the fork checks, send the header to the fetcher just in case
headers = pm.fetcher.FilterHeaders(p.id, headers, time.Now())
}
if len(headers) > 0 || !filter {
err := pm.downloader.DeliverHeaders(p.id, headers)
if err != nil {
log.Debug("Failed to deliver headers", "err", err)
}
}
}
func (f *Fetcher) FilterHeaders(peer string, headers []*types.Header, time
time.Time) []*types.Header {
log.Trace("Filtering headers", "peer", peer, "headers", len(headers))
// Send the filter channel to the fetcher
filter := make(chan *headerFilterTask)
select {
case f.headerFilter <- filter:
case <-f.quit:
return nil
}
// Request the filtering of the header list
select {
case filter <- &headerFilterTask{peer: peer, headers: headers, time: time}:
case <-f.quit:
return nil
}
// Retrieve the headers remaining after filtering
select {
//等待结果
case task := <-filter:
return task.headers
case <-f.quit:
return nil
}
}
headerFilterTask来执行filter任务,这里的代码有点特别,是将一个chan(filter)通道对象作为数据传递给另外一个chan(f.headerFilter)通道,并紧接着传headerFilterTask给filter, 同时会从filter读取返回值,类似双工的工作模式
func (f *Fetcher) loop() {
case filter := <-f.headerFilter:
// Headers arrived from a remote peer. Extract those that were explicitly
// requested by the fetcher, and return everything else so it's delivered
// to other parts of the system.
var task *headerFilterTask
select {
//获取任务
case task = <-filter:
case <-f.quit:
return
}
// Split the batch of headers into unknown ones (to return to the caller),
// known incomplete ones (requiring body retrievals) and completed blocks.
//检查是否已经存在对应的task
unknown, incomplete, complete := []*types.Header{}, []*announce{}, []*types.Block{}
for _, header := range task.headers {
hash := header.Hash()
// Filter fetcher-requested headers from other synchronisation algorithms
if announce := f.fetching[hash]; announce != nil && announce.origin == task.peer && f.fetched[hash] == nil && f.completing[hash] == nil && f.queued[hash] == nil {
// Only keep if not imported by other means
if f.getBlock(hash) == nil {
announce.header = header
announce.time = task.time
// If the block is empty (header only), short circuit into the final import queue
if header.TxHash == types.DeriveSha(types.Transactions{}) && header.UncleHash == types.CalcUncleHash([]*types.Header{}) {
log.Trace("Block empty, skipping body retrieval", "peer", announce.origin, "number", header.Number, "hash", header.Hash())
block := types.NewBlockWithHeader(header)
block.ReceivedAt = task.time
complete = append(complete, block)
f.completing[hash] = announce
continue
}
// Otherwise add to the list of blocks needing completion
incomplete = append(incomplete, announce)
} else {
log.Trace("Block already imported, discarding header", "peer", announce.origin, "number", header.Number, "hash", header.Hash())
f.forgetHash(hash)
}
} else {
// Fetcher doesn't know about it, add to the return list
unknown = append(unknown, header)
}
}
select {
//返回数据
case filter <- &headerFilterTask{headers: unknown, time: task.time}:
case <-f.quit:
return
}
// Schedule the retrieved headers for body completion
for _, announce := range incomplete {
hash := announce.header.Hash()
if _, ok := f.completing[hash]; ok {
continue
}
f.fetched[hash] = append(f.fetched[hash], announce)
if len(f.fetched) == 1 {
f.rescheduleComplete(completeTimer)
}
}
// Schedule the header-only blocks for import
for _, block := range complete {
if announce := f.completing[block.Hash()]; announce != nil {
f.enqueue(announce.origin, block)
}
}
}
上面代码对远端传递过来的header检验是否在f.fetching里(被动获取模式下,应该在f.fetching里面),并判读是否获取body,如果不需要继续获取body则将announce放到complete,并将数据enqueue到queued。否则将将announce放置到fetched,并请求body.
