一、Spark Streaming 简述
- Spark Streaming是一个构建在Spark之上,是Spark四大组件之一
- 是Spark系统中用于处理流式数据的分布式流式处理框架
- 具有可伸缩、高吞吐量、容错能力强等特点。
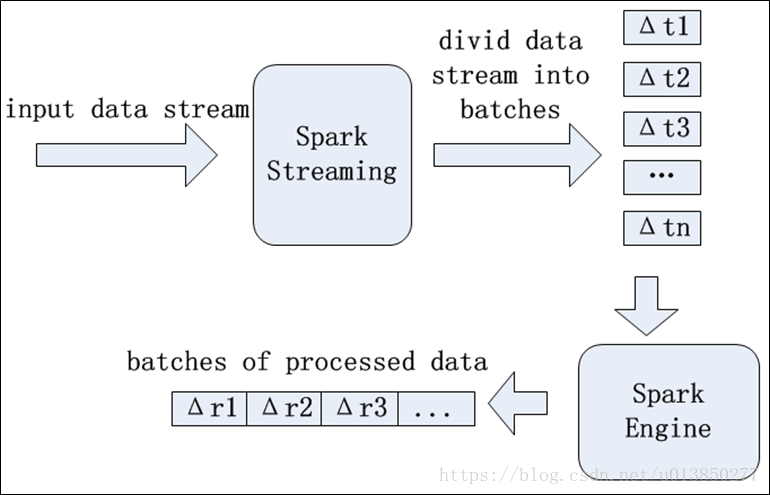
- 处理的数据源可以来自Kafka,Flume,Twitter,ZeroMQ,Kinesis or TCP sockets等,结果集可保存到HDFS、数据库或者实时Dashboard展示,如下图所示

二、Spark Streaming运行原理简述
- Spark Streaming的输入数据按照时间片(batch size)分成一段一段的数据,得到批数据(batch data),每一段数据都转换成Spark中的RDD,然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中的RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加或者存储到外部设备。
三、Spark Streaming编程样例
启动spark-shell
完整代码如下:
import org.apache.spark.streaming._
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(2))
val lines = ssc.socketTextStream("localhost",8888) // 监听本地8888端口的输入
// val lines = ssc.textFileStream("/tmp/testSparkStream") // 监听hdfs对应的目录
val words = lines.flatMap(_.split(" "))
val wordcount = words.map(x => (x,1)).reduceByKey(_ + _)
wordcount.print
ssc.start
ssc.awaitTermination()- 新开一个客户端,通过nc命令向8888端口传送数据
[root@dn02 ~]# nc -l 8888
who you are today
why you are here
why you are here结果:
18/08/18 09:22:30 WARN BlockManager: Block input-0-1533720150200 replicated to only 0 peer(s) instead of 1 peers
-------------------------------------------
Time: 1533720155000 ms
-------------------------------------------
(today,1)
(are,1)
(who,1)
(you,1)- 注:上述代码只会对指定时间片输入的数据流进行处理,并结果不会有叠加处理的操作。当然Spark Streaming是支持对结果进行叠加处理的。详细见下文。
四、SparkStreaming简单demo + Idea +maven环境搭建
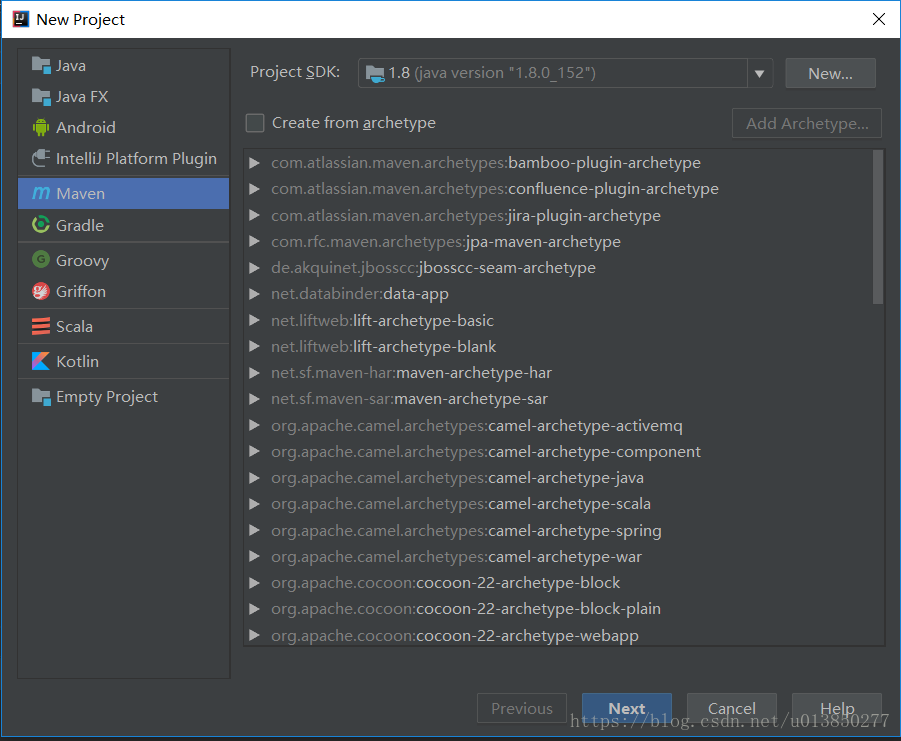
1、New一个maven项目,不用勾选archetype
2、将Sparkstream相关的jar通过maven添加到项目中
pom.xml见下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>SparkStream</groupId>
<artifactId>SparkStream</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>1.6.3</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
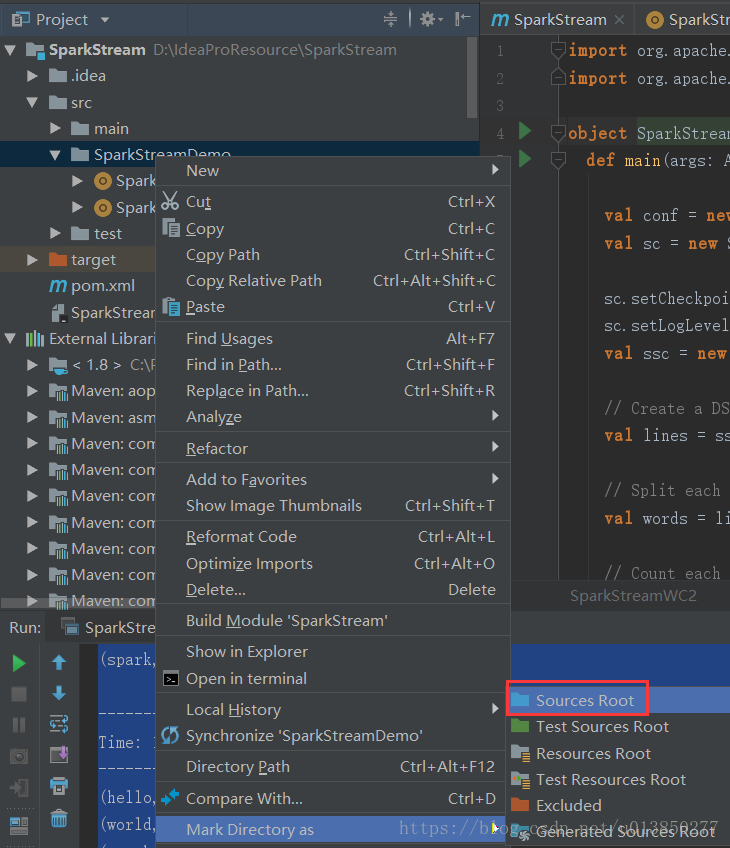
</project>3、将该项目Add Frameworks Support中选上关联scala包(选中项目,右键可见Add Frameworks Support )。新建SparkStreamDemo目录并设置其成source root,如下图
4、将官网(http://spark.apache.org/docs/1.6.3/streaming-programming-guide.html)上的代码copy整理后,如下
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamWC1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 默认为INFO输出的日志过多,因此将其设置成WARN