对于需要继续请求body的,会到达completeTimer.C
func (f *Fetcher) loop() {
case <-completeTimer.C:
// At least one header's timer ran out, retrieve everything
request := make(map[string][]common.Hash)
for hash, announces := range f.fetched {
// Pick a random peer to retrieve from, reset all others
announce := announces[rand.Intn(len(announces))]
f.forgetHash(hash)
// If the block still didn't arrive, queue for completion
if f.getBlock(hash) == nil {
request[announce.origin] = append(request[announce.origin], hash)
//放置到completing里
f.completing[hash] = announce
}
}
// Send out all block body requests
for peer, hashes := range request {
log.Trace("Fetching scheduled bodies", "peer", peer, "list", hashes)
// Create a closure of the fetch and schedule in on a new thread
if f.completingHook != nil {
f.completingHook(hashes)
}
bodyFetchMeter.Mark(int64(len(hashes)))
//请求body
go f.completing[hashes[0]].fetchBodies(hashes)
}
// Schedule the next fetch if blocks are still pending
f.rescheduleComplete(completeTimer)
completeTimer.C会将请求放到f.completing,以在后面的逻辑里匹配数据
Boy回来时本地会收到BlockBodiesMsg
func (pm *ProtocolManager) handleMsg {
case msg.Code == BlockBodiesMsg:
// A batch of block bodies arrived to one of our previous requests
var request blockBodiesData
if err := msg.Decode(&request); err != nil {
return errResp(ErrDecode, "msg %v: %v", msg, err)
}
// Deliver them all to the downloader for queuing
trasactions := make([][]*types.Transaction, len(request))
uncles := make([][]*types.Header, len(request))
for i, body := range request {
trasactions[i] = body.Transactions
uncles[i] = body.Uncles
}
// Filter out any explicitly requested bodies, deliver the rest to the downloader
filter := len(trasactions) > 0 || len(uncles) > 0
//同样是filter模式,所以不会在下面走pm.downloader.DeliverBodies
if filter {
trasactions, uncles = pm.fetcher.FilterBodies(p.id, trasactions, uncles, time.Now())
}
if len(trasactions) > 0 || len(uncles) > 0 || !filter {
err := pm.downloader.DeliverBodies(p.id, trasactions, uncles)
if err != nil {
log.Debug("Failed to deliver bodies", "err", err)
}
}
}
func (f *Fetcher) FilterBodies(peer string, transactions [][]*types.Transaction, uncles [][]*types.Header, time time.Time) ([][]*types.Transaction, [][]*types.Header) {
log.Trace("Filtering bodies", "peer", peer, "txs", len(transactions), "uncles", len(uncles))
// Send the filter channel to the fetcher
filter := make(chan *bodyFilterTask)
select {
case f.bodyFilter <- filter:
case <-f.quit:
return nil, nil
}
// Request the filtering of the body list
select {
case filter <- &bodyFilterTask{peer: peer, transactions: transactions, uncles: uncles, time: time}:
case <-f.quit:
return nil, nil
}
// Retrieve the bodies remaining after filtering
select {
case task := <-filter:
return task.transactions, task.uncles
case <-f.quit:
return nil, nil
}
}
func (f *Fetcher) loop() {
case filter := <-f.bodyFilter:
// Block bodies arrived, extract any explicitly requested blocks, return the rest
var task *bodyFilterTask
select {
case task = <-filter:
case <-f.quit:
return
}
bodyFilterInMeter.Mark(int64(len(task.transactions)))
blocks := []*types.Block{}
for i := 0; i < len(task.transactions) && i < len(task.uncles); i++ {
// Match up a body to any possible completion request
matched := false
for hash, announce := range f.completing {
if f.queued[hash] == nil {
txnHash := types.DeriveSha(types.Transactions(task.transactions[i]))
uncleHash := types.CalcUncleHash(task.uncles[i])
if txnHash == announce.header.TxHash && uncleHash == announce.header.UncleHash && announce.origin == task.peer {
// Mark the body matched, reassemble if still unknown
matched = true
if f.getBlock(hash) == nil {
block := types.NewBlockWithHeader(announce.header).WithBody(task.transactions[i], task.uncles[i])
block.ReceivedAt = task.time
blocks = append(blocks, block)
} else {
f.forgetHash(hash)
}
}
}
}
if matched {
task.transactions = append(task.transactions[:i], task.transactions[i+1:]...)
task.uncles = append(task.uncles[:i], task.uncles[i+1:]...)
i--
continue
}
}
bodyFilterOutMeter.Mark(int64(len(task.transactions)))
select {
case filter <- task:
case <-f.quit:
return
}
// Schedule the retrieved blocks for ordered import
for _, block := range blocks {
if announce := f.completing[block.Hash()]; announce != nil {
f.enqueue(announce.origin, block)
}
}
}
}
FilterBodies和FilterHeader类似,就是检测其他节点发送回的body数据是不是我们被动请求的数据(在不在f.completing里面),符合条件的会放到f.queued里面,否则过滤掉
到这个点,请求body和不请求body两种情况下获得的数据都会通过f.enqueue放置到f.equed数组里,不是被动请求的header, body数据会放到downloader里
func (f *Fetcher) enqueue(peer string, block *types.Block) {
hash := block.Hash()
// Schedule the block for future importing
if _, ok := f.queued[hash]; !ok {
op := &inject{
origin: peer,
block: block,
}
f.queues[peer] = count
f.queued[hash] = op
f.queue.Push(op, -float32(block.NumberU64()))
if f.queueChangeHook != nil {
f.queueChangeHook(op.block.Hash(), true)
}
}
}
上面的filterBody执行完,fetcher.loop会进入下一次循环,这时f.queue不为空,就会接着处理这个数据并插入到主链
func (f *Fetcher) loop() {
// Iterate the block fetching until a quit is requested
fetchTimer := time.NewTimer(0)
completeTimer := time.NewTimer(0)
for {
// Import any queued blocks that could potentially fit
height := f.chainHeight()
//遍历f.queue
for !f.queue.Empty() {
op := f.queue.PopItem().(*inject)
if f.queueChangeHook != nil {
f.queueChangeHook(op.block.Hash(), false)
}
// If too high up the chain or phase, continue later
number := op.block.NumberU64()
//如果高度不连续,没法作为head,push回去以备后面用
if number > height+1 {
f.queue.Push(op, -float32(op.block.NumberU64()))
if f.queueChangeHook != nil {
f.queueChangeHook(op.block.Hash(), true)
}
break
}
// Otherwise if fresh and still unknown, try and import
hash := op.block.Hash()
if number+maxUncleDist < height || f.getBlock(hash) != nil {
f.forgetBlock(hash)
continue
}
//插入链作为头部
f.insert(op.origin, op.block)
}
}
}
func (f *Fetcher) insert(peer string, block *types.Block) {
hash := block.Hash()