val ssc = new StreamingContext(sc, Seconds(5))
// Create a DStream that will connect to hostname:port, like localhost:8888
val lines = ssc.socketTextStream("10.xxx.xxx.xxx", 8888)
// Split each line into words
val words = lines.flatMap(_.split(" "))
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
}
}- 5、在服务器中开启nc命令并输入内容,两行内容间隔时间大于sparkStream处理的时间批次
[root@dn02 ~]# nc -lk 8888
hello world
hello hello spark spark
程序运行在IDEA中输出的结果如下:
Time: 1534410672000 ms
-------------------------------------------
(hello,1)
(world,1)
Time: 1534410676000 ms
-------------------------------------------
(hello,2)
(spark,2)- 上述例子是计算当前输入数据批次的,如下则为计算累加的样例代码
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamWC2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val sc = new SparkContext(conf)
sc.setCheckpointDir("D:\\\\checkpoint") // 如果是在集群中运行则需要给定hdfs目录
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc, Seconds(2))
// Create a DStream that will connect to hostname:port, like localhost:8888
val lines = ssc.socketTextStream("10.xxx.xxx.xxx, 8888)
// Split each line into words
val words = lines.flatMap(_.split(" "))
// Count each word in each batch
val pairs = words.map(word => (word, 1))
// 结果累加
val wordCounts = pairs.updateStateByKey(updateFunc, new HashPartitioner(sc.defaultParallelism), true)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
}
/**
* 函数
* Iterator[(String, Seq[Int], Option[Int])]
* String: 表示key
* Seq[Int]: 表示当前批次的value e.g:Seq(1,1,1,1,1,1)
* Option[Int]: 表示之前的累加值
*/
val updateFunc = (it: Iterator[(String, Seq[Int], Option[Int])]) => {
it.map(x => {
(x._1, x._2.sum + x._3.getOrElse(0))
})
}
}- 在服务器中开启nc命令并输入内容,两行内容间隔时间大于sparkStream处理的时间批次
[root@dn02 ~]# nc -lk 8888
hello world
hello hello spark spark
程序运行在IDEA中输出的结果如下:
Time: 1534411844000 ms
-------------------------------------------
(hello,1)
(world,1)
Time: 1534411846000 ms
-------------------------------------------
(hello,3)
(world,1)
(spark,2)
-------------------------------------------
Time: 1534411848000 ms
-------------------------------------------
(hello,3)
(world,1)
(spark,2)- 后续如果没有输入则会一直输出最终的结果
(hello,3)
(world,1)
(spark,2)