// Run the import on a new thread
log.Debug("Importing propagated block", "peer", peer, "number", block.Number(), "hash", hash)
go func() {
//赋值done,表示这次被动block请求完成,然后会清楚这次请求的所有数据
defer func() { f.done <- hash }()
// If the parent's unknown, abort insertion
parent := f.getBlock(block.ParentHash())
if parent == nil {
log.Debug("Unknown parent of propagated block", "peer", peer, "number", block.Number(), "hash", hash, "parent", block.ParentHash())
return
}
// Quickly validate the header and propagate the block if it passes
switch err := f.verifyHeader(block.Header()); err {
case nil:
// All ok, quickly propagate to our peers
propBroadcastOutTimer.UpdateSince(block.ReceivedAt)
go f.broadcastBlock(block, true)
case consensus.ErrFutureBlock:
// Weird future block, don't fail, but neither propagate
default:
// Something went very wrong, drop the peer
log.Debug("Propagated block verification failed", "peer", peer, "number", block.Number(), "hash", hash, "err", err)
f.dropPeer(peer)
return
}
// Run the actual import and log any issues
if _, err := f.insertChain(types.Blocks{block}); err != nil {
log.Debug("Propagated block import failed", "peer", peer, "number", block.Number(), "hash", hash, "err", err)
return
}
// If import succeeded, broadcast the block
propAnnounceOutTimer.UpdateSince(block.ReceivedAt)
//向其他节点广播新block
go f.broadcastBlock(block, false)
// Invoke the testing hook if needed
if f.importedHook != nil {
f.importedHook(block)
}
}()
}
func (f *Fetcher) loop() {
case hash := <-f.done:
// A pending import finished, remove all traces of the notification
f.forgetHash(hash)
f.forgetBlock(hash)
}
Fetcher.insert检测block的合法性,通过验证后即插入主链并向外广播
总结:
fetch请求一个block的数据,中间会经历很多过程,并维护了一个状态机,利用这个状态机可以区分其他节点返回回来的body和header是不是这次请求的返回数据.这个状态机的转换伴随着block信息推进到不同的变量,具体流程如下:
f.announced->f.fetching->f.fetched->f.completing->f.queue
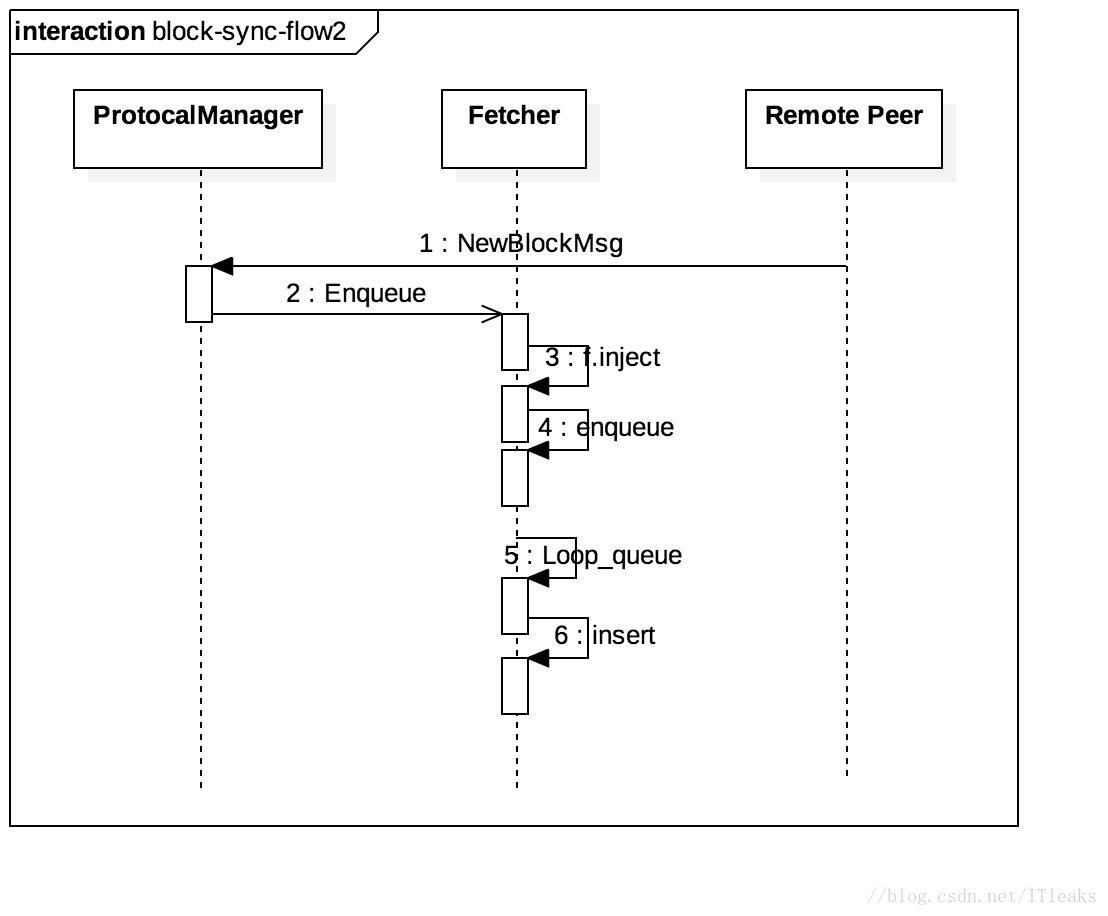
NewBlockMsg被动模式
这个代码逻辑相对简单,就不分析源码了,大家可以结合下面的时序图自己看看